
苹果近期推出了新一代轻量级图像-文本模型家族 —— MobileCLIP2,在保持高精度的同时,显著降低模型体积与推理延迟,专为移动设备上的实时多模态理解任务而设计。
- GitHub:https://github.com/apple/ml-mobileclip
- 模型:https://huggingface.co/collections/apple/mobileclip2-68ac947dcb035c54bcd20c47
这不是一次简单的参数压缩或剪枝优化,而是一套从训练数据、教师模型到蒸馏策略的系统性升级。MobileCLIP2 通过多模态强化训练,在零样本分类、跨模态检索和下游任务中展现出媲美甚至超越大型模型的性能,同时在 iPhone 上实现毫秒级响应。
什么是 MobileCLIP?为什么需要它?
CLIP 类模型的核心能力是将图像和文本映射到同一语义空间:一张猫的照片会靠近“一只坐在窗台上的猫”这样的描述,而远离“汽车”或“飞机”。
但标准 CLIP 模型(如 ViT-L/14)通常参数庞大、计算成本高,难以部署在手机等资源受限设备上。
MobileCLIP 的目标很明确:
在移动设备上实现接近大模型的语义理解能力,同时满足低延迟、小体积、低功耗的要求。
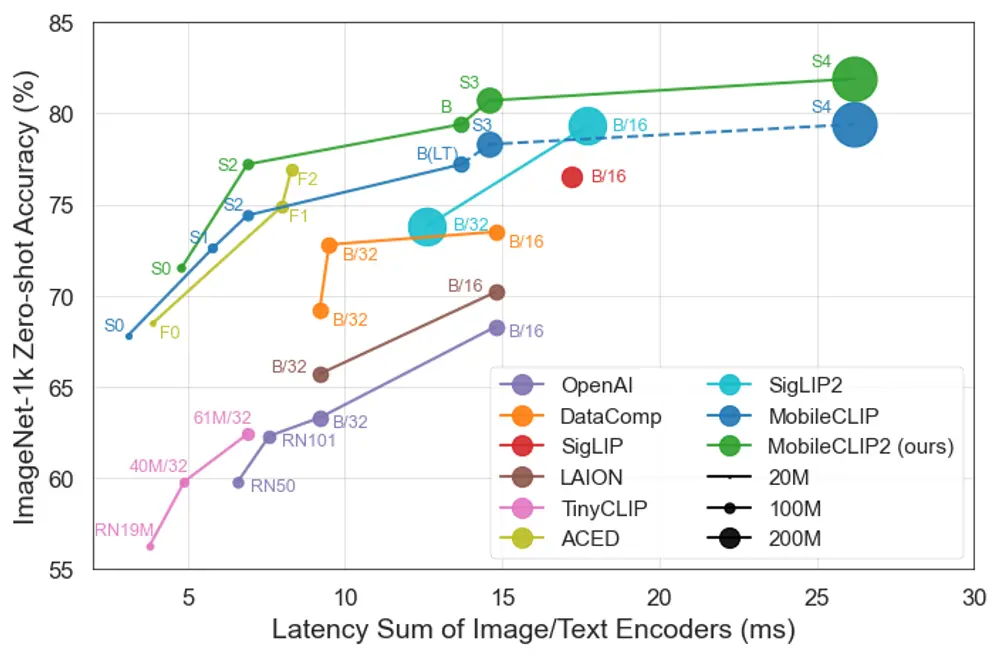
MobileCLIP2 是该系列的最新迭代,通过改进训练方法与架构设计,在多个维度实现了突破。
关键性能表现:快、小、准
| 模型 | 对比对象 | 成果 |
|---|---|---|
| MobileCLIP2-S4 | SigLIP-SO400M/14 | 精度相当,参数减少 2倍,在 iPhone12 Pro Max 上延迟降低 2.5倍 |
| MobileCLIP-S0 | OpenAI ViT-B/16 | 零样本性能相当,速度快 4.8倍,模型小 2.8倍 |
| MobileCLIP-S2 | SigLIP ViT-B/16 | 性能更优,速度快 2.3倍,模型小 2.1倍,训练样本少 3倍 |
| MobileCLIP-B (LT) | DFN、SigLIP、ViT-L/14@336 | 零样本 ImageNet 达 77.2%,超越同类架构 |
这些数字背后意味着:
✅ 更快的图像理解响应
✅ 更少的内存占用
✅ 更低的电池消耗
✅ 更适合端侧部署
苹果还同步推出 iOS 演示应用,直观展示了模型在设备本地完成图像-文本匹配的速度与准确性,无需联网即可运行。
技术核心:多模态强化训练
MobileCLIP2 并非从头训练,而是采用“学生-教师”框架下的多模态知识蒸馏策略,其核心思想是:
利用多个高性能预训练模型作为“教师”,指导一个轻量级“学生”模型学习高质量的跨模态表示。
这一过程包含四个关键环节:
1. 高质量训练数据:DataCompDR-1B
- 基于 DFN 数据集构建
- 经过过滤与去噪处理,提升图像-文本对的整体质量
