
脑科学研究长期受限于高昂的实验成本和缓慢的数据采集速度。功能性磁共振成像(fMRI)不仅需要昂贵的设备,还要求受试者长时间配合,且数据充满噪声。
- GitHub:https://github.com/facebookresearch/tribev2
- 模型:https://huggingface.co/facebook/tribev2
- Demo:https://aidemos.atmeta.com/tribev2
Meta FAIR 实验室推出了突破性成果——TRIBE v2。这是一个基于海量 fMRI 数据训练的人工智能模型,能够精准预测人类大脑对图像、声音和语言刺激的反应。令人惊讶的是,在多项测试中,TRIBE v2 的预测结果比任何单个真实受试者的扫描数据都更接近“典型的大脑反应模式”,仿佛它构建了一个通用的数字大脑孪生体。
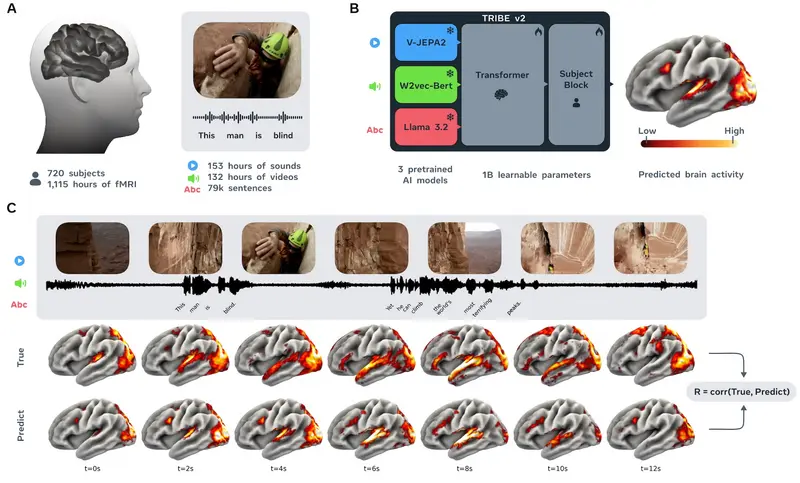
核心突破:比真人扫描更“标准”的预测
1. 噪声过滤与群体平均
真实的 fMRI 扫描深受心跳、头部微动和设备伪影的干扰,往往需要多次扫描取平均值才能看到清晰信号。
- TRIBE v2 的优势:它直接在由 720 名受试者、超过 1000 小时 的高质量 fMRI 数据上训练,学习的是“去噪后”的群体规律。
- 实测表现:在人类连接组项目(使用高场强 7T 扫描仪)的数据集中,TRIBE v2 的预测与群体平均响应的相关性,是普通个体受试者相关性的 两倍。这意味着,用 AI 预测可能比单独扫描一个人更准确、更稳定。
2. 复现数十年神经科学发现
研究人员用经典实验范式测试 TRIBE v2,结果令人惊叹:
- 视觉区定位:输入人脸图片,模型准确激活了已知的“梭状回面孔区”;输入场景图片,激活了“海马旁回位置区”。
- 语言网络:输入完整句子 vs 随机单词列表,模型完美复现了左半球语言区的更强激活模式。
- 痛觉区分:甚至能区分处理“情感痛苦”与“身体痛苦”的不同脑区。
- 意义:这证明 AI 已经内化了人类几十年的神经科学知识,未来的新假设可以先在“硅基大脑”中进行低成本模拟验证。
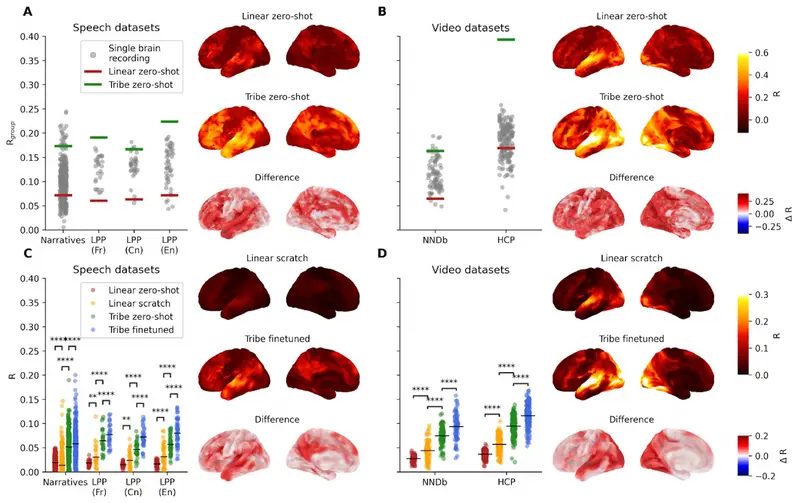
技术架构:三模态融合 Transformer
TRIBE v2 并非端到端黑盒,而是采用了精妙的模块化设计:
- 预处理层(专家编码):
- 文本 → Llama 3.2:提取语义嵌入。
- 音频 → Wav2Vec-Bert-2.0:捕捉声音特征。
- 视频 → Video-JEPA-2:理解视觉动态。
- 融合层(跨模态理解):
- 一个强大的 Transformer 将三种模态的表示对齐并融合,捕捉跨感官的复杂模式(如听到“狗叫”同时看到狗的画面)。
- 输出层(脑图谱映射):
- 特定于人的层将融合特征映射为包含 70,000 个体素(3D 像素) 的全脑活动图谱。
多感官协同效应
通过控制变量实验,TRIBE v2 揭示了大脑整合信息的奥秘:
- 单通道局限:仅用音频只能预测听觉皮层,仅用视频只能预测视觉皮层。
- 多通道增强:在颞叶、顶叶和枕叶交界处的多感官整合区,同时输入视频 + 音频 + 文本的预测准确度,比仅使用任一单通道高出 50%。
- 功能网络发现:统计分析自动聚类出五个已知功能网络:初级听觉、语言网络、运动识别、默认模式网络(DMN)和视觉系统。
局限与未来
尽管强大,TRIBE v2 仍有边界:
- 时间分辨率低:受限于 fMRI 原理,它无法捕捉毫秒级的神经电活动动态。
- 感官缺失:目前仅支持视、听、语,缺少嗅觉、触觉和本体感觉。
- 被动接收者:模型模拟的是大脑对刺激的“反应”,而非主动决策或行为驱动过程。
- 个体差异:虽然能预测群体模式,但在捕捉特定个体的发育变化或临床病理(如阿尔茨海默症)方面仍需改进。
开源与影响
Meta 已正式开源 TRIBE v2 的代码、模型权重及交互式演示。这将带来三大变革:
- 加速科研:神经科学家可在计算机上预演实验,大幅减少昂贵的真人扫描需求。
- 启发 AI:借鉴大脑的多模态整合机制,构建更高效、更像人类的下一代 AI 架构。
- 医疗潜力:未来或可用于辅助诊断脑部疾病,通过对比患者实际扫描与模型预测的差异来发现异常。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











