以 Token 为核心重构 AI 战略!阿里巴巴成立“Alibaba Token Hub”事业群, 悟空事业部首度曝光2026年3月16日,阿里巴巴集团内部发出一封重磅邮件,宣布正式成立 Alibaba Token Hub(简称 ATH)事业群。这一新组织由阿里巴巴 CEO 吴泳铭直接负责,标志着阿里在 AGI(通用...百科# Alibaba Token Hub# 悟空事业部# 阿里巴巴2周前0110
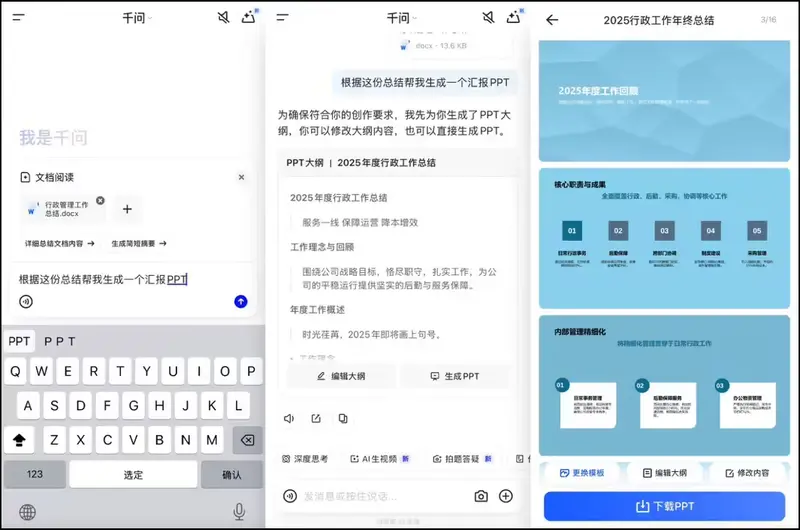
阿里千问上线一站式智能文档与 PPT 生成,免费开放阿里千问宣布,将 文档生成、智能排版、在线编辑、多格式转换 等能力全面整合,推出一站式智能文档中心。所有功能即日起向所有用户免费开放。 现在,用户无需再切换多个 Office 软件,只需与千问对话,即...早报# 千问# 阿里巴巴4个月前0300
阿里重磅官宣:千问 App 全平台公测,Qwen 最强模型打造“会办事”的AI生活入口今日,阿里巴巴正式宣布 千问 App 全平台公测上线——这款基于全球第一开源模型通义千问 Qwen 打造的个人 AI 助手,不仅延续了强大的对话能力,更以“会聊天、能办事”为核心定位,剑指未来 AI ...早报# Qwen# 千问 App# 阿里巴巴4个月前0430
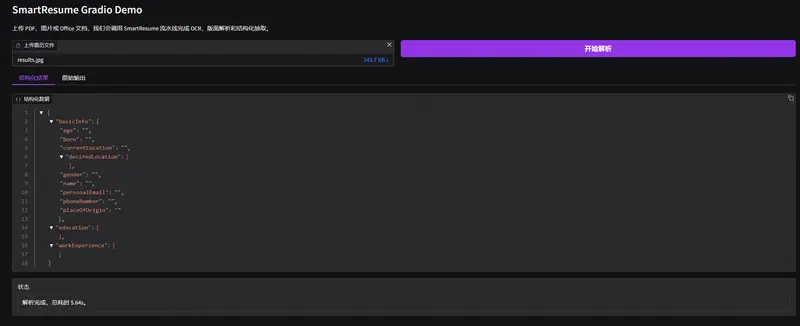
