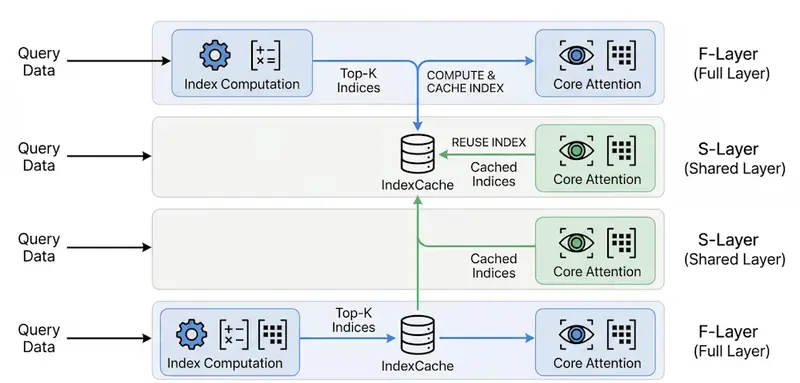
新IndexCache:解锁长上下文 AI 的“速度密码”,推理提速高达 1.82 倍在处理 20 万 token 甚至更长的上下文时,大型语言模型(LLM)往往面临“又贵又慢”的困境。随着上下文长度增加,计算成本呈平方级飙升,成为阻碍长文档分析、复杂智能体工作流落地的最大瓶颈。 论文...新技术# IndexCache1小时前030
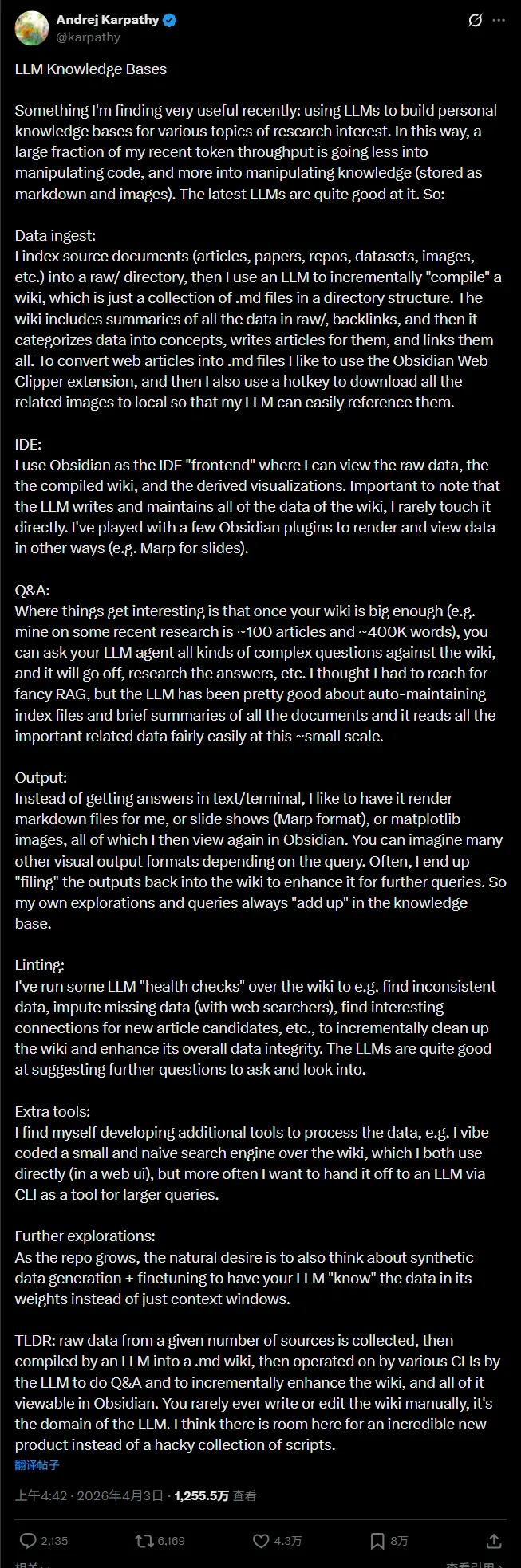
新告别 RAG 复杂堆栈?Karpathy 分享“LLM 知识库”新思路:让 AI 自主维护知识库Andrej Karpathy 又给“氛围编程”爱好者送礼物了。 这位特斯拉前 AI 总监、OpenAI 联合创始人,最近在 X 上分享了他正在使用的一套“LLM 知识库”架构。核心思路很简单,却极具...早报# Andrej Karpathy# LLM 知识库2小时前020
新微软的 AI “免责声明”!Copilot 很强大,但别把命交给它微软一边在 Windows 和企业工具里拼命塞进 Copilot,告诉你这是“下一代生产力基石”;另一边,却在不起眼的法律条款里悄悄写下一行小字: “风险自负地使用 Copilot。” 这不是什么新发...早报# Copilot# 微软4小时前040
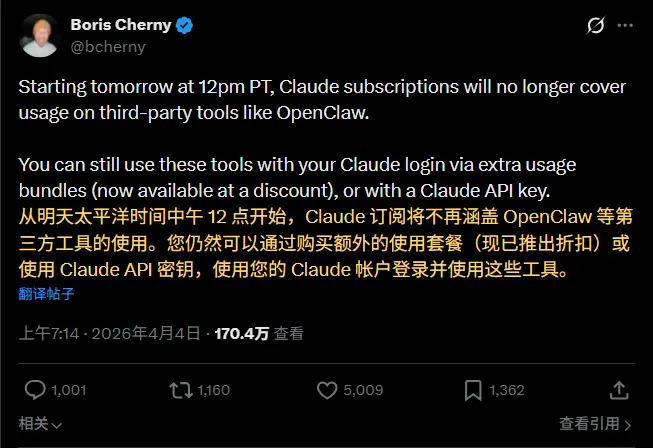
新Anthropic“封杀”OpenClaw:订阅用户被迫额外付费,第三方工具链遭遇重创Anthropic 实施了一项极具争议的新政策,实质上禁止了 Claude 订阅用户 免费使用 OpenClaw 等第三方工具链。从 2026 年 4 月 4 日(太平洋时间中午 12 点) 起,通过...早报# Anthropic# Claude Code# Claude Cowork23小时前060
新阿里发布全模态可控视频生成模型Wan2.7-Video:不仅是生成器,更是你的“AI 导演套件”阿里巴巴今日正式发布 视频生成模型Wan2.7-Video 。这不仅是一个文生视频工具,更是一套全模态、全链路的智能视频创作系统。Wan2.7 打破了传统 AI 视频“抽卡式”生成的局限,真正实现了让...早报视频模型# Wan2.7-Video# 阿里巴巴2天前090
新微软5月起移除Loop中Copilot生成回顾功能,聚焦手动编辑与其他M365 AI能力微软宣布5月下旬从Loop中移除Copilot生成的回顾功能,仅保留手动回顾编辑,这一“收缩AI功能”的举动与微软此前全面铺开Copilot的策略形成反差。 核心变更详情 移除范围:仅删除AI自动生成...早报# Copilot# Loop# 微软2天前040
