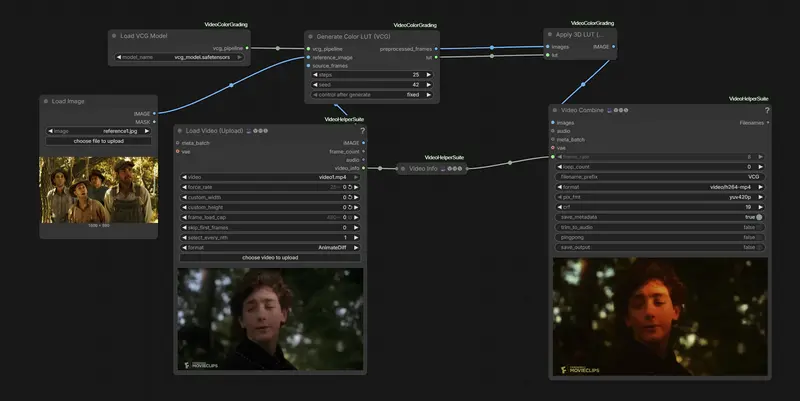
新Kijai 大神新作:ComfyUI-VideoColorGrading,通过自动生成 LUT 来进行视频调色Kijai 再次发力,为 ComfyUI 社区带来了基于 ICCV 2025 论文《Video Color Grading》的官方实现节点:ComfyUI-VideoColorGrading。 Git...插件# ComfyUI-VideoColorGrading# Video Color Grading22小时前070
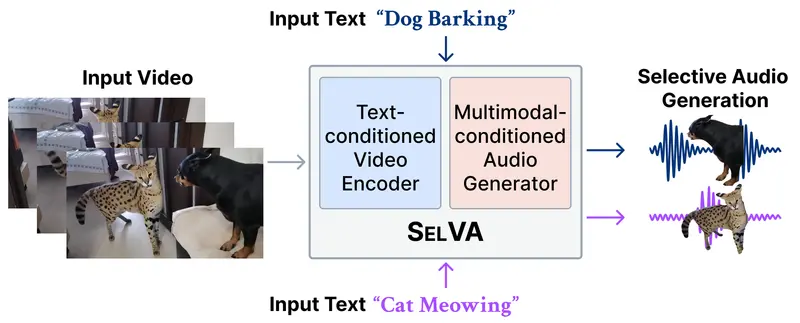
新ComfyUI-SelVA:让视频配音“指哪打哪”的文本控制节点ComfyUI-SelVA 是将 KAIST 最新研究成果 SelVA 引入 ComfyUI 的自定义节点包。它突破了传统视频转音频模型“有什么画面就配什么声音”的限制,实现了基于文本提示的精准声音选...插件# ComfyUI-SelVA# 视频配音2天前070
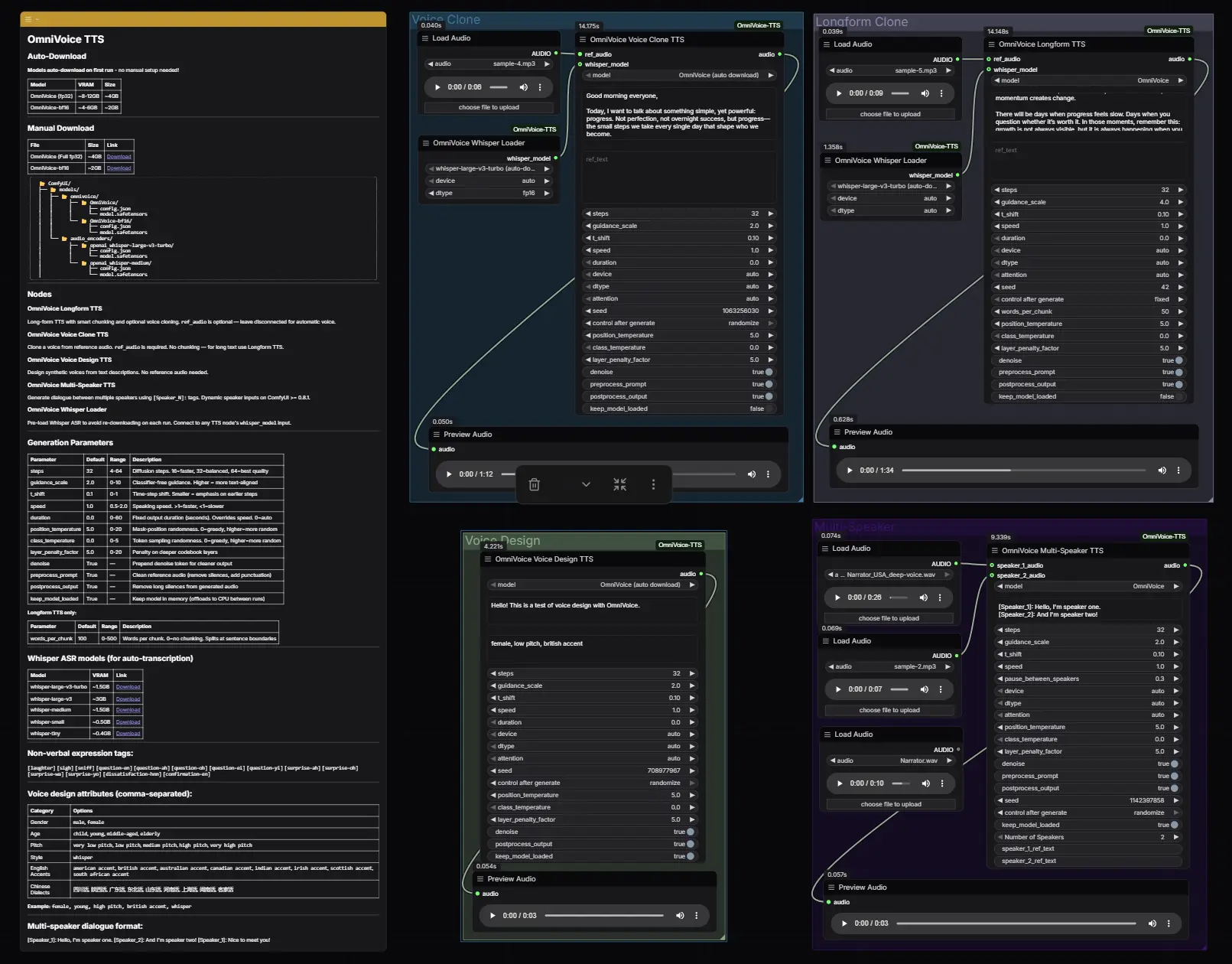
