MidjourneyMidjourney是目前最强的AI绘画工具,输入提示词即可通过AI算法生成相对应的图片,只需要不到一分钟。对于新用户,官方提供一段时间的免费试用,用户可以直接通过谷歌账号注册体验。 08540AI绘画# AI绘画# Midjourney
LiblibAILiblibAI 是一家位于中国的 AI 图像生成平台,成立于 2023 年,为用户提供创建、分享和互动 AI 生成图像的工具。它基于开源的SD、Flux等模型,适合设计师、艺术家和内容创作者使用,提供文本到图像生成、图像操作和个性化模型训练等功能。02,5350AI绘画# AI绘画# Flux# LiblibAI
星流星流 AI是由LiblibAI平台推出的一站式AI图像生成解决方案,它基于Star-3 Alpha模型,致力于为用户提供高精度、多样化的图像生成服务。该平台特别适合电商、广告、设计等多个领域的需求,支持写实、插画、动漫等多种风格。02,2890AI绘画# AI 图像生成# LiblibA# 星流
夸克·造点AI阿里旗下的夸克团队推出了全新AI产品“造点”,该平台具备AI生成图像和视频的功能,用户输入想法即可生成独特的画面和动态视频,同时还拥有创意特效玩法。02,0970AI绘画# Midjourney V7# 夸克# 通义万相2.2
Reve ImageReve Image在人像和设计排版方面表现尤为出色,能够精准地根据用户输入的文本生成高质量的图像,同时也支持图生图功能,为创意工作者和普通用户提供了强大的工具。01,7090AI绘画# AI绘画# Reve AI# Reve Image
RunningHubRunningHub 是一个云平台,让用户轻松开发和分享 AI 应用。它特别适合那些希望通过浏览器直接操作的创作者,无需复杂的本地设置。平台基于 ComfyUI 工作流,提供强大的 GPU 云计算支持,确保高效任务执行。01,5710AI绘画# ComfyUI# ComfyUI工作流# RunningHub
可灵 AI可灵 AI(Kling AI)是一款创新的 AI 工具,专注于帮助用户快速生成高质量的图片和视频。它由快手团队开发,基于自研的可灵大模型和可图大模型,提供多样化的创作功能,特别适合内容创作者和市场营销人员。09890AI视频# AI绘画# AI视频# 可灵 1.6
即梦AI即梦AI 通过强大的 AI 功能和灵活的会员服务体系,为创作者提供了一站式的创意解决方案。无论是图片生成、视频创作还是故事讲述,即梦AI 都能够帮助用户快速实现创意,提升创作效率。05760AI视频# AI绘画# AI视频# 即梦AI
海螺视频海螺视频凭借其强大的 AI 技术和创新功能,为创作者提供了一个简单、高效且充满想象力的创作平台。无论是文字描述还是图片输入,海螺视频都能将你的创意转化为令人惊叹的视觉作品。06640AI视频# AI视频# MiniMax# 主体参考
SoraOpenAI于2024年2月公开了其AI视频生成(文生视频)模型Sora,它可以创建长达 60 秒的视频,其中包含高度详细的场景、复杂的摄像机运动和具有生动情感的多个角色,但直到12月才正式上线。08220AI视频# OpenAI# Sora# 文生视频
Higgsfield AIHiggsfield AI平台支持文生图和图生视频,近期对图生视频功能进行了全面升级,专为追求高质量、风格化内容创作并渴望真正电影级操控的创意人士打造——无论是MV导演、商业片制作人、AI创作者,还是社交媒体叙事者。166,47110AI视频# Higgsfield AI# Higgsfield DoP I2V-01-preview# 图生视频
Fogsight (雾象)雾象是一款由大语言模型(LLM)驱动的动画引擎 agent 。用户输入抽象概念或词语,雾象会将其转化为高水平的生动动画。020,3721AI视频# Fogsight# 动画生成引擎# 大语言模型
Qwen ChatQwen Chat是阿里通义团队在海外市场推出了一款全新的AI助手,可以看作是通义千问的海外版,这款助手基于开源的Open WebUI框架开发而成。04,2310AI助手# Qwen Chat# 通义实验室# 阿里巴巴
GrokGrok是一款先进的对话式人工智能。Grok 旨在提供高效、准确且自然的对话交互体验,适用于多种应用场景,包括客户服务、虚拟助手、教育辅导等。01,5960AI助手# DeepSearch# Grok# Grok 3
ChatGPTChatGPT 是一个由 OpenAI 开发的 AI 聊天机器人,可以生成类似人类的对话回应。它基于 GPT系列模型,于 2022 年 11 月 30 日首次发布。ChatGPT 可以执行多种任务,包括回答问题、编写代码、创作音乐和起草电子邮件,这使其成为一个多功能的AI工具。06050AI助手# AI助手# AI聊天机器人# ChatGPT