阿里巴巴推出 SmartResume:一个能“读懂”复杂简历版式的智能解析系统在企业招聘中,自动化处理海量简历是刚需,但简历格式千奇百怪——多栏排版、图文混排、表格嵌套,传统文本提取工具常会打乱语义顺序,导致关键信息错位。 针对这一难题,阿里巴巴企业智能团队发布了 SmartR...多模态模型# SmartResume# 智能简历解析# 阿里巴巴5个月前02090
阿里发布 AgentScope 1.0:面向生产级智能体的开源开发框架阿里巴巴近日正式推出 AgentScope 1.0 —— 一个以开发者为核心的开源智能体(Agent)开发框架,致力于解决当前智能体应用在可控性、可维护性和落地部署方面的关键挑战。 不同于仅聚焦于单点...大语言模型# AgentScope 1.0# 智能体开发框架# 阿里巴巴7个月前01840
阿里发布 Qwen3-4B 双模型:小参数,大能力,原生支持 256K 上下文在大模型“军备竞赛”愈演愈烈的今天,阿里巴巴通义实验室反其道而行之,推出两款 40 亿参数级别 的小型语言模型: Qwen3-4B-Instruct-2507:面向多语言、高响应速度的通用指令模型 Q...大语言模型# Qwen3-4B-Instruct-2507# Qwen3-4B-Thinking-2507# 通义实验室8个月前04280