ComfyUI-OmniVoice-TTS:600+ 语言零样本语音合成,赋予你的工作流“声音”ComfyUI-OmniVoice-TTS 是将小米团队开源的 OmniVoice 模型集成到 ComfyUI 的强大自定义节点。它支持 600+ 种语言 的零样本文本转语音(TTS),具备业界领先的...插件# ComfyUI-OmniVoice-TTS# OmniVoice# 小米4天前0280
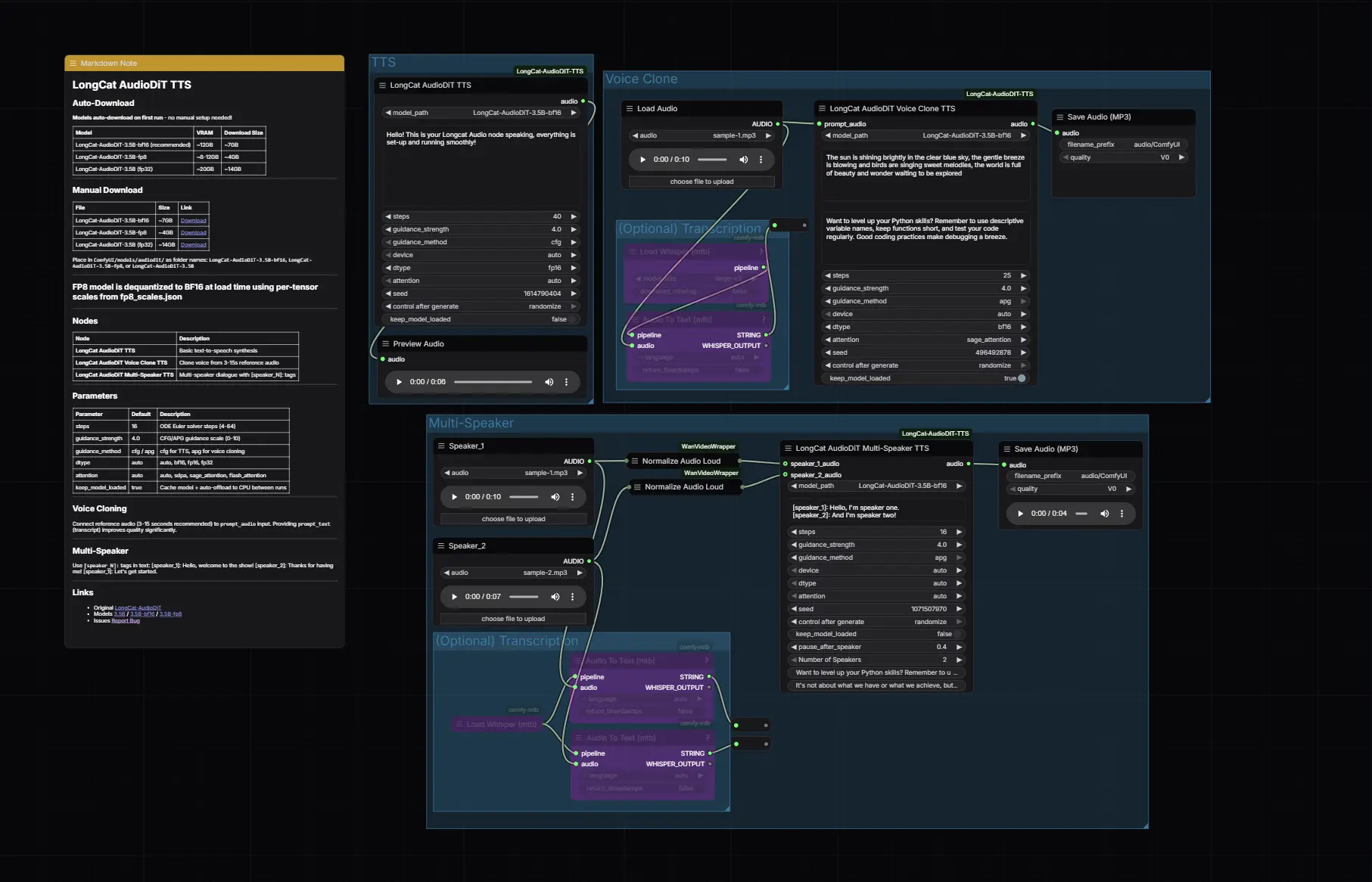
ComfyUI-LongCat-AudioDiT-TTS:在节点流中实现广播级零样本语音克隆ComfyUI-LongCat-AudioDiT-TTS 是将美团最新开源的 LongCat-AudioDiT 模型原生集成到 ComfyUI 的自定义节点插件。它利用基于扩散变换器(DiT)的架构和...插件# ComfyUI-LongCat-AudioDiT-TTS# LongCat-AudioDiT7天前0400
ComfyUI-See-through:一键将静态动漫图拆分为 Live2D 可用的 24 层 PSDComfyUI-See-through 是一个将 See-through 算法集成到 ComfyUI 的实用插件。