新Physion Labs推出Galileo-0:迈向可扩展的世界模型评判器Physion Labs 正式推出了 Galileo-0,这是首个专为世界模型(World Models)设计的自动化评判器。它不再仅仅给生成视频打一个模糊的分数,而是通过结构化的时空推理,精准诊断视...世界模型# Galileo-0# Physion Labs22小时前0130
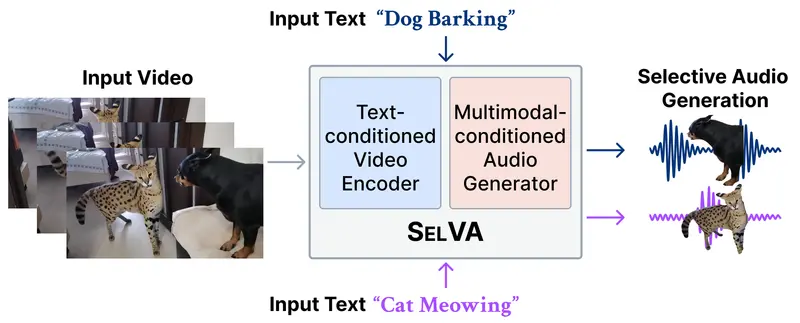
新SelVA:基于文本指令的视频选择性配音技术韩国科学技术院(KAIST)MAC 实验室与梨花女子大学 MMAI 实验室的研究人员共同提出了一项新任务:基于文本条件的选择性视频到音频生成(Text-Conditioned Selective Vi...视频模型# SelVA# 配音2天前040
新Netflix 推出 VOID:能理解物理交互的视频物体移除技术Netflix 联合保加利亚索菲亚大学团队,发布了一项视频编辑技术——VOID (Video Object and Interaction Deletion)。 GitHub:https://gith...视频模型# Netflix# VOID# 物体移除2天前040
新Ai2 发布 MolmoWeb:首个开放权重、全视觉的网页智能体,打破 API 黑盒在浏览器智能体(Browser Agent)领域,工程师们长期面临一个两难选择:要么使用功能强大但完全封闭、无法审计的专有 API(如 OpenAI Operator、Anthropic Comput...多模态模型# MolmoWeb# 网页智能体2天前070
新Arcee 发布 Trinity-Large-Thinking:3990 亿参数“美国制造”开源模型,剑指企业自主 AI在开源 AI 领域长期由 Meta(Llama)和中国实验室(Qwen、MiniMax、智谱等)主导的背景下,一家总部位于旧金山的初创公司 Arcee AI 正式发布了 Trinity-Large-T...大语言模型# Arcee# Trinity-Large-Thinking2天前0190
Holo Company 发布 Holo3:开源企业级计算机使用模型新标杆Holo Company 正式推出 Holo3,一款专为企业自动化设计的尖端计算机使用模型(Computer Use Model)。该模型在权威的 OSWorld-Verified 基准测试中取得了 ...多模态模型# Holo33天前040
