阿里达摩院、湖畔实验室和浙江大学的研究人员推出视频多模态大语言模型RynnEC,专为具身认知任务设计。它通过结合区域编码器和掩码解码器,能够灵活地处理视频中的区域级交互,从而为具身代理提供对物理世界的精细感知和交互能力。
| 模型 | 基础模型 | 下载地址 |
|---|---|---|
| RynnEC-2B | Qwen2.5-1.5B-Instruct | Alibaba-DAMO-Academy/RynnEC-2B |
| RynnEC-7B | Qwen2.5-7B-Instruct | Alibaba-DAMO-Academy/RynnEC-7B |
RynnEC 是一个为具身认知任务设计的视频多模态大语言模型。例如,如果你有一个机器人需要在室内环境中完成任务,如“找到最近的植物并将其移动到书架上”,RynnEC 可以通过理解视频输入和文本指令,准确地识别物体、理解空间关系,并生成相应的动作指令。
主要功能
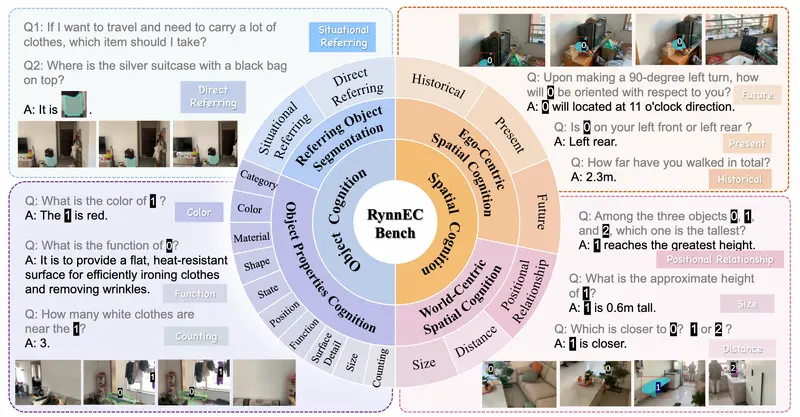
- 物体属性理解:RynnEC 能够理解物体的颜色、形状、材质、功能等属性。例如,它可以识别一个物体是“棕色的、光滑的塑料玩具”。
- 物体分割:RynnEC 可以根据自然语言描述分割视频中的目标物体。例如,根据指令“找到棕色的玩具”,它能够准确地分割出视频中的棕色玩具。
- 空间认知:RynnEC 能够理解物体之间的空间关系,包括相对位置、距离、高度等。例如,它可以回答“物体A是否在物体B的上方”或“物体A和物体B之间的距离是多少”。
- 轨迹回顾:RynnEC 能够回顾自身移动的轨迹,例如计算“我走了多远”。
- 运动想象:RynnEC 能够想象未来的运动路径,例如预测“如果我向左转90度,物体A将位于哪个方向”。
主要特点
- 紧凑架构:尽管 RynnEC 的参数量较小(7B参数),但它在物体属性理解、物体分割和空间认知等任务上达到了最先进的性能。
- 区域级交互:RynnEC 通过区域编码器和掩码解码器,能够灵活地处理视频中的区域级交互,提供更精细的视觉交互能力。
- 多任务训练:RynnEC 通过四阶段训练(掩码对齐、物体理解、空间理解、引用分割),逐步整合多种技能,确保模型在不同任务上的表现。
- 数据生成管道:为解决具身认知数据稀缺的问题,论文提出了一种基于第一人称视频的数据生成管道,能够从RGB视频生成具身认知问答数据集。
工作原理
RynnEC 的工作原理基于以下核心组件:
- 基础视觉语言模型:使用 VideoLLaMA3 作为基础模型,提供基本的多模态理解能力。
- 区域编码器:对视频中的特定物体进行编码,提供更精细的物体表示。
- 掩码解码器:根据模型的输出生成物体的分割掩码,实现精确的物体定位。
- 四阶段训练:通过掩码对齐、物体理解、空间理解和引用分割四个阶段逐步训练模型,确保模型在不同任务上的表现。
测试结果
在 RynnEC-Bench 基准测试中,RynnEC 在多个具身认知任务上表现出色:
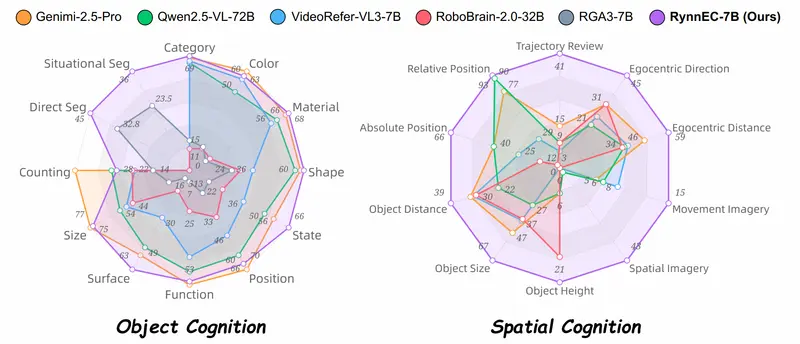
- 物体属性理解:得分 61.4,显著优于其他模型。
- 物体分割:在直接引用和情境引用分割任务上分别达到了 45.3%和 36.1%的准确率。
- 空间认知:得分 54.5,比其他模型高出 44.2%。
- 多任务能力:RynnEC 在多个任务上表现出色,证明了其在具身认知任务中的全面性和适应性。
应用场景
RynnEC 的应用场景非常广泛,包括但不限于:
- 机器人导航与操作:帮助机器人在复杂环境中导航、识别物体并执行任务。
- 智能助手:为智能助手提供更精细的视觉和空间理解能力,使其能够更好地协助用户完成任务。
- 虚拟现实与增强现实:在 VR 和 AR 应用中,RynnEC 可以提供更真实的环境感知和交互体验。
- 自动化任务执行:在工业和家庭环境中,RynnEC 可以协助完成各种自动化任务,如物品整理、清洁等。
总之,RynnEC 为具身认知任务提供了一个强大的多模态大语言模型,能够显著提升机器人和智能系统在物理世界中的感知和交互能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...