
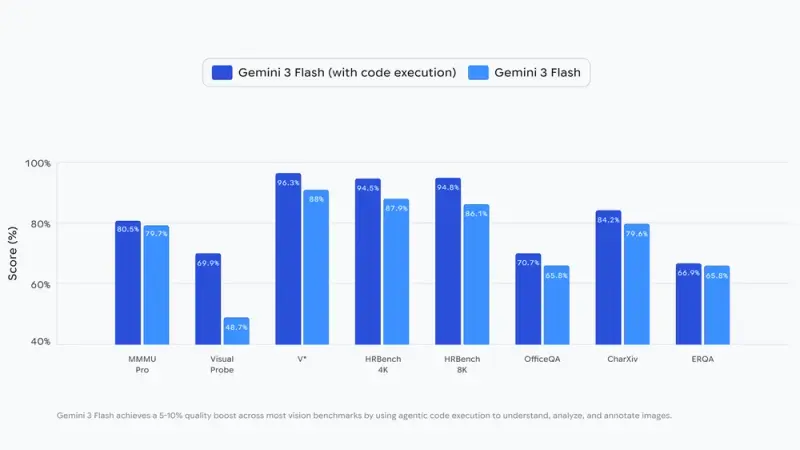
谷歌正式为 Gemini 3 Flash 推出全新能力——智能体视觉,通过将视觉推理与代码执行深度结合,让AI从“静态一瞥”升级为“主动调查”,彻底改变图像理解方式。这项功能可使多数视觉基准测试质量提升5-10%,目前已通过 Google AI Studio、Vertex AI API 及 Gemini 应用开放使用。

智能体视觉:从静态理解到主动调查的突破
传统前沿AI模型处理图像时,多依赖单一、静态的分析方式,若错过微芯片序列号、远处路牌等细粒度细节,只能依赖猜测。而 Gemini 3 Flash 的智能体视觉,将图像理解转化为“思考-行动-观察”的智能体循环过程,让答案基于扎实的视觉证据而非概率性推断。
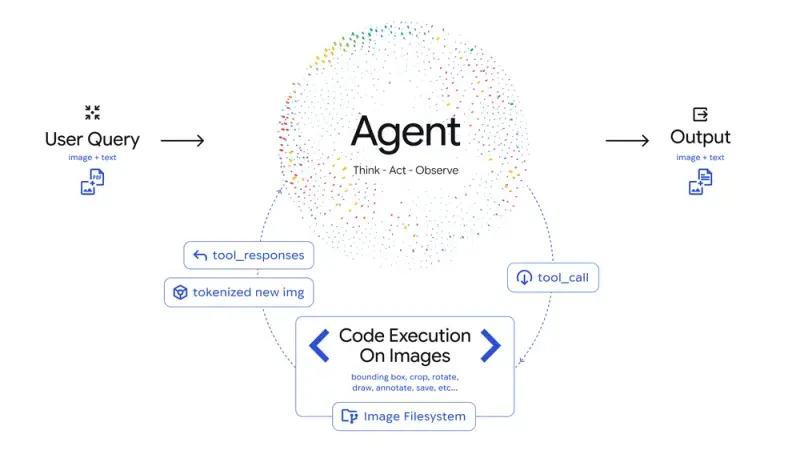
核心工作流程(智能体循环)
- 思考:模型接收用户查询与初始图像后,分析需求并制定多步骤视觉调查计划;
- 行动:生成并执行 Python 代码,主动对图像进行操作(如裁剪、旋转、标注)或分析(如计数边界框、运行数据计算);
- 观察:经处理后的图像被纳入模型上下文窗口,为后续推理提供更精准的视觉依据,最终生成可靠答案。
这一流程的核心优势在于“主动性”——模型不再被动接收图像信息,而是根据需求主动探索细节、验证假设,从根本上减少视觉任务中的错误与幻觉。
三大核心应用场景:解锁视觉任务新可能
智能体视觉已支持多种实用场景,开发者与企业可通过 API 集成,赋能各类视觉相关产品,以下为典型落地案例:
1. 放大检查:精准捕捉细粒度细节
Gemini 3 Flash 经训练可自动识别细粒度细节,并通过代码执行隐式放大分析。
例如,AI 驱动的建筑平面图验证平台 PlanCheckSolver.com,通过启用智能体视觉,迭代检查高分辨率建筑图纸:模型生成 Python 代码,裁剪屋顶边缘、建筑结构等关键区域并单独分析,再将结果反馈至上下文窗口,最终使验证准确性提升5%,完美适配复杂建筑规范的核验需求。
2. 图像标注:可视化推理过程,避免出错
智能体视觉允许模型通过代码与图像交互,直接在图像上标注推理依据,让结果可追溯、可验证。
典型场景如“数手指数量”:模型不会仅凭视觉判断给出答案,而是通过 Python 代码在每个识别到的手指上绘制边界框与数字标签,形成“视觉便签板”,确保计数结果基于像素级的精确识别,彻底杜绝计数错误。
3. 视觉数学与绘图:告别计算幻觉,结果可验证
面对高密度表格、多步骤视觉算术等任务,传统大模型易产生计算幻觉,而智能体视觉通过代码执行将计算卸载到确定性环境,完美解决这一问题。
在 Google AI Studio 演示案例中,模型可自动识别图像中的原始数据,编写 Python 代码将历史最优结果(SOTA)归一化为1.0,再通过 Matplotlib 生成专业条形图,用可验证的代码执行取代概率性猜测,确保数据可视化与计算结果的准确性。
未来展望:更智能、更多工具、更全模型覆盖
目前智能体视觉仍处于快速迭代阶段,Google 计划从三方面持续升级:
- 更多隐式代码驱动行为:当前模型已能自动决定何时放大微小细节,未来将让旋转图像、视觉数学运算等行为完全隐式化,无需用户明确提示即可触发;
- 扩展工具生态:计划为模型配备网络搜索、反向图像搜索等更多工具,进一步夯实对真实世界的视觉理解能力;
- 覆盖全模型规模:除 Gemini 3 Flash 外,后续将把智能体视觉扩展到其他规模的 Gemini 模型,满足不同场景的使用需求。
快速上手:如何使用智能体视觉
1. 访问渠道
- 开发者:通过 Google AI Studio 或 Vertex AI 调用 Gemini API 启用;
- 普通用户:在 Gemini 应用中,通过模型下拉菜单选择“Thinking”即可体验(逐步推送中)。
2. 启用步骤(AI Studio 示例)
- 打开 AI Studio Playground;
- 在“工具”选项中,开启“代码执行”功能;
- 上传图像或输入包含视觉需求的查询,模型将自动触发智能体视觉流程。
3. 参考资源
可查阅 Vertex AI 开发者文档,了解 API 集成细节与进阶用法,快速将智能体视觉融入自身产品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