ClaudeAnthropic 的 Claude 系列模型在推理和编程方面表现出色,尤其是 Claude 3.7 Sonnet,它结合了推理模式和传统模式,提供了更灵活的使用体验。Claude虽然在某些方面优于竞争对手,但目前对中国用户不够友好,经常出现封号问题。04510AI助手# AI 聊天机器人# Anthropic# Claude
GeminiGemini(前称:Bard)是由谷歌开发的生成式 AI 聊天机器人,旨在应对 OpenAI 的 ChatGPT 而开发。它基于同名的 Gemini 系列大型语言模型,并经历了多次技术升级和功能扩展05870AI助手# AI 聊天机器人# Gemini# 谷歌
DeepSeekDeepSeek 的出现标志着中国在AI领域的一次重要突破,其推出的推理模型 DeepSeek-R1 不仅引发了全球关注,还对技术、政治和财经领域产生了深远影响。04920AI助手# DeepSeek# DeepSeek-R1# 大语言模型
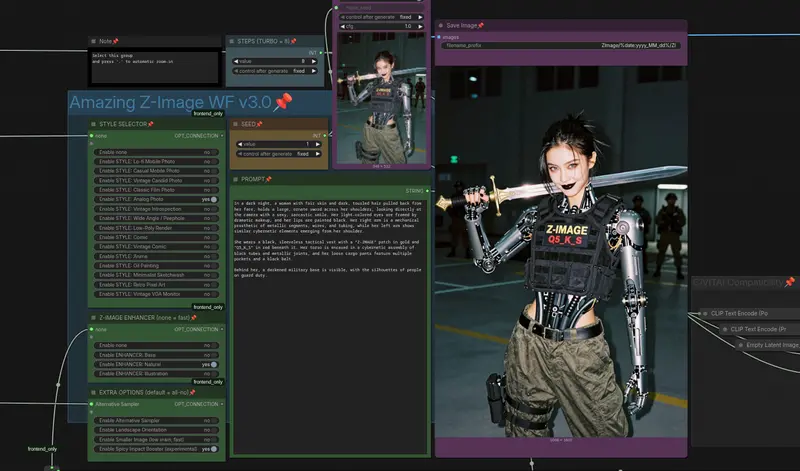
Amazing Z-Image Workflow v3.0:为 Z-Image-Turbo 优化的 ComfyUI 高质量图像生成工作流工作流# Amazing Z-Image Workflow# Z-Image-Turbo3周前01110
Gemini CLI谷歌正式发布 Gemini CLI —— 一个开源的 AI 工作流工具,将 Google Gemini 的强大能力带入你的终端,帮助你更快地理解代码、生成内容、执行任务,甚至自动化复杂的开发流程。04110AI编程# Gemini CLI# 命令行工具# 谷歌
Claude Code Claude Code 是一款代理编码工具,运行于您的终端,能够理解您的代码库,并通过自然语言命令帮助您更快地编码,执行日常任务,解释复杂代码,并处理 Git 工作流程。04660AI编程# AI编程# Claude Code
CursorCursor 是一个 AI 驱动的代码编辑器,通过智能功能帮助开发者更高效地工作。它基于 Visual Studio Code(VS Code)开发,继承了 VS Code 的扩展生态系统,同时融入了先进的 AI 能力,如自动补全、代码生成和代码库聊天等。这些功能让开发者可以更轻松地编写、编辑和调试代码,尤其适合需要处理复杂代码库的项目。05420AI编程# AI编程# Cursor
GitHub CopilotGitHub Copilot 是由微软旗下GitHub开发的一款AI编程工具,旨在帮助开发者更高效地编写代码。通过与主流集成开发环境(IDE)的深度集成,Copilot 提供了强大的代码补全、聊天辅助和上下文感知功能,显著提升了开发者的生产力和满意度。04590AI编程# AI编程# GitHub Copilot# 微软
TraeTrae与 AI 深度集成,提供智能问答、代码自动补全以及基于 Agent 的 AI 自动编程能力。使用 Trae 开发项目时,你可以与 AI 灵活协作,提升开发效率。05180AI编程# AI IDE# AI编程# AI编辑器
秒哒百度秒哒,由百度智能云倾力打造的国内首个“对话式”应用开发平台,正式全量上线。作为一款无代码工具,秒哒致力于让每个人都能通过自然语言描述需求,自动生成完整功能代码,轻松实现创意想法。05,1170AI编程# AI编程# 无代码# 百度
1步顶100步!TwinFlow让Qwen-Image、Z-Image推理提速100倍,无需判别器或教师模型图像模型# TwinFlow# TwinFlow-Qwen-Image# TwinFlow-Z-Image-Turbo4周前0810
DiffRhythm(谛韵)DiffRhythm(中文名“谛韵”)是由西北工业大学音频、语音与语言处理研究组(ASLP Lab)和香港中文大学(深圳)深圳大数据研究院联合开发的新型端到端全长度歌曲生成模型。基于潜扩散(Latent Diffusion)技术,DiffRhythm 能够快速生成包含人声和伴奏的完整歌曲,解决了现有音乐生成方法的诸多局限性。03,2370AI音乐# AI歌曲# AI音乐# DiffRhythm
MurekaMureka是昆仑万维的一款出海产品,这是一款AI歌曲生成器,让您可以轻松创建个性化的曲目,涵盖流行、电音、嘻哈、爵士等多种流派。它不仅支持多种音乐流派和语言,还提供了独特的定制功能,确保用户能够创作出符合自己独特品味的音乐。08500AI音乐# AI音乐# Mureka# Mureka O1
