字节跳动开源 BitDance:14B 参数自回归模型,生成速度超越扩散模型 30 倍在 AI 绘画领域,长期存在着“画质”与“速度”的博弈,以及“扩散模型”与“自回归模型”的路线之争。扩散模型(如 Stable Diffusion)画质优异但推理步骤繁琐;自回归模型(类似 LLM 生...图像模型# BitDance# 字节跳动# 自回归模型1个月前02080
派拉蒙与迪士尼接连发函,指控字节跳动旗下Seedance 2.0侵犯影视 IP继迪士尼之后,派拉蒙天空之舞(Paramount Skydance)也正式向字节跳动发出法律停止函,指控其旗下 AI 生成平台 Seedance 视频 和 Seedream 图像 “公然侵犯”其知识产...早报# 字节跳动# 派拉蒙# 迪士尼1个月前01640
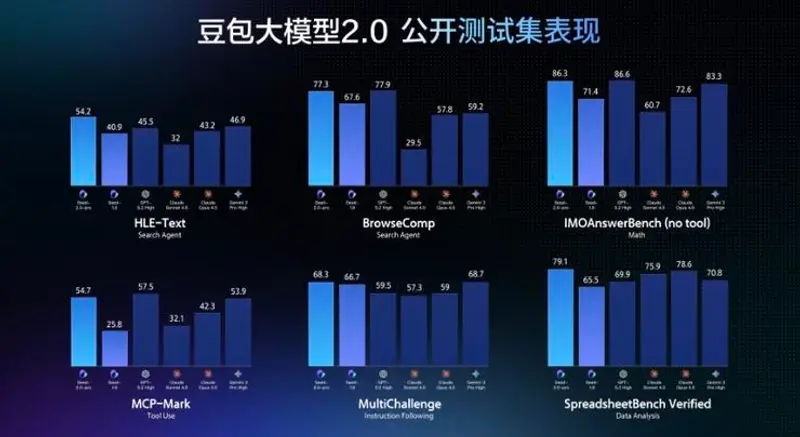
字节跳动发布豆包大模型2.0:数学推理顶尖,复杂任务执行强,API价格仅为竞品五分之一继 Seedance 2.0 视频模型和 Seedream 5.0 Lite 图像模型后,字节跳动于 2 月 14 日正式推出 豆包大模型 2.0(Doubao-Seed-2.0)系列。新版本针对大规...大语言模型早报# Doubao-Seed-2.0# 字节跳动# 豆包大模型2.02个月前0300
复杂运动、多模态参考、双声道音频!字节跳动正式发布Seedance 2.0:统一多模态架构, 支持导演级编辑的工业级音视频生成字节跳动正式推出新一代视频创作模型 Seedance 2.0。作为迭代升级后的重磅版本,它采用全新统一的多模态音视频联合生成架构,全面支持文本、图片、音频、视频四种模态输入,集成了当前行业内覆盖面最广...早报视频模型# Seedance 2.0# 字节跳动2个月前0160
字节跳动旗下 AI 编程助手Trae 一周年福利:免费领 600~800 次「超快请求」额度字节跳动旗下 AI 编程助手 Trae 迎来上线一周年。为感谢用户支持,官方推出限时周年庆活动:登录 Trae 国际版,即可免费领取额外「Fast Request」(快速请求)额度,用于加速代码生成与...早报# AI 编程助手# Trae# 字节跳动2个月前0320
Dolphin-v2:字节跳动发布支持21类元素的通用文档解析模型在办公自动化、知识管理与智能体工作流中,将非结构化文档转化为结构化数据是关键第一步。然而,现实中的文档来源复杂:既有干净的 PDF、Word,也有手机拍摄的带畸变、阴影、模糊的纸质文件。现有解析模型往...多模态模型# Dolphin-v2# 字节跳动# 文档解析模型4个月前01570
字节跳动发布Vidi2:攻克细粒度时空定位,视频检索性能领先GPT - 5字节跳动智能创作团队推出的第二代多模态视频模型Vidi2,凭借在时空定位、时间检索和视频问答三大核心能力上的突破,打破了传统视频模型在长视频理解和精细交互上的局限。该模型不仅在核心任务中实现对Gemi...多模态模型# Vidi2# 多模态视频模型# 字节跳动4个月前01960
Self-Forcing++:一种无需长视频训练即可生成高质量长视频的新方法近年来,扩散模型在图像和短片视频生成方面取得了突破性进展。然而,当扩展到长视频生成(如数十秒甚至数分钟)时,现有方法普遍面临一个核心问题:质量随长度增加而显著下降。 这主要源于两个限制: 计算成本高...新技术# Self Forcing# 字节跳动6个月前03260
字节跳动发布统一加速多模态理解与生成的新框架Hyper-Bagel随着多模态大模型在图文理解、文本到图像生成、图像编辑等任务中表现日益强大,其高昂的推理成本也逐渐成为落地瓶颈。传统的自回归解码与扩散去噪过程需要大量迭代计算,在长上下文或多轮交互场景下响应迟缓。 为此...图像模型# Hyper-Bagel# 字节跳动6个月前03140
Lynx:字节跳动提出的单图驱动个性化视频生成方案,实现高保真身份保留在内容创作、虚拟社交等场景中,“基于单张图像生成个性化视频”是重要需求——比如用一张自拍生成动态表情视频,或让历史人物照片“动起来”讲述故事。但这类任务长期面临核心挑战:如何在保证视频自然流畅的同时...视频模型# Lynx# 个性化视频生成# 字节跳动6个月前02740
字节跳动提出OmniInsert:无需遮罩,任意对象都能自然插入视频在影视后期、广告制作乃至虚拟内容创作中,“将一个新角色或物体自然地加入已有视频”是一项高频需求。传统方法依赖精确的遮罩标注、关键帧追踪和复杂的合成流程,成本高、耗时长。 近期,基于扩散模型的技术为这一...视频模型# OmniInsert# 字节跳动# 视频编辑6个月前01600
字节跳动发布OneReward 框架:用单一奖励模型革新多任务图像编辑在图像生成领域,AI 已经能完成许多复杂操作:补全残缺画面、扩展图像边界、移除干扰物体,甚至在图中添加可读文本。但这些任务通常由不同模型分别处理——每个任务有自己的训练流程、评估标准和奖励机制。 这带...图像模型# FLUX.1-Fill-dev-OneReward# OneReward# 字节跳动7个月前03450