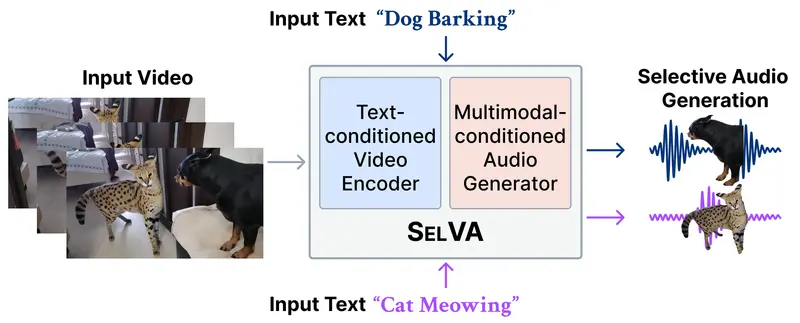
ComfyUI-SelVA 是将 KAIST 最新研究成果 SelVA 引入 ComfyUI 的自定义节点包。它突破了传统视频转音频模型“有什么画面就配什么声音”的限制,实现了基于文本提示的精准声音选择与生成。
- GitHub:https://github.com/ethanfel/ComfyUI-SelVA
通过结合 TextSynchformer 编码器与视觉同步流,SelVA 允许用户用自然语言描述想要听到的声音(如“只生成狗叫声”),从而从复杂的多声源视频中提取并合成特定的音频轨道,忽略其他无关噪音。
核心亮点
- 🗣️ 文本驱动选择:不再依赖繁琐的掩码绘制,只需输入文本提示(Prompt),即可指定生成特定声源的声音。
- 🎯 精准声源隔离:即使视频中有多种声音混合(如车流 + 人声 + 鸟叫),也能精准分离出目标声音,背景噪音极低。
- 🎭 智能掩码辅助:支持接入 SAM2、Grounding DINO 等分割掩码,进一步聚焦特定物体的运动,实现“视觉 + 语义”双重控制。
- ⚡ 特征缓存加速:自动缓存提取的视频特征(.npz),二次运行相同视频时瞬间完成,大幅提升工作流效率。
- 📦 自动化部署:模型权重首次使用时自动从 HuggingFace 下载,无需手动配置路径。
节点详解
1. SelVA 模型加载器 (SelVA Model Loader)
负责加载生成器、编码器及所有必要的特征提取工具(CLIP, T5, VAE 等)。
| 参数 | 选项 | 说明 |
|---|---|---|
| variant | small_16k, small_44k, medium_44k, large_44k | 选择模型大小与输出采样率。large 音质最好但显存占用高。 |
| precision | bf16, fp16, fp32 | 计算精度。推荐 bf16 (Ampere+) 或 fp16 以节省显存。 |
| offload_strategy | auto, keep_in_vram, offload_to_cpu | 显存管理策略。显存不足时选 offload_to_cpu。 |
2. SelVA 特征提取器 (SelVA Feature Extractor)
核心节点。从视频中提取视觉特征,并结合文本提示生成“引导信号”。
| 输入 | 说明 |
|---|---|
| video | 输入视频帧 (IMAGE 张量)。 |
| prompt | 关键参数:描述你想要生成的声音(如 "barking dog")。 |
| mask | (可选) 分割掩码。用于物理隔离目标物体,背景将被中性填充而非归零,以保持在 CLIP 分布内。 |
| mask_strength | 背景抑制强度 (0.0 - 1.0)。1.0 表示完全中性化背景。 |
| mask_sync / mask_clip | 控制掩码应用范围。可仅对同步特征应用掩码,而让 CLIP 保留全局上下文。 |
| cache_dir | 特征缓存目录。留空则使用系统临时目录。 |
💡 技巧:将本节点的
prompt输出直接连到采样器的prompt输入,避免重复填写。
3. SelVA 采样器 (SelVA Sampler)
执行修正流 ODE 推理,生成最终音频。
| 参数 | 说明 |
|---|---|
| negative_prompt | (可选) 描述你不想要的内容(如 "speech, music, noise"),进一步净化音质。 |
| steps | 采样步数,默认 25。增加可提高细节,但变慢。 |
| cfg_strength | 无分类器引导尺度,默认 4.5。越高越遵循 prompt,但可能失真。 |
| normalize | 是否将输出音量归一化到 [-1, 1]。 |
安装与模型
安装步骤
cd ComfyUI/custom_nodes
git clone https://github.com/Ethanfel/ComfyUI-SelVA.git
pip install -r ComfyUI-SelVA/requirements.txt
重启 ComfyUI 后即可在节点菜单中找到 SelVA 系列节点。
模型自动下载
首次运行时,节点会自动下载以下权重至 ComfyUI/models/selva/ 和 HuggingFace 缓存目录:
- 生成器:
generator_small/medium/large_44k_sup_5.pth - 编码器:
video_enc_sup_5.pth(TextSynchformer) - VAE & 声码器:
v1-44.pth,best_netG.pt - 基础模型: CLIP (DFN5B), T5 (flan-t5-base)
💻 显存需求建议
| 显存容量 | 推荐设置 | 可用模型 |
|---|---|---|
| 24 GB+ | offload_strategy: keep_in_vram | 所有型号 (包括 Large) |
| 12–24 GB | offload_strategy: offload_to_cpu | Medium / Small |
| 8–12 GB | offload_strategy: offload_to_cpu, precision: fp16 | Small only |
注:auto 模式会在显存 ≥ 16GB 时尝试常驻显存,否则自动卸载。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...