Flux Kontext Makeup Remover Flux Kontext Makeup remover是一个专注于为浓妆女子卸妆的LoRA,基于 FLUX.1-Kontext-dev 模型进行训练,将真实人物的浓妆卸去。
Fix JPEG artifacts compression lora Fix JPEG artifacts compression lora是一款基于图像编辑模型Flux Kontext开发的微调LoRA模型,此模型是用来修复JPEG压缩伪影。
Kontext-Emoji-LoRA Kontext-Emoji-LoRA是一个用于风格迁移的模型,基于FLUX.1-Kontext-dev 训练,适用于人类形象的emoji风格化任务,可在 ComfyUI 中使用。
kontext-make-person-real kontext-make-person-real 是一个针对FLUX.1-Kontext-dev 的小型但高效的 LoRA,专注于提升 AI 生成人物图像的真实感。如果你在使用 SDXL 或 FLUX 时常常遇到人物面部“AI 感”过重的问题,这个 LoRA 值得一试。
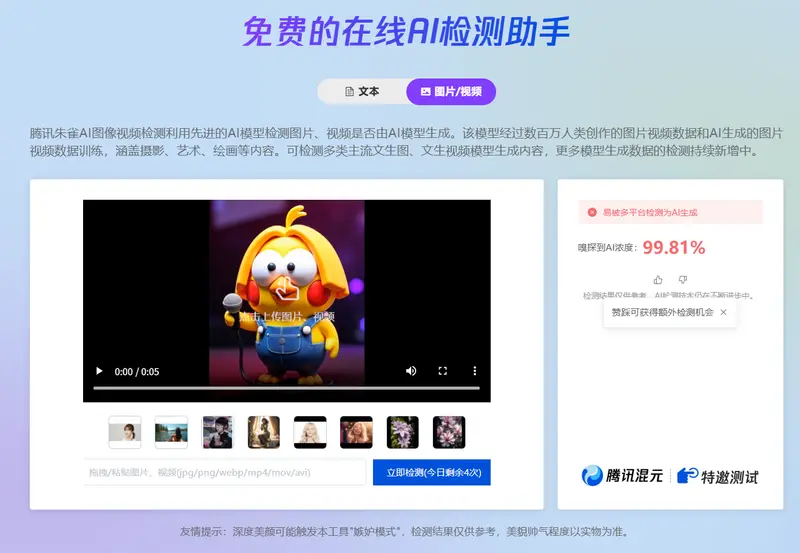
朱雀大模型检测腾讯朱雀 AI 检测是于 2025 年 1 月 17 日推出的一款 AI 生成内容检测工具,主要用于帮助用户识别 AI 生成的文本和图像内容。每位用户每天最多可检测20次文本和20次图片。218,5953AI工具# AI生成图像检测# AI生成文本检测# 朱雀大模型检测
NotebookLMNotebookLM是谷歌推出的一款个性化AI协作工具,旨在帮助用户更高效地进行信息整理和笔记记录。利用强大的语言模型帮助用户更快地从各种文本、图像以及网页中提取主要信息。01,4370AI工具# AI笔记# NotebookLM# 谷歌
YouMindYouMind 是一款重新构想的 AI 写作工具,帮助每个人轻松开启创作之旅。捕捉灵感、收集素材、撰写草稿,并将其转化为精炼的文章、播客、视频等丰富内容。01,2400AI工具# AI写作# YouMind# 知识管理
WeKnoraWeKnora 不只是一个 RAG 框架,更是面向真实业务场景的文档智能中枢。它解决了传统检索无法理解语义、大模型容易“幻觉”的双重痛点,通过“精准召回 + 可控生成”的方式,让企业沉淀的知识真正“活起来”。01,2260AI工具# RAG# WeKnora# 维娜拉
DeepWiki Cognition Labs 推出了 DeepWiki,号称“涵盖所有 GitHub 代码库的免费百科全书”。只需将 GitHub 仓库 URL 中的 “github” 替换为 “deepwiki”,即可生成类似维基百科的详细文档页面,无需注册即可免费访问公共仓库的文档。01,1290AI工具# Cognition Labs# DeepWiki# Devin
MemUMemU 是一个开源的 AI 伴侣记忆框架,具有高准确性、快速检索和低成本的特点。它作为一个智能的“记忆文件夹”,能够适应不同的 AI 伴侣应用场景。通过 MemU,你可以构建真正记住你的 AI 伴侣。它们能够学习你的身份、关注点,并在每次互动中与你共同成长。07610AI工具# AI伴侣记忆框架# MemU
纳米AI搜索纳米AI搜索,简称纳米搜索,是360集团于2024年11月推出的基于大语言模型等多模态学习技术的搜索及内容创作工具,已发布Android、iOS和鸿蒙原生版本,并提供网页版、PC客户端。该产品支持文字、语音、拍照、视频等多种搜索方式。04,0760AI搜索# 360# 纳米AI搜索# 纳米搜索
WisPaperWisPaper 是由复旦大学团队自主研发的智能科研助手,专为学术研究人员打造,聚焦于搜文献➕读文献这一科研起点。平台集成了高质量 AI 学术搜索、智能文献翻译与总结功能,帮助用户精准获取、快速理解海量科研资料。01,9150AI搜索# WisPaper# 学术搜索引擎
WebsetsWebsets 是一款专为知识工作者设计的工具,能够帮助用户高效地查找符合特定标准的实体列表(如公司、人员、研究论文等)。根据基准测试,Websets 在复杂查询方面的表现远超谷歌,检索到的正确结果数量比谷歌多 20 倍以上。06890AI搜索# AI搜索# Exa# Websets
Perplexity AIPerplexity AI 是一个创新的AI搜索引擎,通过对话方式回答用户问题,提供总结性答案,并引用来源。它实时搜索互联网,确保信息最新,适合快速变化的主题,如新闻。06250AI搜索# AI搜索# Perplexity AI# 深度研究
