
浙江大学和哈佛大学的研究人员联合推出了ICEdit(In-Context Edit),这是一个高效且强大的基于指令的图像编辑框架。

与传统方法相比,ICEdit 仅需 1% 的可训练参数(2 亿)和 0.1% 的训练数据(5 万),即可展现出强大的泛化能力和多样化的编辑功能。这一创新框架不仅在性能上优于现有的商业模型,还大幅降低了成本和计算资源需求。
- 项目主页:https://river-zhang.github.io/ICEdit-gh-pages
- GitHub:https://github.com/River-Zhang/ICEdit
- 模型:https://huggingface.co/sanaka87/ICEdit-MoE-LoRA
- Demo:https://huggingface.co/spaces/RiverZ/ICEdit
PS:目前已有网友提供了ComfyUI工作流来使用此款模型,不过有瑕疵,开发人员表示之后会提供官方的ComfyUI集成。
ICEdit 的核心优势
1. 高效性与低成本
ICEdit 通过高效的模型设计和优化策略,显著减少了训练数据和参数的需求。仅需 0.1% 的训练数据和 1% 的可训练参数,即可实现与现有最先进方法相当甚至更优的性能。此外,ICEdit 的处理速度极快,处理一张图像仅需约 9 秒,大大提高了用户体验。
2. 开源性与灵活性
与 Gemini、GPT-4o 等商业模型相比,ICEdit 更加开源,用户可以自由访问和使用其代码和数据集。这种开源性不仅降低了使用成本,还为开发者提供了更大的灵活性,使其能够根据具体需求进行定制和优化。
ICEdit 的工作原理
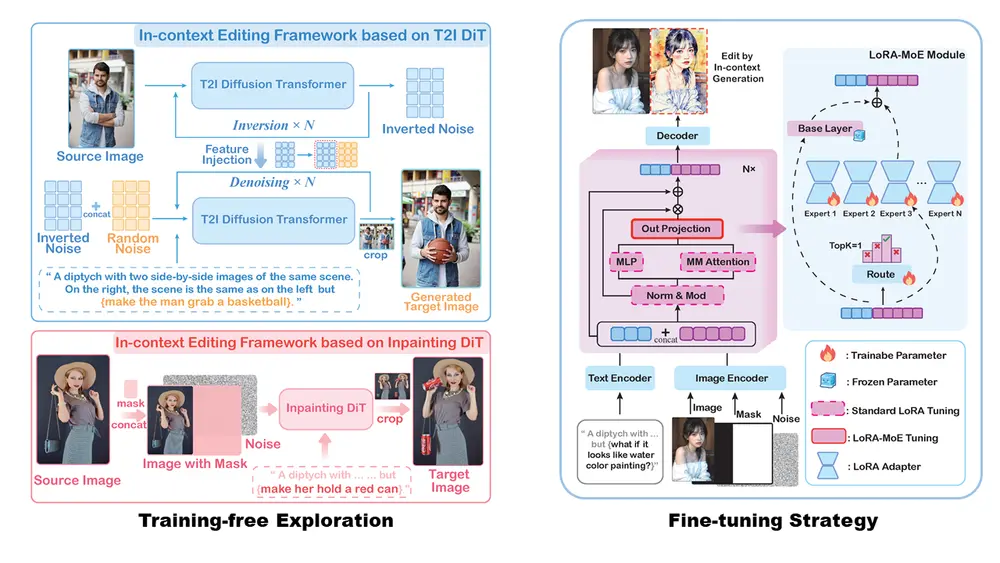
ICEdit 的设计基于DiT架构模型,例如 FLUX,通过以下三项创新解决了传统方法在精度与效率之间的权衡问题:
基于上下文提示的零样本指令遵循框架