它的主要功能是输入一张静态动漫角色插画,自动将其分解为多个语义图层(如头发、五官、衣物...插件# ComfyUI-See-through# PSD7天前01010
在 ComfyUI 中解锁无限可能:Qwen3.5 去拒斥模型(FP8/NVFP4)实战指南还在为 AI 助手频繁拒绝生成提示词而烦恼?想要一个能直接在 ComfyUI 工作流中理解图像、编写复杂 Prompt 且不受审查限制的本地大脑? 开发者 Winnougan 最新发布了基于 Qwen...工作流# ComfyUI# Qwen3.57天前0330
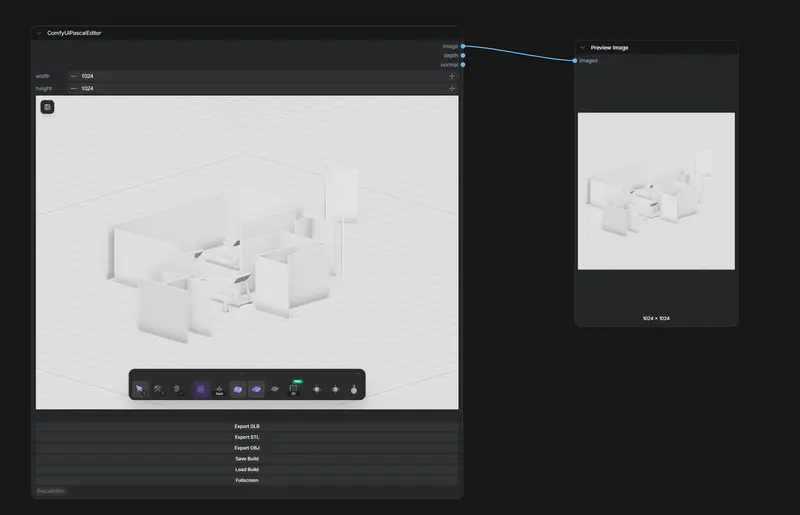
ComfyUI-PascalEditor:在 ComfyUI 中直接构建 3D 建筑,一键截图生成 ControlNet 底图ComfyUI-PascalEditor 是一款ComfyUI的插件,它将功能强大的 Pascal Editor(全功能 3D 建筑编辑器)无缝集成到了 ComfyUI 的工作流中。 GitHub:h...插件# 3D 建筑编辑器# ComfyUI-PascalEditor# Pascal Editor7天前0240