Deep ResearchDeep Research 是一个功能全面、高效且注重隐私的研究工具,适用于各种场景下的快速深入研究。通过结合先进的 AI 模型、互联网搜索和本地知识库,它能够帮助用户在短时间内生成高质量的研究报告。05800AI搜索# AI搜索# Deep Research
KagiKagi是一个以用户隐私和搜索质量为核心的搜索引擎。它致力于提供无广告、无追踪的优质搜索体验,让用户能够专注于获取最佳信息,而不是被广告和追踪器干扰。Kagi 的目标是成为一个真正的搜索伙伴,帮助用户发现能够扩展他们知识的内容。05130AI搜索# AI搜索# Kagi# Kagi 搜索
NaturalReaderNaturalReader 是一款功能强大、易于使用的文本转语音工具,适合各种场景下的阅读需求。无论您是希望节省时间的学生、需要无障碍支持的读者,还是寻求高质量语音内容的创作者,NaturalReader 都能为您提供卓越的体验。02,6230AI语音# NaturalReader# TTS# 文本转语音
AI SpeakerAI Speaker 是一款基于微软 TTS 服务的在线文字转语音(TTS)工具,能够将文字即时转换为自然流畅的 语音,支持100多种语言和600多种AI语音。01,1931AI语音# AI Speaker# TTS# 微软
Fish AudioFish Audio是一款生成式AI文本转语音和语音克隆平台,允许用户上传15秒语音片段进行克隆,支持多种场景如故事讲述、广告和有声书。它与AWS、Google Cloud和Nvidia合作,确保技术兼容性。09340AI语音# Fish Audio# OpenAudio S1# TTS
ElevenLabsElevenLabs 成立于 2022 年,总部位于英国和波兰,致力于利用 AI 技术生成自然、富有表现力的语音。它的平台支持从文本到语音的转换、语音克隆和多语言配音,服务于各种需求。09000AI语音# AI语音# ElevenLabs# 语音克隆
Open Avatar ChatOpenAvatarChat 是一个功能强大且高度模块化的数字人系统,能够在单台 PC 上流畅运行,支持多模态交互。其开源特性为开发者提供了极大的自由度,可以根据具体需求进行定制和优化。09800AI数字人# Open Avatar Chat# 数字人# 阿里巴巴
星野APP星野APP是一款由MiniMax开发的AI伴侣应用,专为中国用户设计,旨在提供个性化的虚拟交互体验。用户可以通过星野APP创建自己的AI角色,定制其外貌、声音、性格和技能。09640AI数字人# AI伴侣# MiniMax# 星野APP
CaptionsCaptions利用先进的人工智能技术,让任何人都能通过几次简单的点击,使用手机制作出录音室品质的视频。无论是脚本编写、录制、编辑还是分享,Captions都能无缝支持您的每一个创作环节。05390AI数字人# AI视频# Captions# 数字人
慧播星百度慧播星平台推出的 高说服力数码主播依托文心大模型的剧本生成与多模驱动能力,这一技术实现了数码主播在表情、语气、动作及情绪转换上的超拟真表现,甚至超越传统真人主播体验。05120AI数字人# 慧播星# 数字人# 电商
WeCloneWeClone为我们提供了一个从聊天记录和声音创造数字分身的开源解决方案。它不仅能够模拟你的语言风格,还能复制你的声音,并将数字分身绑定到多个聊天平台上。04740AI数字人# WeClone# 微信# 数字分身
LemonSliceLemonSlice(前身为 Infinity AI)是一款视频生成平台,它允许用户仅需一张照片和一段脚本即可生成会说话的视频,适合营销专业人士、社交媒体内容创作者和 AI 电影制作者等。04030AI数字人# LemonSlice# 唇形同步# 对口型
Hitem3D Hitem3D由Math Magic开发,是一款基于专有高分辨率AI模型Sparc3D的3D生成工具。只需上传一张参考图像,即可即时生成行业领先品质的工作室级3D资产,极大降低了3D创作的门槛。这一突破性解决方案赋能游戏开发者、设计师和3D艺术家高效释放创意,加速从概念到部署的创作流程。017,70903D# 3D 生成# Hitem3D# Sparc3D
TripoTripo AI 是一家领先的 AI 驱动 3D 建模解决方案提供商,允许用户使用文本、单张图像、多张图像、涂鸦或视频等输入,快速创建高质量的 3D 模型和环境。014,43213D# 3D 建模# 3D模型# Tripo
