Meta AI 近日发布了 Omnilingual ASR——一套开源、可扩展的多语言自动语音识别(ASR)系统,支持 1600 多种语言,并能通过零样本上下文学习泛化到 超过 5400 种语言,包括许多此前从未拥有有效语音识别模型的语言。
- GitHub:https://github.com/facebookresearch/omnilingual-asr
- Demo:https://huggingface.co/spaces/facebook/omniasr-transcriptions
- 官网:https://aidemos.atmeta.com/omnilingualasr/language-globe
该系统基于 wav2vec 2.0 架构,结合大规模自监督预训练与创新的解码策略,在更低数据消耗下实现了与现有主流系统(如 Google USM)相当甚至更优的性能。
覆盖范围:从主流语言到长尾语种
- 监督训练数据来自名为 AllASR 的综合语料库,包含 120,710 小时的标注语音,覆盖 1,690 种语言。
- 其中,3,350 小时来自 Omnilingual ASR Corpus——由 Meta 与非洲、南亚等地的本地社区合作采集,采用开放式提示(如“讲述你的一天”),鼓励自然口语表达,而非朗读固定文本,提升了语言的真实性和多样性。
- 自监督预训练使用 430 万小时无标签语音,覆盖 1,239 种语言(另有 46 万小时未标注语言标识),远少于 Google USM 的 1200 万小时,但性能更具数据效率。

模型架构:三个开放模型家族
所有模型共享同一个 wav2vec 2.0 语音编码器,参数规模从 300M 到 7B 不等:
1. SSL 编码器(OmniASR W2V)
- 仅包含 wav2vec 2.0 编码器,用于提取语音表征。
- 提供 300M、1B、3B、7B 四种规模,可用于下游任务迁移。
2. CTC ASR 模型
- 在编码器后接一个线性层,使用字符级 CTC 损失训练。
- 支持实时推理:300M 模型在 A100 上处理 30 秒音频的实时因子低至 0.001(即 1 秒可处理 1000 秒音频)。
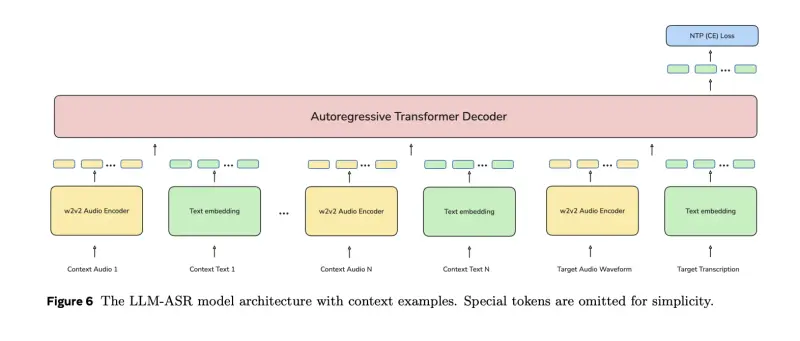
3. LLM ASR 模型
- 在编码器之上堆叠 Transformer 解码器,以类似语言模型的方式预测字符序列。
- 参数从 1.6B(300M 编码器)到 7.8B(7B 编码器)。
- 支持可选语言标识(如
eng_Latn、cmn_Hans),训练中部分样本故意隐藏语言标签,使模型能在未知语言下仍可推理。

零样本扩展:无需训练,仅靠示例即可识别新语言
对于未在训练中出现的语言,Omnilingual ASR 引入了 上下文学习(in-context learning) 能力:
- 训练方式:解码器接收 N 个同语言的语音-文本对作为上下文,再预测第 N+1 个语音的转录。
- 推理方式:用户提供 少量示例(如 2–5 对语音和文字),模型即可转录该语言的新语音,无需更新权重。
- 示例选择:系统集成 SONAR(Meta 的多语言多模态编码器),将目标语音与已有语音-文本对在共享嵌入空间中进行最近邻检索,自动选择最相关的上下文示例,显著优于随机选择。
此机制使系统理论上可覆盖 Unicode 支持的 5400+ 语言,为语言保护、田野调查、边缘社区数字包容提供工具基础。
性能表现
- omniASR_LLM_7B 在 1600+ 支持语言中的 78% 上实现 字符错误率(CER)低于 10%。
- 在 FLEURS-102 多语言基准上,其性能优于同规模的 CTC 模型,并超越 Google USM 的平均 CER,尽管预训练数据量仅为对方的三分之一。
- 证明:扩展 wav2vec 2.0 + LLM 风格解码器 是构建高覆盖、高精度多语言 ASR 的有效路径。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











