Luma 发布统一推理图像模型UNI-1:终结“理解”与“生成”的割裂,首个统一推理视觉模型登场“过去的 AI 是‘先看懂,再画出来’的两个步骤;现在的 UNI-1 是‘边想边画,画即是想’的一个过程。” Luma AI 今日正式推出 UNI-1,这是业界首个将视觉理解与图像生成深度融合的统一推...图像模型早报# Luma# UNI-15天前0250
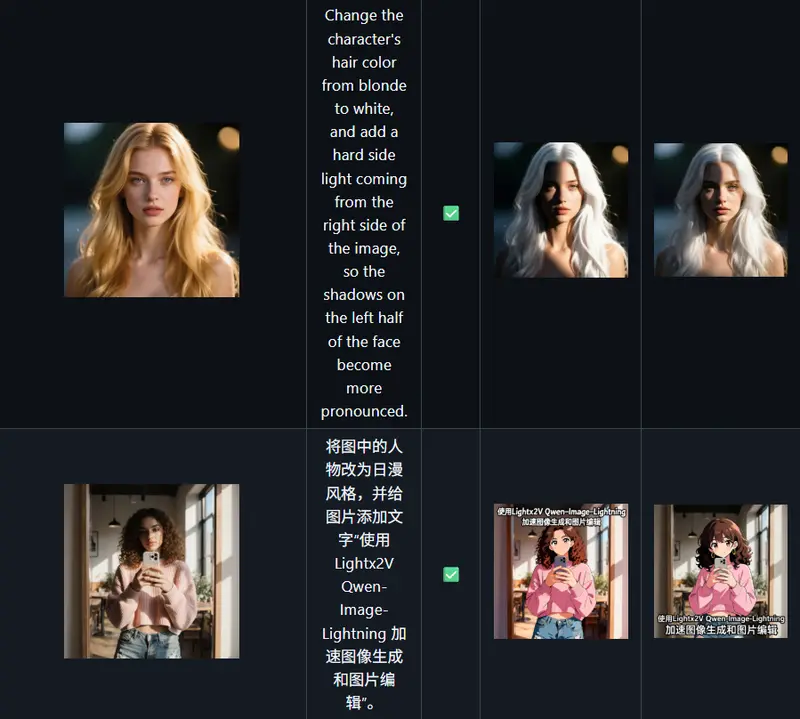
小红书开源FireRed-Image-Edit 1.1:引入智能体工作流,支持 10+ 元素融合与专业级人像精修小红书智能创作基础技术团队正式推出 FireRed-Image-Edit-1.1。作为前代通用图像编辑模型的升级版,1.1 版本在保留强大编辑能力的基础上,重点攻克了身份一致性、多图像复杂控制及领域专...图像模型# FireRed-Image-Edit 1.1# 小红书7天前0680
ImageCritic:AI 绘图的“细节质检员”,专治 Logo 变形与文字乱码的通用后处理方案在 AI 绘画飞速发展的今天,我们早已习惯了让模型根据文字描述创造出惊艳的画面,甚至能将特定的商品、宠物或角色无缝植入新场景。然而,一个长期存在的“老大难”问题始终困扰着专业应用:细节一致性。 当你试...图像模型# ImageCritic# 图像编辑1周前0300
谷歌发布 Nano Banana 2:融合 Flash 速度与 Pro 级画质,角色一致性高达 5 人谷歌今日正式推出了其最新图像生成模型 Nano Banana 2(技术代号:Gemini 3.1 Flash Image)。这款新模型旨在打破“速度”与“质量”不可兼得的魔咒,将 Gemini Fla...图像模型早报# Gemini 3.1 Flash Image# Nano Banana 2# 谷歌2周前0320
LoRWeB:AI 图像编辑新范式,只需“看一眼”就能学会任何修图技巧想象这样一个场景:你看到朋友的照片戴着一副酷炫的墨镜,效果极佳。你也想给自己的照片加上同款墨镜,但你既不会使用复杂的 Photoshop,也难以用文字精确描述“想要什么样的墨镜、戴在什么位置、光影如何...图像模型# LoRWeB# 图像编辑2周前0480
中国多所高校联合推出 DeepGen 1.0:50 亿参数小模型逆袭,图像生成与编辑能力媲美 800 亿巨无霸在AI领域,“大力出奇迹”似乎已成为一种默认法则:模型参数越大,效果越好。然而,由上海创智学院、复旦大学、中国科学技术大学、上海交通大学、浙江大学、西湖大学、南京大学以及南加州大学的研究人员共同推出的...图像模型# DeepGen 1.0# 多模态模型3周前0510