MeshyMeshy 是一款非常适合初学者和专业用户的 3D 模型生成工具。无论是快速建模、3D 打印还是动画设计,它都能轻松应对。如果你对 3D 模型创建感兴趣,不妨试试 Meshy,让生成式 AI 为你的创意插上翅膀!02,20403D# 3D 模型# 3D生成# Meshy
Alpha3DAlpha3D 是一款尖端工具,旨在帮助用户轻松地将文本和 2D 图像转换为完全实现的 3D 模型。这款由生成式 AI 驱动的平台对于参与创建增强现实 (AR) 内容的人来说是天赐之物,因为它简化了传统上昂贵且复杂的 3D 模型创建过程。无需深入的 3D 建模专业知识或高级设计技能,Alpha3D 使数字资产的创建大众化,使其可供从专业人士到业余爱好者等广泛受众使用。090803D# 3D模型# 3D生成# Alpha3D
GenieGenie 是 Luma AI 推出的一款强大的文生 3D 模型工具,能够在极短时间内生成包含材质、四维网格重拓扑、可变多边形数量和所有标准格式的 3D 模型。它通过解析用户提供的文本描述,利用 AI 技术生成逼真的 3D 模型,并支持复杂的提示,用户可以指定颜色、材质和形状等属性。075203D# 3D模型# Genie# Luma AI
Claw Cloud RunClaw Cloud Run 是一个非常实用的在线开发平台,特别适合个人开发者和小型团队。它提供了丰富的开源项目支持、强大的免费资源,以及无需绑卡的便捷体验。无论是搭建个人项目、快速部署 AI 应用,还是作为开发测试环境,Claw Cloud Run 都能提供高效、稳定的解决方案。06300模型API# Claw Cloud# Claw Cloud Run# 阿里云
Google AI StudioGoogle AI Studio 是一个功能齐全的工具,特别适合希望快速构建和试验 AI 应用的开发者。其多模态支持、提示库和与 Gemini API 的无缝集成使其成为生成 AI 开发的有力平台。08,0270模型API# API# Gemini# Google AI Studio
MiniMax开放平台MiniMax 是一个多模态 AI 技术的领导者,其强大的计算能力和丰富的功能使其成为企业和开发者的重要工具。无论是文本生成、语音合成还是视频制作,MiniMax 都能提供高质量的解决方案,助力用户实现技术创新和商业价值的最大化。08150模型API# MiniMax# 海螺 AI# 海螺视频
火山方舟大模型服务平台方舟是火山引擎推出的大模型服务平台,为您提供模型的训练、推理、评测、精调等全流程服务,帮助您快速应用的模型服务。07830模型API# API# 火山引擎# 火山方舟大模型服务平台
2233.ai2233.ai提供了一个便捷、安全且经济实惠的解决方案,让用户能够体验到原生的ChatGPT Plus和Claude Pro服务。同时,通过合理选择网络工具和使用API等方式,也可以在一定程度上改善使用体验,避免常见的网络和账号问题。07700模型API# 2233.ai# ChatGPT# Claude
硅基流动硅基流动作为集合顶尖大模型的一站式云服务平台,致力于为开发者提供更快、更全面、体验更丝滑的模型 API,助力开发者和企业聚焦产品创新,无须担心产品大规模推广所带来的高昂算力成本。07110模型API# ChatBox# Cherry Studio# DeepSeek-R1
EdgeOne PagesEdgeOne Pages 是基于 Tencent EdgeOne 基础设施打造的全栈开发部署平台,提供从前端页面到动态 API 的无服务器部署体验,适用于构建营销网站、AI 应用等现代 Web 项目。通过边缘网络全球加速,确保应用获得快速、稳定的访问体验。05370服务托管# EdgeOne Pages# 腾讯云
CivitAICivitAI是一个AI图像及视频模型托管平台,主要聚焦于 AI 生成的图像、视频和模型。它为用户提供了一个空间,可以上传、分享和发现由特定数据集训练的自定义 AI 模型,这些模型可用于生成独特的内容,如图像、视频。05340服务托管# CivitAI# CivitAIArchives# Diffusion Arc
Arcenciel.ioArcenciel.io 是一个面向爱好者和发烧友的社区,提供数千个免费的高质量 Stable Diffusion 模型,其中大部分专注于动漫风格。02250服务托管# Arcenciel.io# Stable Diffusion# 动漫模型
ComfyDeployComfyDeploy 是团队使用 ComfyUI 和开发应用的最简单方式。我们通过让您的团队共享相同的自定义节点环境、模型和工作流程来实现这一点。02000服务托管# ComfyDeploy# ComfyUI