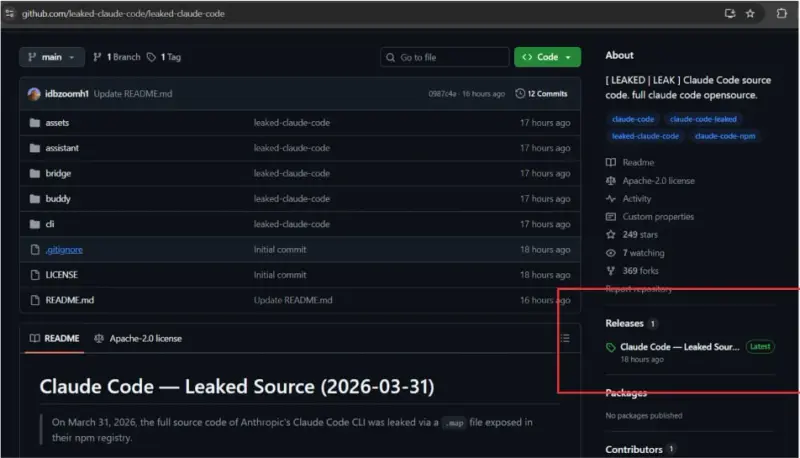
新Claude Code源码遭泄露,黑客借GitHub散布窃密木马Anthropic旗下终端AI智能体Claude Code出现源码泄露事故,不法分子借此在GitHub搭建恶意仓库,向搜寻泄露文件的用户投放Vidar信息窃取恶意软件,引发网络安全风险。 事件源头:C...早报# Claude Code# GitHub2天前090
新微软 MAI 团队亮剑:发布三款自研基础模型,主打“更快、更准、更便宜”微软 AI(Microsoft AI)旗下的 MAI 超智能团队(由 Mustafa Suleyman 领导)今日正式宣布推出三款全新的自研基础模型:MAI-Transcribe-1、MAI-Voic...早报# MAI-Image-2# MAI-Transcribe-1# MAI-Voice-12天前090
新Google Vids 重磅更新!搭载 Veo 3.1,支持自定义 AI 虚拟形象 + 一键发布 YouTubeGoogle Vids,这款集成在 Google Workspace 中的 AI 驱动视频创作工具,今日迎来了自发布以来最重大的功能更新。通过整合谷歌最新的 Veo 3.1 视频生成模型,Vids 现...早报# Google Vids2天前0110
新Cursor 3 正式发布:软件开发进入“智能体群”时代,打造统一自主工作区Cursor 今日正式推出 Cursor 3,标志着软件开发正式迈入第三个时代:智能体群(Swarm of Agents)时代。 官方介绍:https://cursor.com/cn/blog/cur...早报# Cursor 32天前0140
新Ollama现已率先支持Gemma 4,完整部署指南与使用规范Ollama已完成适配,第一时间上线对谷歌全新开放模型Gemma 4的支持,开发者可快速在本地部署使用该系列模型 谷歌发布Gemma 4:迄今为止最智能的开放模型,多硬件适配可离线运行 Gemma 4...工具早报# Gemma 4# Ollama2天前080
新谷歌发布Gemma 4:迄今为止最智能的开放模型,多硬件适配可离线运行今日,谷歌正式推出全新开放模型Gemma 4,并称其为“迄今为止最智能的开放模型”。该模型专为高级推理和智能体工作流打造,核心亮点在于实现了前所未有的单位参数智能水平,既能在自有硬件上高效运行,又能通...大语言模型早报# Gemma 4# 谷歌2天前0130