- 支持模型在更干净、更具代表性的数据上训练
2. 更强的教师模型:DFN 训练的 CLIP 模型
- 使用在大规模 DFN 数据上训练的 CLIP 模型作为主教师
- 提供更准确的图像与文本嵌入,作为蒸馏目标
- 多个教师模型集成,进一步提升监督信号的鲁棒性
3. 多样化的合成字幕生成器
- 采用 CoCa 模型生成额外的合成字幕
- 增强文本描述的多样性(例如同一张图生成“狗在草地上奔跑”和“一只金毛犬正在玩耍”)
- 提高学生模型对不同表达方式的理解能力
4. 优化的知识蒸馏流程
- 采用对比知识蒸馏(Contrastive Knowledge Distillation)
- 调整温度参数(temperature scaling),使软标签分布更平滑,利于小模型学习
- 图像与文本双塔结构同步蒸馏,确保双向对齐质量
这套流程让 MobileCLIP2 能够“站在巨人肩膀上”,用更少的数据、更小的模型,学到更强的语义能力。
实验结果:全面验证有效性
✅ 零样本图像分类(ImageNet-1k)
- MobileCLIP2-S4 达到与 SigLIP-SO400M/14 相当的准确率
- 但模型更小、推理更快,尤其在移动端优势明显
✅ 多模态理解任务(LLaVA-1.5 设置)
在 GQA(视觉问答)、SQA(科学问答)、TextVQA(含文本图像问答)、POPE(幻觉评估)、MMMU(多模态理解)等任务中:
- MobileCLIP2 提供的视觉编码器表现优异
- 有助于提升整体 VLM 系统的准确率与鲁棒性
✅ 密集预测任务
在对象检测、语义分割、深度估计等需要像素级理解的任务中:
- 使用 MobileCLIP2 预训练的 backbone 表现优于仅用监督学习预训练的模型
- 表明其学到的特征具有良好的迁移能力
🛠️ 架构设计:为移动端而生
MobileCLIP2 系列包含多个变体(S0 ~ S4, B),覆盖不同性能需求场景:
- S0-S2:超轻量级,适用于低端设备或高帧率应用(如实时摄像头分析)
- S4:平衡型,兼顾精度与速度,适合主流机型
- B (LT):大容量版本,追求更高零样本性能,仍保持端侧可运行
所有模型均针对 iOS 设备进行优化:
- 支持 Core ML 加速
- 可在 A 系列芯片上高效运行
- 内存占用低,支持长时间后台运行
应用前景
MobileCLIP2 的能力可直接赋能多种实际功能:
- 照片搜索增强:用户输入“去年夏天在海边拍的全家福”,系统快速定位相关图像
- 无障碍辅助:为视障用户提供实时图像描述
- 智能相册分类:自动识别场景、物体、活动类型,无需手动打标签
- AR 交互理解:结合摄像头流,实时解析环境内容并生成回应
- Siri 视觉扩展:支持“这张发票多少钱?”、“这个植物叫什么?”等视觉问答
更重要的是,它证明了:轻量模型也能具备强大的语义理解能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