VMOS CloudVMOS Cloud 是一家专注于 Android 虚拟化技术 的云服务提供商,拥有 5 年以上 的底层系统定制与虚拟化研发经验。其核心产品为 云端 Android 真机环境,支持 Android 15(全球首发),并可在 三星、Google、Xiaomi、Oppo、vivo、Realme 等多品牌机型间自由切换。0370服务托管# VMOS Cloud
Open ASR 排行榜Open ASR 排行榜 对 Hugging Face Hub 上的语音识别模型进行排名和评估。我们报告平均 WER(字错误率)(⬇️ 越低越好)和 RTFx(实时因子)(⬆️ 越高越好),模型根据其平均 WER 从低到高进行排名。015,4020基准测试# Hugging Face# 语音识别
NOFXNOFX是一个基于 DeepSeek/Qwen AI 的加密货币期货自动交易系统,支持 Binance、Hyperliquid和Aster DEX交易所,多AI模型实盘竞赛,具备完整的市场分析、AI决策、自我学习机制和专业的Web监控界面。01,3610基准测试# NOFX# 加密货币
WebDev ArenaWebDev Arena 是一个实时的 AI编程竞赛平台,由 LMArena 开发,各种 AI代码模型在其中进行面对面的 Web 开发挑战。07980基准测试# AI编程# WebDev Arena# 网页开发
Artificial AnalysisArtificial Analysis 是一个专注于 AI 模型和提供商分析的网站,通过提供性能基准测试和区域性报告,帮助用户做出明智的选择。其内容覆盖广泛,包括语言模型、图像模型等,并特别关注全球AI趋势,如中国市场的动态。对于需要深入了解 AI 选项的用户,该网站是一个有用的工具,尤其是在性能比较和趋势分析方面。06780基准测试# AI模型# Artificial Analysis
MagicArenaMagicArena是字节跳动推出的一个采用Elo积分机制的视觉生成大模型公开对战平台。平台上有多个视觉生成大模型(文生图、文生视频、图生视频)随机两两对战,用户对生成的结果进行评价,累积定对战数据后可以查看自己的大模型排行榜。06220基准测试# Elo# MagicArena# 大模型
imgsysimgsys.org 是一个专注于开源文本引导图像生成模型的评估平台,通过用户偏好数据的收集和开源,推动图像生成领域的研究和开发。05130基准测试# Fal.ai# imgsys# 文生图模型
Kagi NewsKagi推出的AI新闻聚合站Kagi News,此站点基于一个简单原则:理解世界需要倾听世界的声音。每天,我们的系统阅读数千个社区精选的 RSS 源,这些源来自不同观点和视角的出版物。然后,我们使用 AI 将海量信息提炼成一份全面的每日简报,同时清楚地引用来源。01,7760爱学习# AI新闻# Kagi News
通往AGI之路《通往AGI之路》是一个由开发者、学者和有志之士共同参与的开源AI知识库与学习社区,旨在为人工智能(AI)的学习者、实践者和创新者提供全面的学习路径和资源支持。05830爱学习# AI知识库# WayToAGI# 通往AGI之路
OpenAI AcademyOpenAI Academy的上线,为全球AI教育注入了新的活力。通过提供免费、高质量的学习资源,OpenAI不仅让更多人有机会接触和学习AI,也为推动全球AI技术的发展和应用奠定了坚实的基础。04620爱学习# AI学习平台# ChatGPT# OpenAI
面向初学者的生成式 AI课程AI正在重塑各个行业,而生成式AI作为其最前沿的技术之一,正迅速成为开发者、创作者和企业关注的焦点。为了帮助更多人掌握这一技术,微软推出了全新的18集系列课程——“生成式AI入门”。03920爱学习# 微软# 生成式 AI
All RAG Techniques这个 RAG 学习资源库的目标非常明确:降低 RAG 学习门槛,提升理解深度。无论你是学生、研究人员还是工程师,都能在这里找到适合自己水平的实践材料。通过亲手实现每一个 RAG 技术,你将更深刻地理解其工作原理,并能灵活应用于实际项目中。03780爱学习# All RAG Techniques# RAG 技术学习资源库# 检索增强生成
Learn Your WayLearn Your Way 基于学习科学,并由 LearnLM 驱动,这是谷歌一流的注入教学法的模型家族,现在直接集成到 Gemini 2.5 Pro 中。它根据学习者选择的年级水平和个人兴趣调整内容,并基于源材料生成多种表示形式,从思维导图和音频课程到互动测验,这些功能支持实时反馈和进一步的内容个性化。它赋予学生对学习过程的自主权。03770爱学习# Learn Your Way# 教育# 谷歌
