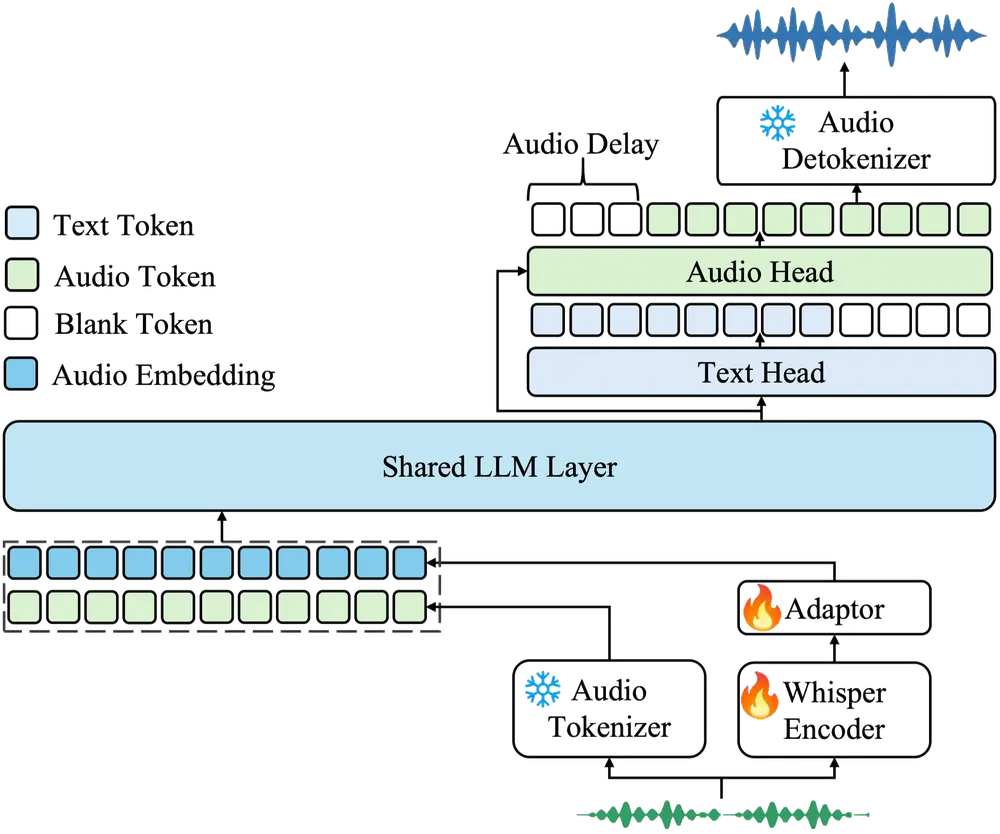
Vui 是一组轻量级、可本地运行的开源对话语音模型,支持设备端部署,适用于对话生成、语音克隆及非语音声音合成等任务。
- GitHub:https://github.com/fluxions-ai/vui
- 模型:https://huggingface.co/fluxions/vui
- Demo:https://huggingface.co/spaces/fluxions/vui-space
该系列模型由多个子模型组成,专为不同的语音交互场景设计,具备良好的上下文理解和自然对话能力。
🧠 模型概览
✅ Vui.BASE
- 基础语音模型,在 40,000 小时对话音频数据 上进行微调;
- 可作为语音克隆的基础模型使用;
- 支持多种语言与说话风格,适合通用语音生成任务。
✅ Vui.ABRAHAM
- 单人语音模型,具有上下文感知能力;
- 能够根据对话历史维持连贯语义,适用于虚拟助手、角色对话等场景;
- 输出语音自然流畅,适合构建个性化语音交互系统。
✅ Vui.COHOST
- 包含两个说话者检查点的对话模型;
- 支持双人角色相互对话,适用于播客模拟、访谈生成等应用;
- 可配置不同语气、节奏与表达方式,增强对话多样性。
🎙️ 语音克隆能力
通过 Vui.BASE 模型,用户可以实现基本的语音克隆功能:
- 输入目标说话人的少量音频(建议30秒以上);
- 模型将学习其音色、语调与发音特征;
- 输出模仿该说话人的语音内容。
尽管效果“相当不错”,但目前仍存在一定的局限性:
- 因训练数据有限,语音细节还原度仍有提升空间;
- 对长段语音或复杂情感表达的支持尚不完善;
- 如需更高保真语音克隆,建议结合更专业的TTS模型进行后处理。
🔊 非语音声音生成
除了标准语音,Vui 系列模型还能够生成多种非语音类声音,例如:
- 呼吸声
- 笑声、咳嗽声
- 轻声低语
- 思考停顿音效
这一特性使其在虚拟角色塑造、游戏配音、有声内容创作等领域具有广泛应用潜力。
📦 使用建议
- 适用平台:支持本地部署,适合在桌面端或边缘设备上运行。
- 模型大小:轻量化设计,适合资源受限环境。
- 开源地址:相关代码与预训练模型已开源,可在 Hugging Face 或 GitHub 获取。
- 开发建议:
- 若需更高语音质量,建议结合 Whisper + Vui 实现语音到语音的完整对话链;
- 可通过提示词控制说话风格、语速、情绪等参数,探索更多创意玩法。
🚀 应用场景展望
| 场景 | 描述 |
|---|---|
| 虚拟助手 | 构建具备个性语音的智能助手 |
| 角色配音 | 快速生成游戏角色对话样本 |
| 语音交互测试 | 用于语音 UI 测试、多轮对话系统调试 |
| 有声书/播客生成 | 搭配文本生成模型,打造自动化内容生产流程 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