字节跳动开源 BitDance:14B 参数自回归模型,生成速度超越扩散模型 30 倍在 AI 绘画领域,长期存在着“画质”与“速度”的博弈,以及“扩散模型”与“自回归模型”的路线之争。扩散模型(如 Stable Diffusion)画质优异但推理步骤繁琐;自回归模型(类似 LLM 生...图像模型# BitDance# 字节跳动# 自回归模型3周前01690
Qwen-Image-Edit-Causal:用分块因果注意力加速图像编辑推理Light AI 近日发布了 Qwen-Image-Edit-Causal V1.0,这是对 Qwen-Image-Edit-2511 的一次关键优化。新模型通过引入 分块因果注意力(block ca...图像模型# Qwen-Image-Edit-2511# Qwen-Image-Edit-Causal3周前0490
图像编辑模型FireRed-Image-Edit:小红书团队出品,让图片编辑像说话一样简单小红书智能创作基础技术团队正式推出 FireRed-Image-Edit——一款通用图像编辑模型,凭借原生编辑架构、精准指令遵循能力,在广泛场景下实现高保真、视觉一致的编辑效果,既打破了专业修图的门槛...图像模型# FireRed-Image-Edit# 图像编辑模型# 小红书4周前01800
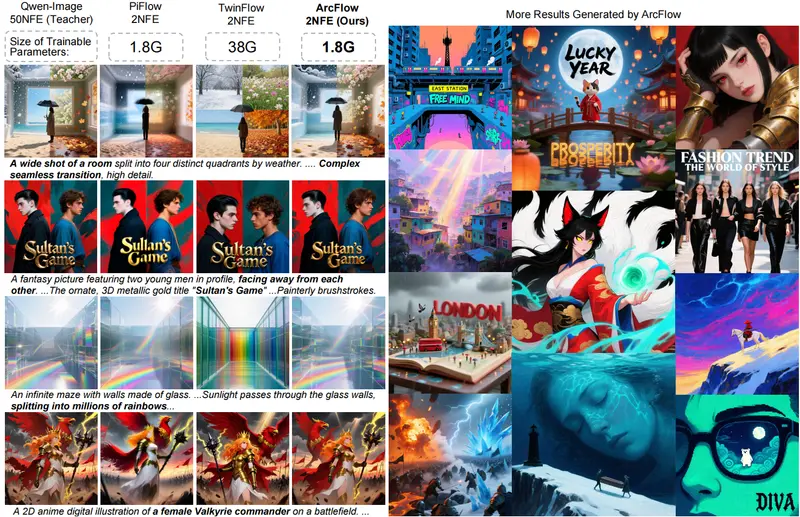
复旦与微软提出 ArcFlow:基于动量建模的非线性蒸馏框架,2 步生成高质量图像,加速 40 倍扩散模型凭借卓越的生成质量成为图像生成领域的核心技术,但40-100步的迭代去噪过程导致推理速度极慢,难以落地到实时应用场景。复旦大学与微软亚洲研究院联合提出的ArcFlow框架,通过非线性轨迹蒸馏的...图像模型# ArcFlow# 推理加速4周前0320
阿里重磅发布Qwen-Image-2.0 :支持 1K token 指令生成专业信息图,生图编辑一体化阿里全新推出新一代图像生成基础模型Qwen-Image-2.0,凭借专业文字渲染、细腻真实质感、超强语义遵循、轻量模型架构四大核心特色,实现生图与编辑功能的一体化融合,在文生图和图生图双赛道均展现出优...图像模型# Qwen-Image-2.04周前0310
Anima:20亿参数动漫专属文生图模型,ComfyUI原生支持,专注插画艺术创作CircleStone Labs 与 Comfy Org 联合打造的Anima文生图模型正式推出预览版,这款拥有20亿参数(2B)的模型专为动漫艺术打造,聚焦动漫概念、角色与风格创作,同时可生成各类非...图像模型# Anima# ComfyUI# 动漫1个月前02080