MinerUMinerU是一款功能强大、操作简单的文档解析工具。它不仅支持多种格式和导入方式,还能精准提取复杂元素,适用于多种场景。无论是学术研究、数据分析还是日常办公,MinerU都能为你带来流畅、准确的解析体验。在科研、学习和工作中,处理复杂文档格式一直是一个让人头疼的问题。无论是科技文献中的公式、表格,还是多语言扫描版PDF,传统工具往往难以满足高效、精准的解析需求。而今天要介绍的 MinerU,正是一款专为解决这些问题而生的免费文档解析神器。它不仅能精准提取复杂元素,还支持多种格式一键转换,适用于从机器学习到大模型语料生产的多种场景。 全格式兼容,轻松导入 MinerU 的一大亮点是其强大的格式兼容性。无论你的文档是 PDF、Word、PPT 还是图片,MinerU 都能轻松应对。通过简单的拖拽、截图或批量上传,你就可以快速将文件导入工具中,无需繁琐的操作。 支持格式:PDF、Word、PPT、图片等主流文档类型。 操作便捷:拖拽、截图、批量上传,一键完成导入。 智能识别:自动检测扫描版PDF和乱码PDF,并启用OCR功能,支持84种语言的检测与识别。 复杂元素精准提取 对于科技文献、学术论文等包含复杂排版的文档,MinerU 表现尤为出色。它能够精准定位并提取图表、公式等复杂元素,确保内容完整且语义连贯。 精准定位:自动识别文档中的图表、公式、表格等复杂元素,并进行精准提取。 结构保留:输出结果保留原文档的标题、段落、列表等结构,确保逻辑清晰。 多模态解析:支持图像描述、表格标题、脚注等内容的提取,适配多种使用场景。 多场景极速输出 MinerU 不仅擅长解析文档,还提供了丰富的输出格式选择,满足不同场景的需求。无论是用于机器学习训练、大模型语料生产,还是构建 RAG(检索增强生成)系统,MinerU 都能提供高效的解决方案。 多种输出格式: Markdown:适合多模态与NLP任务。 JSON:按阅读顺序排序,便于后续处理。 LaTeX:自动识别并转换公式,极大提升科研效率。 HTML:自动转换表格,方便网页展示。 可视化支持:提供 layout 可视化、span 可视化等功能,便于高效确认输出效果与质检。 技术亮点与性能优化 MinerU 在技术层面同样表现出色,兼顾了易用性与性能优化: 跨平台支持:兼容 Windows、Linux 和 Mac 平台,满足不同用户的设备需求。 硬件加速:支持纯 CPU 环境运行,同时可选 GPU(CUDA)、NPU(CANN)、MPS 加速,显著提升处理速度。 高精度 OCR:针对扫描版PDF和乱码文档,MinerU 内置高精度OCR功能,支持84种语言的检测与识别。 主要功能一览 MinerU 的核心功能覆盖了文档解析的方方面面,帮助用户高效完成复杂的文档处理任务: 删除冗余元素:自动移除页眉、页脚、脚注、页码等内容,确保输出文本语义连贯。 阅读顺序优化:输出符合人类阅读习惯的文本,无论是单栏、多栏还是复杂排版都能轻松应对。 公式与表格转换: 自动识别并转换公式为 LaTeX 格式。 自动识别并转换表格为 HTML 格式。 多语言支持:OCR 功能支持84种语言,满足国际化需求。 灵活输出:支持多种格式输出(Markdown、JSON、LaTeX、HTML 等),适配多种应用场景。 适用场景广泛 MinerU 的设计初衷是为了服务于科研和技术发展,但它的应用范围远不止于此。以下是一些典型的应用场景: 机器学习与大模型训练:将大量文档转化为高质量的训练数据,助力模型语料生产。 RAG 系统构建:为检索增强生成系统提供结构化数据支持。 学术研究:快速解析科技文献,提取关键信息,提升科研效率。 企业办公:批量处理合同、报告等文档,节省人工整理时间。 为什么选择 MinerU? 相比其他文档解析工具,MinerU 的优势在于其全面性和精准性。它不仅能够处理各种复杂文档,还能根据用户需求输出多样化的结果。更重要的是,MinerU 完全免费,且持续优化以解决科技文献中的符号转化问题,为大模型时代的技术进步贡献力量。04,5901实用工具# MinerU# PDF# 数据提取
人生 K 线人生 K 线(Life Destiny K-Line)是一个结合传统八字命理与现代大语言模型(LLM)的轻量级可视化工具。它将一个人从 1 岁到 100 岁的运势走势,以类似股票 K 线图的形式呈现,试图用数据可视化的方式“翻译”命理推演结果。03,7191AI小应用# AI算命# 人生 K 线
