新Ai2 发布 MolmoWeb:首个开放权重、全视觉的网页智能体,打破 API 黑盒在浏览器智能体(Browser Agent)领域,工程师们长期面临一个两难选择:要么使用功能强大但完全封闭、无法审计的专有 API(如 OpenAI Operator、Anthropic Comput...多模态模型# MolmoWeb# 网页智能体2天前070
Holo Company 发布 Holo3:开源企业级计算机使用模型新标杆Holo Company 正式推出 Holo3,一款专为企业自动化设计的尖端计算机使用模型(Computer Use Model)。该模型在权威的 OSWorld-Verified 基准测试中取得了 ...多模态模型# Holo33天前040
英伟达发布 Nemotron OCR v2:企业级多语言文本识别OCR模型英伟达正式推出了 Nemotron OCR v2,这是一款专为复杂真实世界场景设计的尖端多语言光学字符识别(OCR)模型。作为 NVIDIA NeMo Retriever 系列的核心成员,该模型不仅实...多模态模型# Nemotron OCR v# 英伟达5天前090
阿里正式发布Qwen3.6-Plus :迈向现实世界智能体的关键一步阿里巴巴今日正式宣布 Qwen3.6-Plus 上线,标志着通义千问系列在智能体(Agent)编程与原生多模态推理领域实现了里程碑式的跨越。作为 Qwen3.5 系列的继任者,Qwen3.6-Plus...多模态模型# Qwen3.6-Plus# 阿里巴巴5天前060
阿里通义千问发布 Qwen3.5-Omni:全模态原生大模型,215 项 SOTA 碾压 Gemini 3.1 Pro“能听、能看、能思考、能执行,还能像真人一样打断和克隆声音。” 阿里巴巴正式发布了其最新一代全模态原生大模型——Qwen3.5-Omni。这款模型不仅在文本、图像、音频、视频的理解上实现了全面融合,更...多模态模型早报# Qwen3.5-Omni# 通义千问# 阿里1周前01270
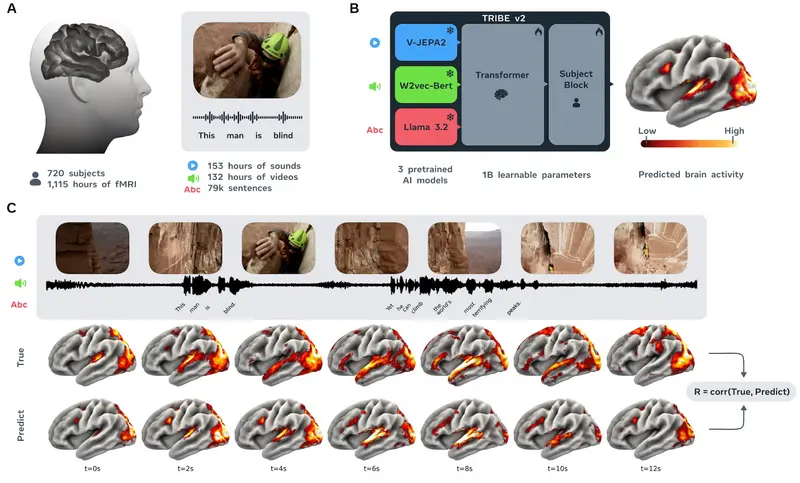
Meta 发布 TRIBE v2:AI 模型可精准预测大脑反应,神经科学迎来“数字孪生”时代脑科学研究长期受限于高昂的实验成本和缓慢的数据采集速度。功能性磁共振成像(fMRI)不仅需要昂贵的设备,还要求受试者长时间配合,且数据充满噪声。 GitHub:https://github.com/f...多模态模型# Meta# TRIBE v21周前080