阿里 Qwen 项目组正式推出全新多模态模型Qwen VLo随着多模态大模型的不断发展,我们对技术边界的认知也在持续被刷新。从最初的 QwenVL 到如今的 Qwen2.5 VL,我们在提升模型图像理解能力方面不断取得进步。 项目主页:https://qwen...多模态模型# Qwen VLo# Qwen 项目组# 阿里巴巴9个月前02240
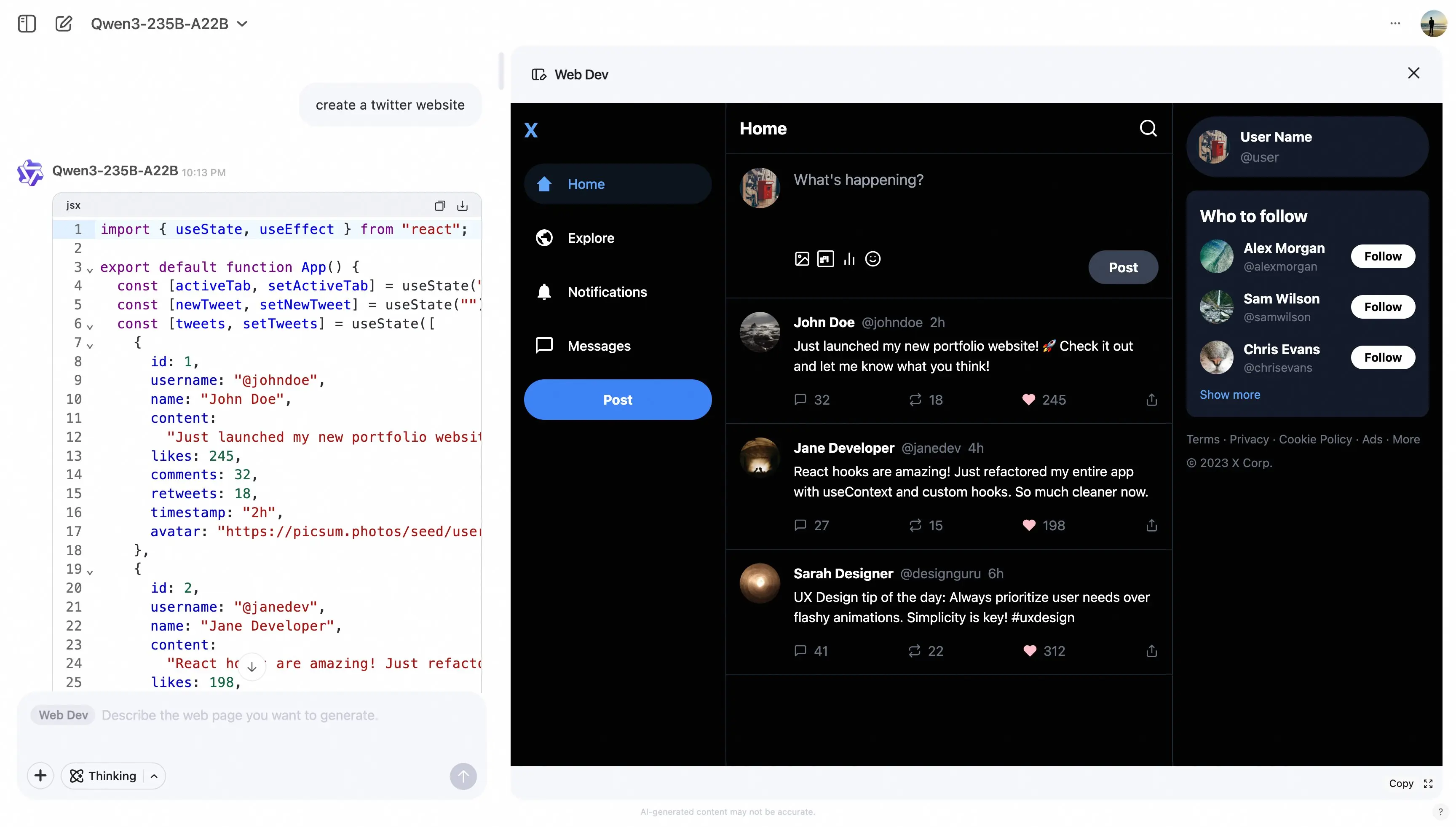
阿里Qwen Chat上线Web Dev功能,用一句话生成完整网页Qwen官网新增Web Dev功能,让网页开发变得前所未有的简单。 类似于Claude的Artifacts和Gemini的Canvas,Qwen Web Dev可以直接渲染网页,并结合Qwen 3强大...早报# Qwen Chat# Web Dev# 阿里巴巴11个月前06010
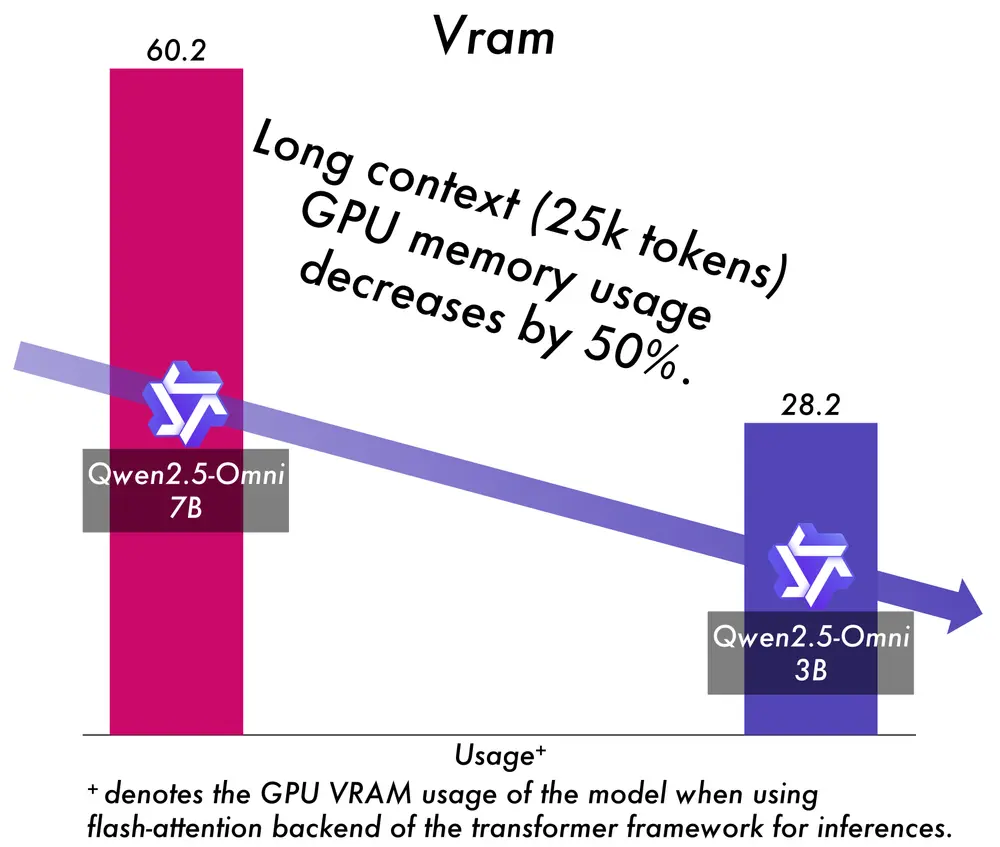
阿里Qwen团队发布端到端多模态模型Qwen2.5-Omni-3B阿里Qwen团队在发布Qwen3系列模型后,又推出Qwen2.5-Omni系列的一个新模型Qwen2.5-Omni-3B,这是一个端到端多模态模型,能够无缝处理文本、图像、音频和视频等多种输入形式,并...多模态模型# Qwen# Qwen2.5-Omni-3B# 阿里巴巴11个月前04710
