近年来,扩散模型在图像和短片视频生成方面取得了突破性进展。然而,当扩展到长视频生成(如数十秒甚至数分钟)时,现有方法普遍面临一个核心问题:质量随长度增加而显著下降。
这主要源于两个限制:
- 计算成本高:主流方案依赖 Transformer 架构,处理长序列时内存与算力需求急剧上升;
- 训练视界短:教师模型通常只能生成几秒的视频片段,在指导学生模型外推更长时间时,容易引发错误累积、画面冻结、过曝等问题。
为解决这一挑战,来自加州大学洛杉矶分校、字节跳动 Seed 项目组和中佛罗达大学的研究团队提出 Self-Forcing++ ——一种简单但高效的自回归长视频生成方法。
- 项目主页:https://self-forcing-plus-plus.github.io
- GitHub:https://github.com/justincui03/Self-Forcing-Plus-Plus
该方法无需使用长视频数据集重新训练,也无需依赖能直接生成长视频的教师模型,却能在保持时间一致性的同时,将生成长度扩展至基础模型位置嵌入支持的最大跨度——长达4分15秒(255秒),相当于原始模型能力的 99.9%,比基线模型长 50倍以上。

核心思想:用“自己生成的内容”来训练自己
Self-Forcing++ 的关键洞察是:即使教师模型无法生成长视频,它仍具备丰富的局部时空知识。因此,研究者设计了一种“自我强化”的蒸馏机制:
- 学生模型先生成一段长视频;
- 将其切分为多个短片段;
- 每个片段交由短视界双向扩散教师模型进行精炼(去噪与修复);
- 再将这些被修正的片段作为监督信号,反向蒸馏回学生模型。
这个过程类似于“写完一篇文章后,请专家逐段批改,再根据反馈优化全文”,从而实现对长序列的渐进式优化。
💡 关键优势:整个流程不依赖真实长视频数据,也不需要重新训练教师模型。
技术亮点:高效、稳定、可扩展
✅ 滚动 KV 缓存,避免重复计算
不同于此前方法需反复重算重叠帧(导致延迟高、易过曝),Self-Forcing++ 在推理阶段采用滚动键值缓存(Rolling KV Cache),仅更新新增帧的注意力状态,大幅降低计算开销,并提升视觉稳定性。
✅ 分布匹配蒸馏(DMD),缓解误差累积
传统蒸馏关注逐像素对齐,容易放大噪声。Self-Forcing++ 引入分布匹配策略,使学生模型学习的是“如何从退化状态恢复”,而非简单模仿输出,增强了鲁棒性。
✅ 无需沉没帧或复杂调度
相较 Rolling Forcing 和 LongLive 等并发工作需引入沉没帧(sinking frames)或动态噪声调度,Self-Forcing++ 完全基于历史 KV 缓存运作,结构更简洁,部署更友好。
✅ 支持强化学习优化(GRPO)
为进一步提升运动连贯性,团队引入基于光学流的 Group Relative Policy Optimization (GRPO),通过奖励平滑运动和合理动态变化,优化生成质量。
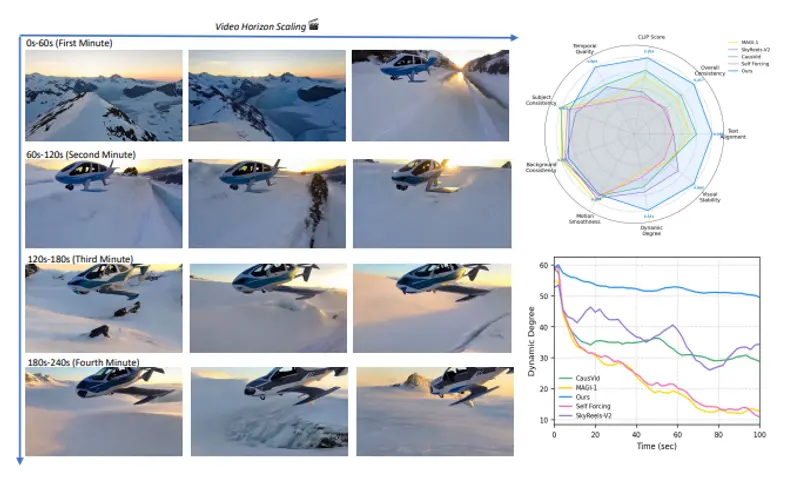
实验结果:接近理论极限的长视频生成
| 指标 | 表现 |
|---|---|
| 最大生成长度 | 255 秒(4分15秒) |
| 相对于基线长度提升 | 超 50 倍 |
| 时间一致性(MOS) | 显著优于 Rolling Forcing、LongLive |
| 文本对齐(CLIPSIM) | 100s 视频下达 26.04,领先同类方法 |
| 动态程度(VMF) | 100s 视频下为 54.12,体现丰富动作表现力 |
在标准基准(如 T2V-Bench)和团队自建的长视频保真度与一致性基准上,Self-Forcing++ 在保真度、语义对齐和视觉稳定性方面均显著优于现有方法。
尤其值得注意的是,在生成超过 100 秒的视频时,基线模型常出现画面停滞、色彩漂移或结构崩塌,而 Self-Forcing++ 能持续保持合理的物理运动与场景演进。
与其他方法对比
| 方法 | 是否需长视频数据 | 是否需沉没帧 | KV 缓存机制 | 最大生成长度 |
|---|---|---|---|---|
| Rolling Forcing | 否 | 是 | 重计算重叠帧 | ~60s |
| LongLive | 否 | 是 | KV 重缓存 | ~90s |
| Self-Forcing++ | 否 | 否 | 滚动 KV 缓存 | 255s |
可以看出,Self-Forcing++ 在保持架构简洁的同时,实现了最长的生成跨度和更高的稳定性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...