京东发布 JoyAI-Image:集图像理解、文生图及指令引导编辑于一体的统一多模态基础模型京东今日正式发布 JoyAI-Image,这是一款集图像理解、文生图(T2I)及指令引导编辑于一体的统一多模态基础模型。不同于传统模型将理解与生成割裂处理,JoyAI-Image 的核心理念是构建“理...图像模型# JoyAI-Image# 京东4天前0390
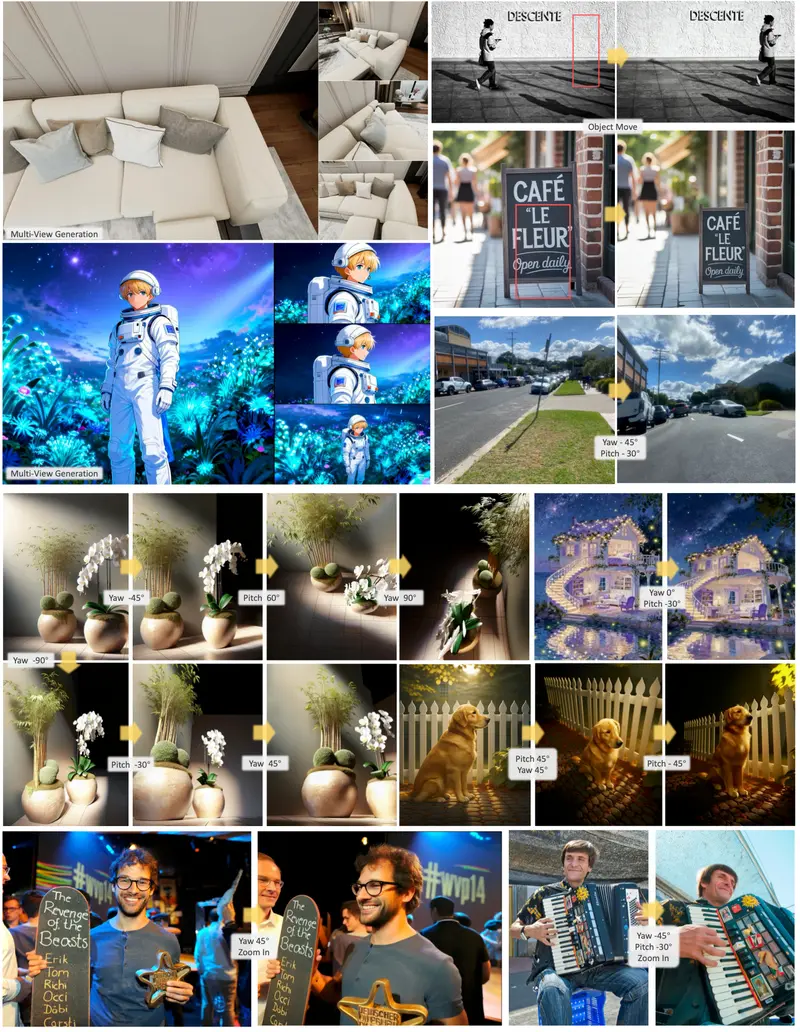
阿里发布全模态可控视频生成模型Wan2.7-Video:不仅是生成器,更是你的“AI 导演套件”阿里巴巴今日正式发布 视频生成模型Wan2.7-Video 。这不仅是一个文生视频工具,更是一套全模态、全链路的智能视频创作系统。Wan2.7 打破了传统 AI 视频“抽卡式”生成的局限,真正实现了让...早报视频模型# Wan2.7-Video# 阿里巴巴4天前0210
Marco-Nano-Base:阿里出品,8B 总参数仅激活 0.6B 的极致稀疏多语言模型Marco-Nano-Base 是由 阿里巴巴国际数字商业集团 (AIDC) 最新推出的紧凑型混合专家(MoE)大语言模型。作为 Marco-MoE 家族的最新成员,它通过极致的稀疏化设计,在保持 8...大语言模型# Marco-Nano-Base4天前0100
OmniWeaving:开源视频生成的“全能王”,首个具备推理与自由组合能力的统一模型OmniWeaving 是由 腾讯混元、浙江大学 和 南洋理工大学的研究人员推出的基于HunyuanVideo-1.5的视频生成模型。它填补了开源社区与闭源顶尖系统(如 Seedance-2.0)之间...视频模型# HunyuanVideo-1.5# OmniWeaving# 腾讯4天前0190
Qwopus3.5-27B-v3:颠覆“先想后做”,首创“先行动后优化”的代理编程模型开发者 Jackrong 正式发布了 Qwopus3.5-27B-v3,这是一款基于 Qwen3.5-27B 深度优化的推理增强模型。与前代及市面上大多数追求“长思维链”的模型不同,Qwopus-v3...大语言模型# Qwopus3.5-27B-v35天前0790
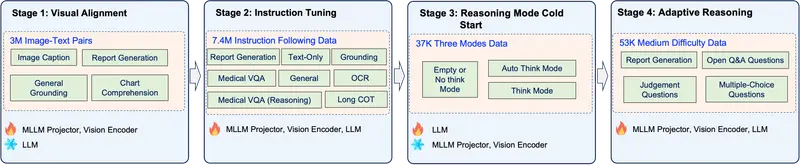
京东发布 JoyMed:全球首个自适应推理医疗大模型,重新定义 AI 诊断效率与精度京东推出 JoyMed,这是一款具有里程碑意义的医疗多模态基础模型。与当前主流医疗 AI 要么“盲目推理”浪费算力,要么“缺乏思考”导致误诊不同,JoyMed 首创了 自适应推理机制(Adaptive...大语言模型# JoyMed# 京东# 医疗大模型5天前0150