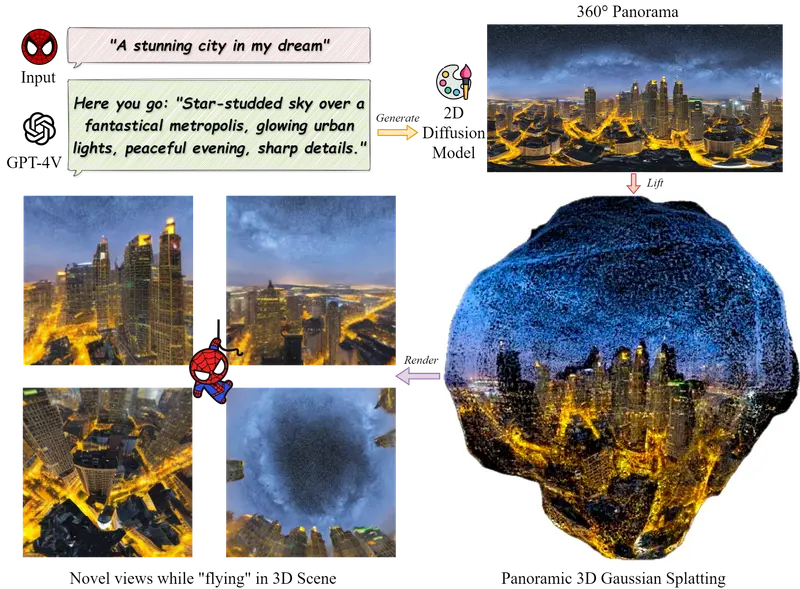
ComfyUI-DreamScene360:将 2.5D 全景图瞬间转化为可漫游的 3D 高斯世界在 3D 内容创作工作流中,360° 全景图(等距柱状投影) 是一种极易获取的资产(可通过 AI 生成、360 相机拍摄或游戏引擎渲染获得)。然而,全景图本质上是 2.5D 的——它只有一个视点,物体...插件# 360° 全景图# ComfyUI-DreamScene3601周前0110
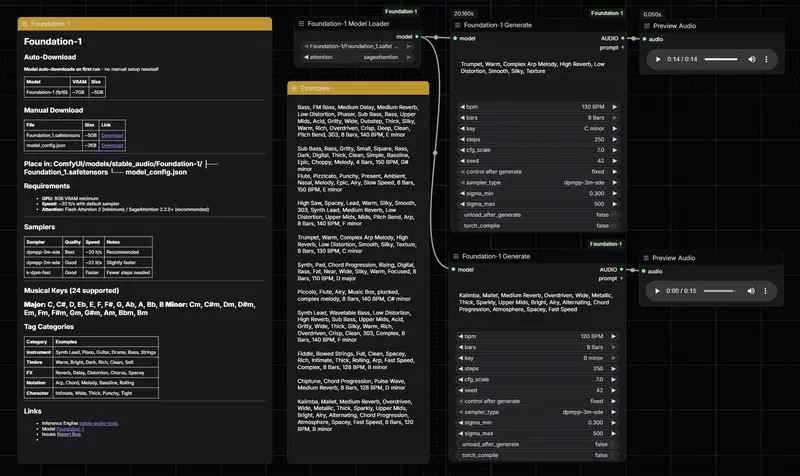
ComfyUI-Foundation-1:将专业音乐制作带入节点流,结构化文本生成完美循环对于音乐制作人和声音设计师而言,AI 生成音乐往往面临“不可控”的痛点:节奏对不上网格、调性混乱、音色难以精确描述。 GitHub:https://github.com/Saganaki22/Comf...插件# ComfyUI-Foundation-1# Foundation-11周前0170
