如果你曾幻想过——只需输入一段歌词和一句描述(如“一首欢快的流行歌,吉他伴奏,副歌要有电子音效”),AI 就能生成一首结构完整、音质高保真的歌曲——那么 HeartMuLa 项目正将这一愿景变为现实。
由 HeartMuLa 项目组推出的这一开源音乐基础模型家族,首次将音乐理解、对齐、编解码与生成整合为统一框架,包含四个核心组件:
- HeartCLAP:音频-文本对齐模型
- HeartTranscriptor:歌词识别模型
- HeartCodec:低帧率高保真音乐编解码器
- HeartMuLa:基于 LLM 的可控歌曲生成模型
它们共同构成一个可扩展、可复现、完全开源的音乐 AI 生态系统。
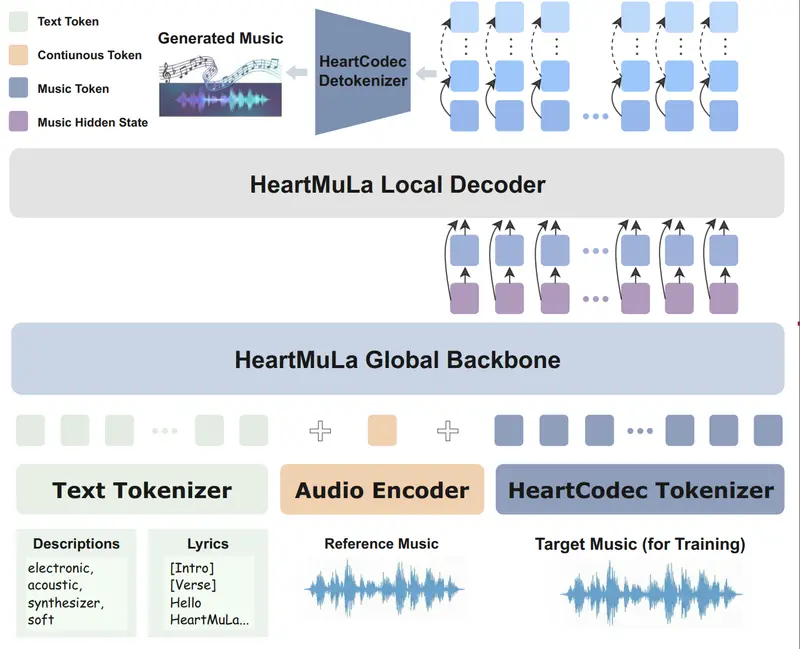
四大组件,各司其职
HeartCLAP:让音乐与文字“对上话”
通过对比学习,将音乐片段与文本描述(如“忧郁的钢琴独奏”)映射到同一语义空间。
→ 支持跨模态检索(如“找一首像周杰伦《晴天》的歌”)和自动打标。
HeartTranscriptor:精准识别复杂音乐中的歌词
基于 Whisper 微调,专为真实音乐场景优化(如混响、背景人声、多语种)。
→ 在 SSLD-200 和 HeartBeats-ASR-Bench 上达到最低词错率。
HeartCodec:12.5Hz 的高保真“音乐分词器”
传统音频编解码器帧率高(如 50–100Hz),导致生成效率低。
HeartCodec 以仅 12.5Hz 的低帧率,仍能保留声学细节并捕捉长程结构,显著提升自回归生成速度。
→ 客观指标(VISQOL、FAD)和主观听感均优于现有方案。
HeartMuLa:真正可控的歌曲生成
这是整个系统的“大脑”。它接受三种输入:
- 文本风格描述(如“复古合成器流行”)
- 歌词内容
- 参考音频(用于风格迁移)
并支持两种模式:
- 细粒度控制:分别指定前奏、主歌、副歌的风格(如“副歌加入失真吉他”)
- 短视频配乐:快速生成 15–30 秒的高质量背景音乐
模型采用分层 Transformer 架构:全局层建模歌曲结构,局部层填充细节,确保旋律连贯且富有表现力。
技术亮点
| 特性 | 说明 |
|---|---|
| 开源完整 | 所有模型、训练代码、评估基准均公开 |
| 多语言支持 | 支持中、英、日、韩等多语种歌词与风格描述 |
| 高效生成 | HeartCodec 的低帧率设计使推理速度提升 3–4 倍 |
| 用户可控 | 不是“随机生成”,而是按指令分段构建歌曲 |
实验结果
- HeartMuLa 在自建多语言基准 HeartBeats 上,
- 音乐质量、风格一致性、歌词清晰度全面超越开源(MusicGen、AudioLDM2)和闭源模型
- 英语歌词音素错误率(PER)低至 0.09
- HeartCLAP 在 WikiMT-X 跨模态检索任务中,
- 显著优于 Laion-CLAP、MuQ-MuLan 等基线
- HeartCodec 在重建保真度上,
- VISQOL 分数达 4.2+(接近原始音频)
应用场景
- 音乐创作辅助:作曲人快速试听不同风格版本
- 短视频配乐:一键生成符合情绪的背景音乐
- 游戏/影视动态配乐:根据剧情实时生成适配 BGM
- 音乐教育:展示“爵士 vs 摇滚”在结构与配器上的差异
- 多模态内容生产:结合视频、文本自动生成同步音轨
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