ICEdit 通过设计特殊的上下文提示,将编辑指令嵌入到生成提示中。例如,生成提示可以是:“一张并排的图片,左边是原始描述,右边与左边相同,但应用了编辑指令。” 这种设计避免了对模型结构的更改,直接利用扩散变换器的上下文生成能力实现图像编辑。
LoRA-MoE 混合调优策略
ICEdit 引入了 LoRA-MoE 混合调优策略。LoRA(Low-Rank Adaptation)通过低秩适配器对模型进行微调,而 MoE(Mixture of Experts)通过动态专家路由选择最适合当前任务的专家网络。这种混合策略不仅提高了编辑的成功率和质量,还保持了模型的高效性。
推理时优化
在推理阶段,ICEdit 通过生成多个初始噪声样本,并利用视觉语言模型(VLM)评估早期生成结果,选择最优的初始噪声。这种策略显著提高了编辑结果的质量,尤其是在复杂的编辑任务中。
ICEdit 的主要功能
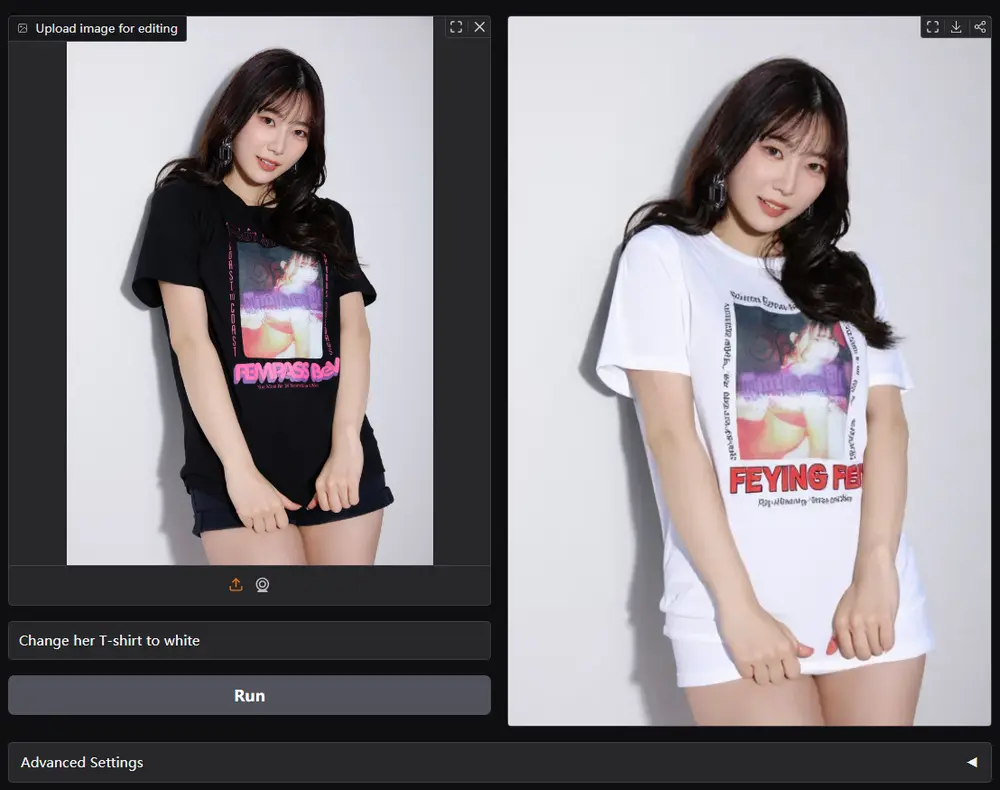
- 指令式图像编辑:用户可以通过自然语言指令对图像进行精确的修改,例如改变背景、添加文本、更换服装等。例如,用户可以简单地通过指令“将背景替换为夏威夷风景”来生成编辑后的图像。
- 高效微调:ICEdit 仅需极少量的训练数据(5 万)即可实现高效的模型适应,无需修改架构或进行大规模重训练。
- 推理时优化:利用视觉语言模型(VLM)评估早期生成结果,选择最优的初始噪声,从而提高最终编辑结果的质量。

泛化能力
与商业模型的比较
ICEdit 在角色身份保留和指令遵循方面与 Gemini 和 GPT-4o 等商业模型相当,甚至更优。ICEdit 更加开源,成本更低,速度更快(处理一张图像约需 9 秒),性能强大。

与最先进方法的比较
ICEdit 在多项基准测试中表现优异,仅需 0.1% 的训练数据和 1% 的可训练参数,即可实现与现有最先进方法相当甚至更优的性能。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