ComfyUI-DaVinci-MagiHuman:150 亿参数音视频生成模型,消费级显卡也能跑 1080p!在 AI 视频生成领域,显存(VRAM) 一直是阻碍普通用户体验高质量模型的“拦路虎”。通常,运行一个 150 亿参数的单流 Transformer 模型需要企业级显卡(如 A100/H100)。 G...插件# ComfyUI-DaVinci-MagiHuman# daVinci-MagiHuman2周前01020
ComfyUI 动态显存革命:告别显存不足,让 56GB 模型在 32GB 显存上丝滑运行在 AI 绘画与视频生成领域,显存(VRAM)和系统内存(RAM) 一直是限制创作者发挥的最大瓶颈。面对动辄数十 GB 的图像和视频模型,许多用户不得不忍受频繁的“显存不足(OOM)”崩溃,或是依赖缓...新闻# ComfyUI# 动态显存2周前01340
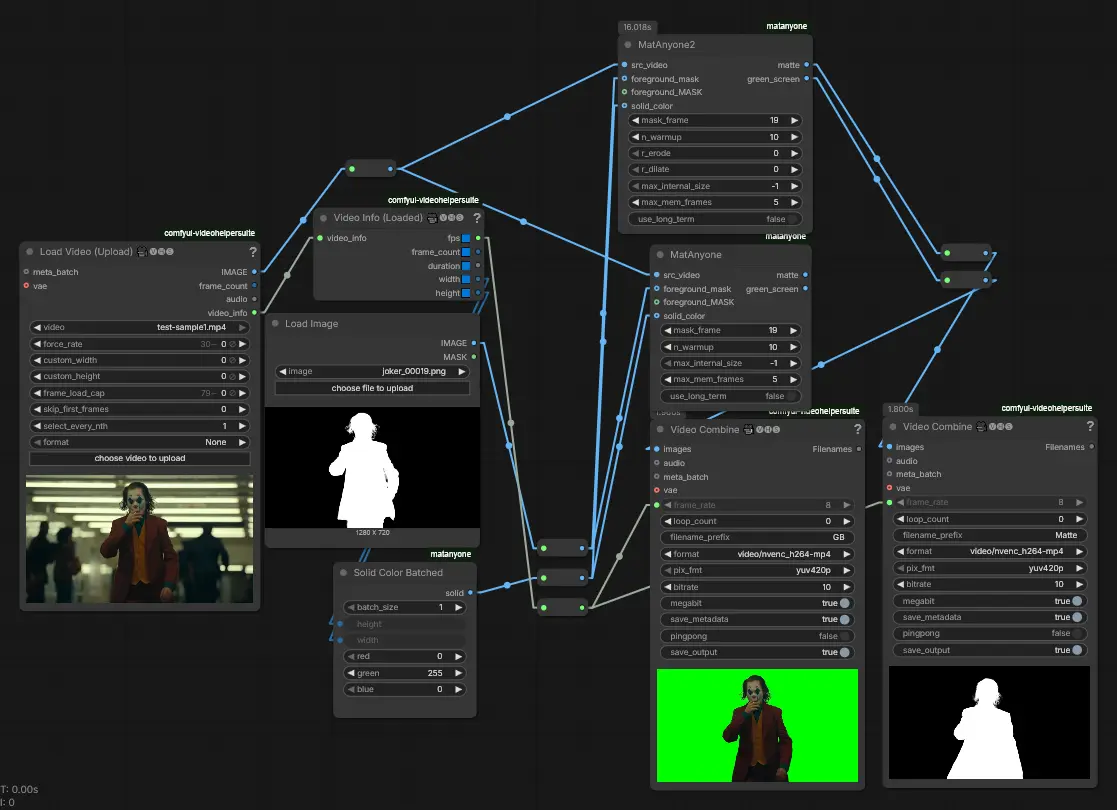
ComfyUI-MatAnyone:基于一致性记忆传播的稳定视频抠像节点ComfyUI-MatAnyone 是将先进的视频抠像模型 MatAnyone 及其升级版 MatAnyoneV2 引入 ComfyUI 生态的自定义节点。它专为解决视频处理中的核心痛点——时序一致性...插件# ComfyUI-MatAnyone# 视频抠像2周前0160