苹果近期发布了 FastVLM系列视觉语言模型,并首次引入其自研混合视觉编码器 FastViTHD。该模型解决当前多模态系统在处理高分辨率图像时面临的效率瓶颈,尤其在移动端和实时交互场景中展现出显著优势。
- GitHub:https://github.com/apple/ml-fastvlm
- 模型:https://huggingface.co/collections/apple/fastvlm-68ac97b9cd5cacefdd04872e
FastVLM 不是简单地堆叠更大参数的模型,而是从架构设计与训练方法入手,重新思考视觉编码的效率问题——如何在不牺牲性能的前提下,大幅降低计算开销,让视觉语言模型真正“跑得快、看得清”。
为什么需要更快的视觉编码?
视觉语言模型(VLMs)已被广泛应用于图像描述、视觉问答(VQA)、文档理解等任务。它们的工作流程通常分为两步:
- 视觉编码:将输入图像转换为一系列“视觉 token”
- 语言生成:由大语言模型(LLM)基于这些 token 生成文本响应
其中,视觉编码阶段是性能瓶颈的关键所在。
传统 Vision Transformer(ViT)类编码器在面对高分辨率图像(如 1152×1152 或更高)时,会生成大量 token(例如数千个),导致:
- 编码时间显著增加
- 内存占用高
- 首 token 延迟(TTFT, Time to First Token)变长
这对需要即时反馈的应用(如手机拍照问答、AR交互)极为不利。
核心突破:FastViTHD 混合编码器
FastVLM 的核心在于其新设计的视觉编码器——FastViTHD,一种结合卷积与 Transformer 的混合架构,专为高效处理高分辨率图像而生。
主要创新点:
| 特性 | 说明 |
|---|---|
| 混合架构 | 前段使用轻量卷积层进行下采样和局部特征提取,后段接入 Transformer 块处理全局语义,兼顾速度与表达能力 |
| 更少的输出 token | 相比标准 ViT,FastViTHD 显著减少最终输出的视觉 token 数量,降低后续 LLM 的处理负担 |
| 多尺度特征融合 | 在不同网络层级提取特征,增强对细节(如文字、图表)的捕捉能力,提升文档类任务表现 |
| 动态分辨率支持 | 支持灵活输入分辨率,通过分块(tiling)策略独立处理图像区域,再合并结果,实现高分辨率下的高效推理 |
这一设计使得 FastViTHD 在保持甚至超越现有模型性能的同时,极大压缩了编码延迟和模型体积。
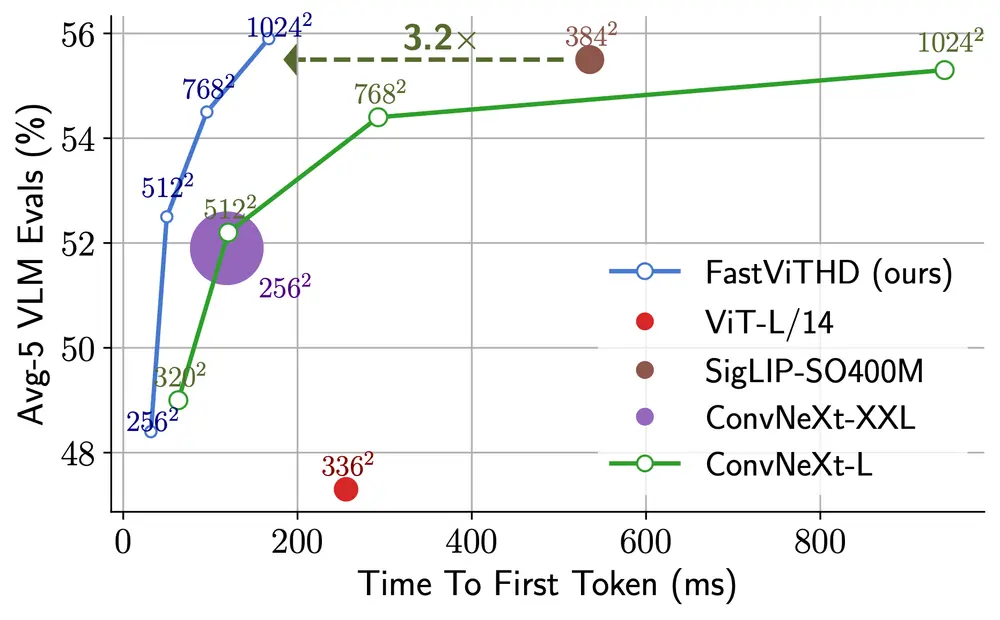
性能对比:不只是快,而且更强
FastVLM 提供多个变体,在不同规模下均展现出压倒性效率优势:
小模型表现(FastVLM-0.5B)
- 使用 Qwen2-0.5B 作为语言主干
- 相比 LLaVA-OneVision-0.5B
- 首 token 时间(TTFT)快 85 倍
- 视觉编码器体积小 3.4 倍
- 在 SeedBench、MMMU、DocVQA 等基准上性能持平或更优
这意味着:一张 1152×1152 的图片,FastVLM 几乎可以“秒级”完成编码并开始生成回答,而同类模型可能需数秒等待。
大模型表现(FastVLM-7B)
- 搭载 Qwen2-7B LLM
- 相比近期作品如 Cambrian-1-8B
- 使用单一图像编码器(非多编码器架构)
- TTFT 快 7.9 倍
- 无需复杂级联结构即可实现高效推理
这表明 FastVLM 并未依赖“堆硬件”或“多编码器并行”来提速,而是通过架构优化实现了本质性效率跃升。
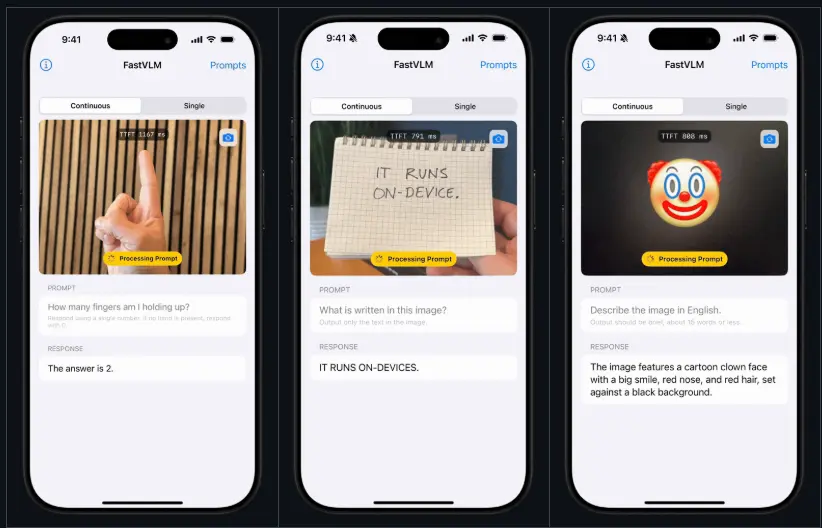
移动端实测:iOS 应用演示落地能力
苹果同步推出了一款 iOS 演示应用,用于展示 FastVLM 在移动设备上的运行效果。
在 iPhone 上:
- 模型可在本地完成图像编码与响应生成
- 用户上传高分辨率照片后,系统迅速返回图文回答
- 整体交互流畅,无明显卡顿或等待
这验证了 FastVLM 架构具备良好的端侧部署潜力,为未来集成至 Siri、相机助手、Notes 文档解析等功能提供了技术基础。
实验验证:效率与性能兼得
FastVLM 在多个权威多模态评测集上进行了测试:
| 任务 | 表现 |
|---|---|
| SeedBench | 在视频理解与时空推理任务中达到先进水平 |
| MMMU | 数学图表理解能力优于多数现有模型 |
| DocVQA | 文档图像问答准确率高,尤其擅长表格与手写体识别 |
值得注意的是,随着视觉指令微调数据量增加,FastVLM 的性能持续提升,显示出良好的可扩展性与训练稳定性。
技术原理简析
FastVLM 的高效源于三个关键设计:
- 分阶段处理机制
- 卷积层快速压缩空间维度,减少 token 数
- Transformer 层聚焦语义建模,避免全图高分辨率注意力开销
- 多尺度特征整合
- 在多个下采样层级提取特征,保留边缘、纹理、结构等多层次信息
- 更适合细粒度任务(如 OCR、图表解析)
- 动态分块编码(Tiled Encoding)
- 将大图切分为小块,分别编码后再融合
- 支持任意分辨率输入,内存占用可控
这套机制使其既能处理手机截图、扫描文档,也能应对专业级图像输入。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











