此前我们介绍过HeartMuLa_ComfyUI这款插件,你可能被其高显存占用劝退。现在,ComfyUI_FL-HeartMuLa 提供了更好的选择——这是一个原生开发、显存优化的 ComfyUI 节点,专为 HeartMuLa 开源音乐模型系列 设计,支持生成包含英语、中文、日语、韩语、西班牙语歌词的完整歌曲。
它不仅更轻量,还提供了对歌曲结构、风格、情绪的精细控制,真正实现“所想即所得”的 AI 音乐创作。
核心功能特性:多语言创作+精细化控制,兼顾易用性与专业性
ComfyUI_FL-HeartMuLa凭借原生开发架构,在实现丰富功能的同时,做到了显存友好,核心特性如下:
- 多语言歌词全覆盖:支持英语、中文、日语、韩语、西班牙语5种语言人声生成,歌词与旋律自然融合,无生硬拼接感;
- 结构化歌曲创作:通过
[Verse](主歌)、[Chorus](副歌)等官方段落标记,自定义歌曲的前奏、主歌、副歌、桥段、结尾结构,创作逻辑更贴合专业音乐制作; - 精细化风格控制:组合流派、人声类型、情绪、节奏、乐器等标签,精准定义歌曲风格(如“民谣、男声、治愈、慢节奏、木吉他”);
- 超长音频生成:单首歌曲最长可达240秒(4分钟),支持连续完整旋律输出,无需分段拼接;
- 零样本快速生成:无需训练微调,只需输入歌词和风格标签,即可直接生成歌曲,降低创作门槛;
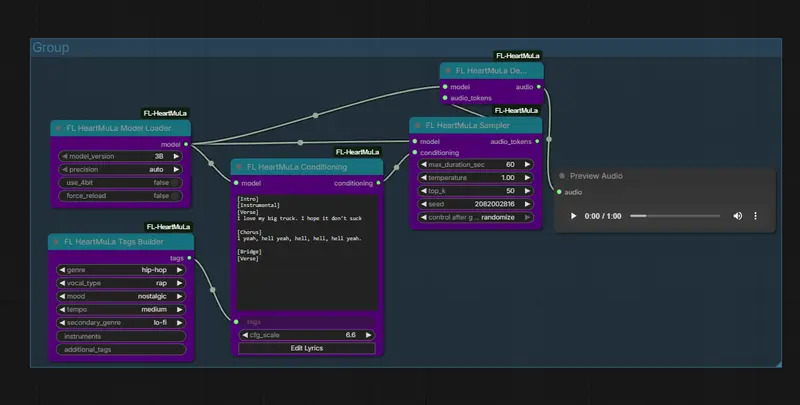
- 模块化流水线设计:将模型加载、条件处理、采样、解码拆分为独立节点,支持灵活组合工作流,方便高级用户自定义创作流程;
- 显存友好优化:原生开发架构大幅降低显存占用,低配GPU用户也能流畅运行。
核心节点解析:分工明确,轻松搭建创作流程
ComfyUI_FL-HeartMuLa的节点设计遵循“模块化”原则,每个节点各司其职,新手也能快速上手:
| 节点名称 | 核心功能 | 实用场景 |
|---|---|---|
| Model Loader | 自动下载并缓存HeartMuLa模型(支持3B版本) | 创作前的模型准备,首次使用自动下载,后续直接调用缓存 |
| Conditioning | 将输入的歌词和风格标签分词,转换为模型可识别的条件张量 | 连接模型与创作需求,是歌词和风格生效的关键步骤 |
| Sampler | 通过温度、CFG缩放等参数控制音频token采样过程 | 调节生成音乐的随机性和风格贴合度 |
| Decode | 调用HeartCodec解码器,将音频token转换为可播放的波形文件 | 生成最终可试听、导出的音频文件 |
| Tags Builder | 可视化构建风格标签组合,无需手动输入 | 新手友好,快速选择流派、人声、情绪等参数 |
| Transcribe | 从现有音频文件中提取歌词文本 | 反向工程,适合参考现成歌曲的歌词结构 |
安装教程:两种方式,一键部署
方式1:ComfyUI管理器安装(推荐新手)
- 打开ComfyUI,进入管理器界面;
- 在搜索框输入 FL HeartMuLa;
- 点击安装按钮,等待自动完成部署即可。
方式2:手动安装(适合进阶用户)
- 打开终端,进入ComfyUI自定义节点目录:
cd ComfyUI/custom_nodes - 克隆仓库:
git clone https://github.com/filliptm/ComfyUI_FL-HeartMuLa.git - 进入节点文件夹,安装依赖:
cd ComfyUI_FL-HeartMuLa pip install -r requirements.txt - 重启ComfyUI,即可在节点列表中找到FL HeartMuLa相关节点。
快速上手:5步生成你的第一首多语言歌曲
无需复杂配置,按照以下步骤,几分钟就能生成一首结构完整的歌曲:
- 加载模型:添加FL HeartMuLa Model Loader节点,选择3B模型(当前唯一已发布版本,显存占用最优);
- 设置条件:连接FL HeartMuLa Conditioning节点,在歌词输入框填入带段落标记的文本,例如:
[Intro] 月光洒满窗台 晚风轻轻吹来 [Verse] 翻开旧的日记 回忆慢慢清晰 [Chorus] 我们的故事 未完待续 藏在时光里 不离不弃 - 定义风格:在风格标签输入框填写组合标签,例如:
pop, female vocal, romantic, medium, piano; - 采样解码:依次连接Sampler→Decode→Preview Audio节点;
- 运行生成:点击队列运行按钮,等待片刻即可试听生成的歌曲。
进阶技巧:精准控制歌曲细节
1. 段落标记使用指南
合理使用官方段落标记,能让歌曲结构更符合音乐创作规律,支持的标记及用途如下:
| 段落标记 | 功能用途 | 创作建议 |
|---|---|---|
[Intro] | 器乐或人声前奏 | 建议搭配纯乐器标签,营造开场氛围 |
[Verse] | 主歌部分 | 承载核心叙事内容,歌词可偏口语化 |
[Prechorus] | 副歌前铺垫 | 节奏逐渐上扬,为副歌高潮做准备 |
[Chorus] | 主副歌/副歌 | 歌曲核心记忆点,建议重复出现 |
[Bridge] | 对比段落 | 风格或节奏突变,增加歌曲层次感 |
[Outro] | 结尾部分 | 旋律渐缓,可搭配淡出效果 |
[Instrumental] | 无人声段落 | 适合间奏,突出乐器独奏 |
2. 风格标签组合公式
风格标签由流派+人声+情绪+节奏+乐器5类元素组合而成,不同组合能碰撞出多样效果,以下是常用标签参考:
- 流派:pop、rock、electronic、jazz、classical、hip-hop、r&b、country、folk、metal、indie
- 人声:female vocal、male vocal、duet(合唱)、choir(合唱团)、instrumental(纯音乐)
- 情绪:energetic(活力)、melancholic(忧郁)、uplifting(振奋)、calm(舒缓)、romantic(浪漫)
- 节奏:slow(慢)、medium(中速)、fast(快)
- 乐器:piano(钢琴)、guitar(吉他)、drums(鼓)、synth(合成器)、strings(弦乐)
示例组合:indie folk, male vocal, calm, slow, acoustic guitar(独立民谣、男声、舒缓、慢节奏、木吉他)
3. 采样器参数调优
Sampler节点的参数直接影响生成效果,根据需求调整以下参数,能获得更满意的歌曲:
| 参数 | 默认值 | 范围 | 参数调整技巧 |
|---|---|---|---|
| max_duration_sec | 60 | 10-240 | 生成短视频配乐设为10-30秒,完整歌曲设为120-240秒 |
| temperature | 1.0 | 0.1-2.0 | 越低越贴合标签(0.5-0.8适合精准创作),越高越随机(1.2-1.5适合创意探索) |
| top_k | 50 | 1-500 | 数值越小,生成旋律越保守;数值越大,越容易出现新颖旋律 |
| cfg_scale | 1.5 | 1.0-10.0 | 越高,风格标签的约束力越强(建议1.2-2.0,过高易导致旋律生硬) |
| seed | -1 | -1至2^31 | -1为随机种子,固定数值可复现同一首歌 |
模型与系统要求:选对设备,流畅创作
1. 模型版本信息
当前仅发布3B模型,7B模型即将推出,两者对比如下:
| 模型 | 体积 | fp16显存需求 | 4-bit量化显存需求 | 适用场景 |
|---|---|---|---|---|
| 3B | ~6GB | ~12GB | ~6GB | 推荐多数用户,平衡效果与显存 |
| 7B | ~14GB | ~24GB | ~12GB | 追求更高音质和复杂旋律,适合高配设备 |
注:模型首次使用时会自动下载到
ComfyUI/models/heartmula/目录,无需手动下载。
2. 最低系统要求
- Python版本:3.10及以上
- 内存:最低16GB(推荐32GB及以上,避免生成过程中内存不足)
- GPU:英伟达显卡,12GB及以上VRAM(4-bit量化模式下仅需6GB VRAM)
- CUDA版本:推荐12.1及以上,提升模型运行效率
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