美团开源 LongCat-Next:原生多模态新范式,用“离散 Token”统一文本、图像与语音在人工智能迈向“通用智能”的征途中,如何处理文本、图像、语音等多种模态数据,一直是业界最大的挑战之一。传统方案往往需要为不同模态设计独立的编码器,或采用复杂的跨模态对齐机制,导致模型架构臃肿、训练困难...多模态模型# LongCat-Next# 美团2周前01160
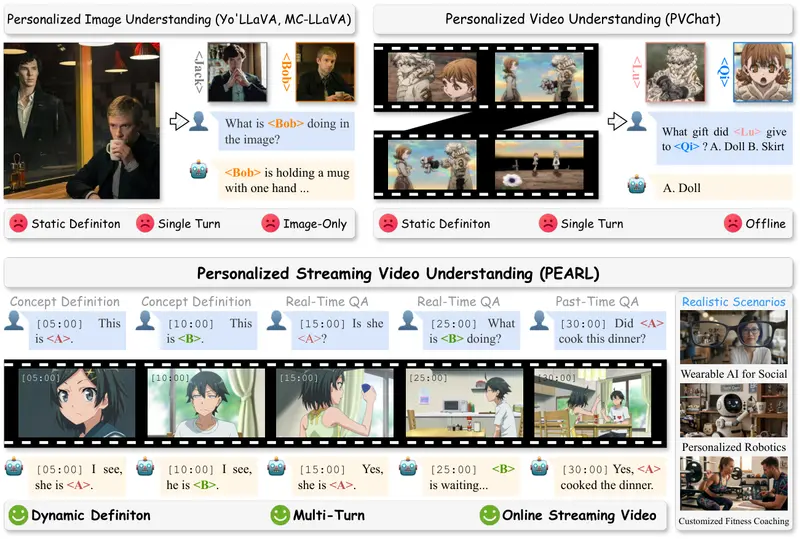
AI终于能“边看视频边记人”!北大等联合推出PEARL,实时互动不“失忆”想象一下这个场景:你正在看一部长达两小时的电影直播,中途你指着屏幕对 AI 助手说:“记住那个穿红衣服的女孩,她叫小红。” 十分钟后,你问:“小红现在在干嘛?” AI 立刻回答:“她在厨房切菜。” 半...多模态模型# PEARL# 视频理解2周前0330
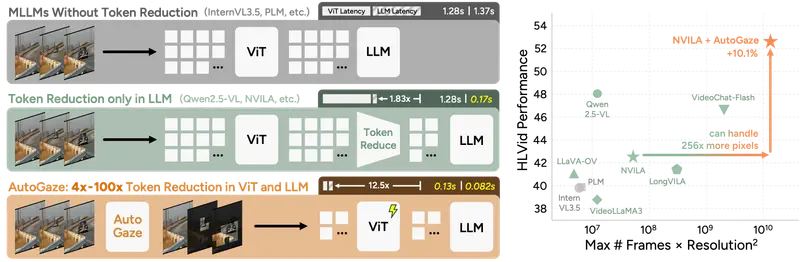
Attend Before Attention:伯克利与英伟达联手,让AI像人眼一样“扫视”视频,推理提速19倍在视频理解领域,长久以来存在一个巨大的效率悖论:人类只需扫视关键物体就能理解场景,而AI模型却必须像素级地“硬啃”每一帧。这种对时空冗余数据的无差别处理,导致当前的多模态大语言模型(MLLM)在面对长...多模态模型# Attend Before Attention# AutoGaze2周前0200
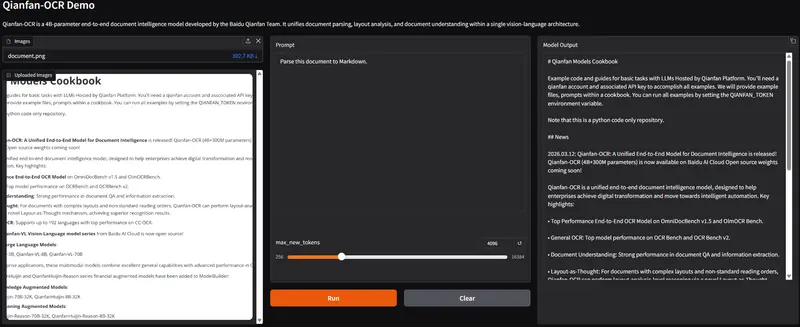
百度千帆发布 Qianfan-OCR:4B 参数端到端模型,文档解析能力全球第一百度千帆团队推出 Qianfan-OCR,这是一款参数量仅为 4B 的端到端文档智能大模型。不同于传统“检测 + 识别 + 理解”的多阶段流水线,Qianfan-OCR 在单一的视觉 - 语言架构内...多模态模型# Qianfan-OCR# 百度千帆3周前0590
智谱 AI 重磅发布 GLM-5-Turbo:专为 OpenClaw“龙虾”打造的极速智能体引擎在 AI 智能体(Agent)从“对话”走向“执行”的关键时刻,智谱 AI 正式推出了 GLM-5-Turbo —— 一款专为 OpenClaw(俗称“龙虾”)场景深度优化的基座模型。 国内版: 文档...多模态模型早报# GLM-5-Turbo# 智谱 AI3周前01310
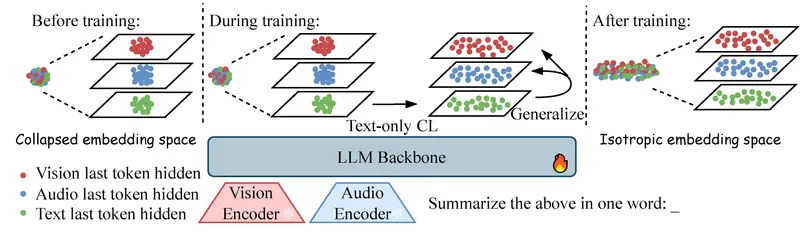
LCO-EMB:阿里达摩院新突破,用“纯文字”训练出全能多模态AI想象一下,你只需要教 AI 读书(文字),它就能无师自通地看懂图片、听懂音频、理解视频。这听起来像魔法,但阿里达摩院最新推出的 LCO-EMB(Language-Centric Omnimodal E...多模态模型# LCO-EMB3周前0130