DrawAFish在 DrawAFish.com,每一次落笔都不只是涂鸦——它可能成为一条被AI识别、由算法验证、最终游进虚拟海洋的真实数字生命。这里没有复杂的操作门槛,只有一块画布、一个想法,和一群来自世界各地的创作者。01,6940AI小应用# AI画鱼# DrawAFish
FlyCut CaptionFlyCut Caption是一款智能、本地化的开源视频字幕裁剪工具,用智能字幕生成技术改变您的视频,自动生成准确字幕,精确编辑,支持多种格式导出。为内容创作者、教育工作者和企业提供完美解决方案。01,5310AI小应用# FlyCut Caption# 智能视频字幕裁剪工具
BabelDOCBabelDOC 是新一代智能 PDF 翻译工具,采用先进的排版保持技术,为您提供专业级的双语对照翻译体验。无论是前沿学术论文,还是商业分析报告,BabelDOC 都能帮您轻松跨越语言藩篱,同时完美呈现原文档的精致排版。01,3360实用工具# BabelDOC# PDF 翻译工具# 沉浸式翻译
Next AI Draw.ioNext AI Draw.io 是一个基于 Next.js 的 Web 应用,将大语言模型(LLM)与 draw.io 的强大图表能力深度集成。用户可通过自然语言指令创建、修改和增强专业图表,无需手动拖拽。01,2500AI小应用# draw.io# Next AI Draw.io# 大语言模型
GenUI - 最新版GenUI 是一款专为简化和增强使用 Stable Diffusion 生成图像而设计的桌面用户界面应用。它不仅提供了一个直观的界面,还将在未来的更新中带来更多新功能和增强体验,例如更详细的设置选项和改进的图像质量。
WarpTuber - 最新版WarpTuber 是一个基于快手 LivePortrait 技术的即时虚拟直播工具,允许用户通过网络摄像头将自己的脸部表情和动作实时映射到静态图像或视频上,为内容创作、虚拟化身和直播提供便利。
Diffusion Training Dataset Composer - 最新版Diffusion Training Dataset Composer是一款基于 PyQt5 的图形化界面工具,专为构建适用于 LoRA/DreamBooth 和微调任务的数据集而设计,支持高度定制化的设置、错误处理机制以及友好的用户体验,非常适合需要频繁构建训练样本的用户。
CosyVoice Desktop - 最新版CosyVoice Desktop 是一个完全本地运行的桌面端有声内容生成工具,基于 CosyVoice3-0.5B 大模型构建,无需联网、无需订阅,打开即用,支持多角色配音、语音修补、跨语言合成,并提供完整的项目管理与音频导出流程。
Superwhisper - 最新版Superwhisper 不只是一个语音转文字工具,而是一个语音优先的写作助手。它让创作从“敲键盘”变为“开口说”,特别适合需要快速记录、频繁写邮件、或希望减少重复输入的用户。
豆包输入法 - 最新版「豆包输入法」是字节跳动旗下推出的全新智能输入法,它深度集成「豆包」大模型的 AI 能力,核心亮点在于将高精度语音识别与上下文语义理解融入日常输入场景,尤其在语音输入体验上实现了显著突破。
Port Guard - 最新版Port Guard是一款轻量级、本地运行、无网络依赖的端口管理工具,专为开发者、运维和安全团队设计。支持 macOS、Windows、Linux,界面简洁,操作高效,让你一眼看清端口占用,一键释放进程。









































































































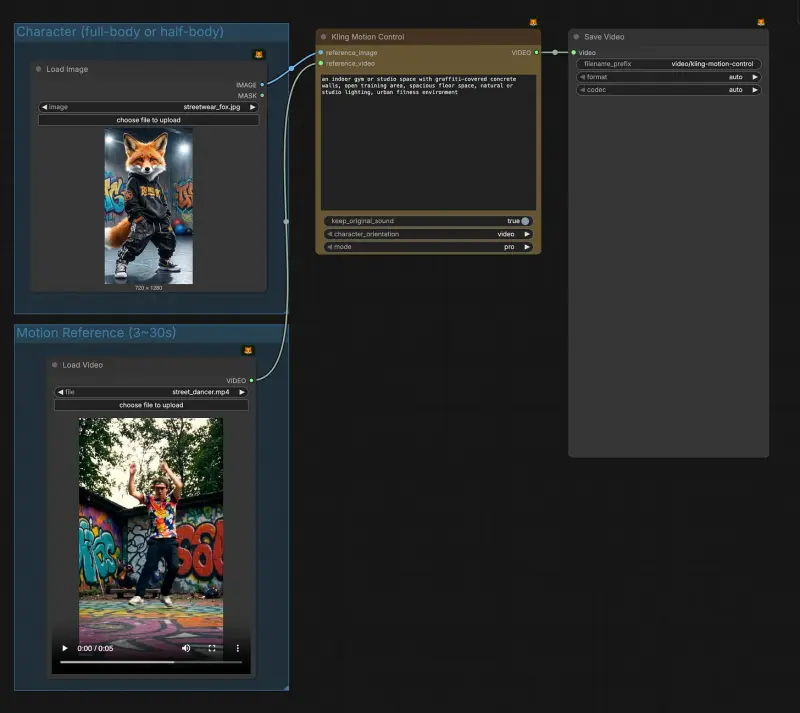
![ComfyUI已支持 FLUX.2 [klein]:4B 模型实现 1.2 秒本地图像生成与编辑](https://pic.sd114.wiki/wp-content/uploads/2026/01/1768500082-1768500082-FLUX.2-klein-4.webp~tplv-o4t1hxlaqv-image.image)
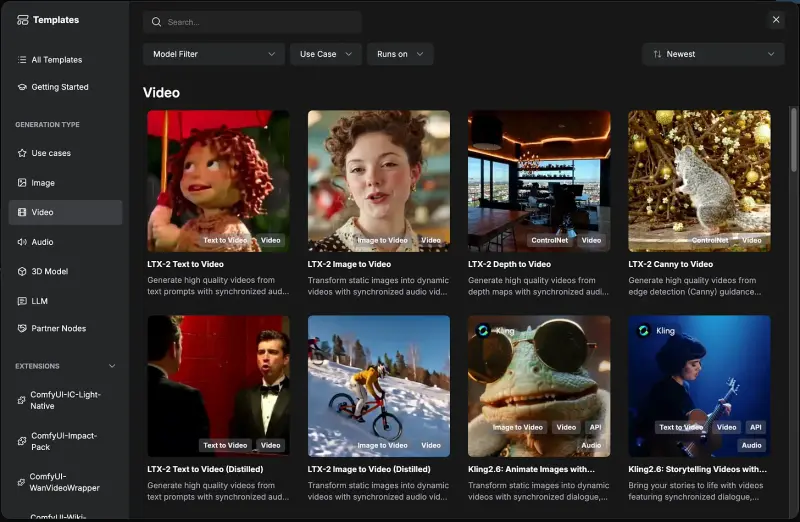



![黑森林实验室发布 FLUX.2 [klein]:统一生成与编辑的最快开源模型](https://pic.sd114.wiki/wp-content/uploads/2026/01/1768500030-1768500030-FLUX.2-klein-2.webp~tplv-o4t1hxlaqv-image.image)