阿里推出 Qwen3 系列大模型:开源 8 款模型,性能飞跃,多语言支持,推理能力显著提升阿里 QWEN 团队在今天推出 Qwen3,这是 Qwen 系列大言模型的最新力作。Qwen3 以其卓越的性能和广泛的应用潜力,正在成为开源AI领域的新焦点。 性能突破:超越行业标杆 Qwen3 的旗...大语言模型# QWEN 团队# 阿里巴巴11个月前05830
阿里巴巴通义实验室推出Wan2.1-FLF2V-14B:140亿参数的首尾帧到视频生成大模型阿里巴巴通义实验室近日开源了Wan2.1系列的首款大模型——Wan2.1-FLF2V-14B。这是一款专为首尾帧到视频生成设计的140亿参数大模型,旨在为数字艺术家提供前所未有的效率和创作灵活性。 模...视频模型# Wan2.1-FLF2V-14B# 视频生成大模型# 阿里巴巴12个月前04050
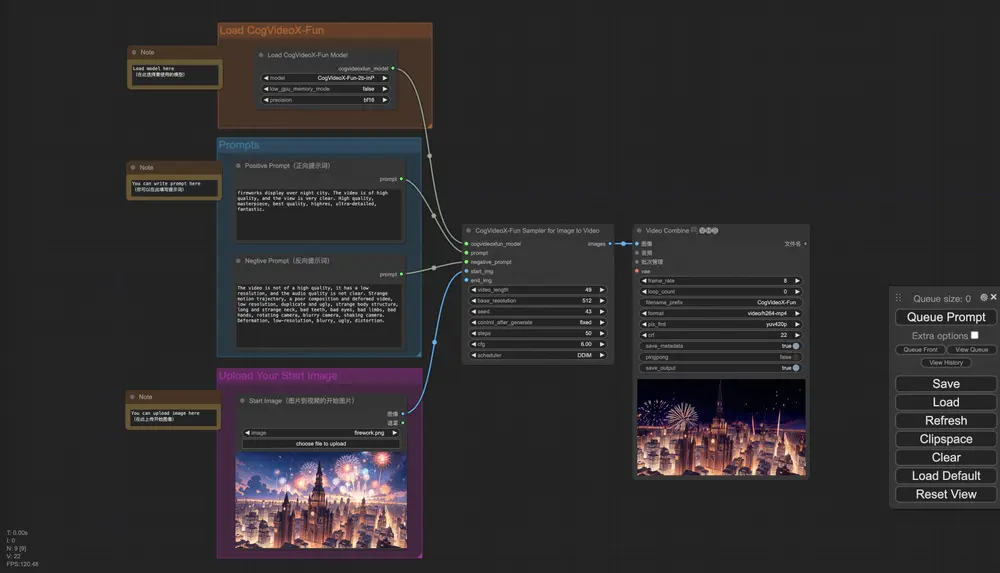
阿里旗下PAI项目组开源了视频生成模型Wan 2.1 的控制模型Wan2.1-Fun系列,支持Canny、Depth、Pose、MLSD等多种模式阿里旗下PAI项目组开源了视频生成模型Wan 2.1 的控制模型,支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制。 模型地址:https://huggingf...视频模型# Wan 2.1# Wan2.1-Fun-1.3B-Control# Wan2.1-Fun-1.3B-InP1年前03300