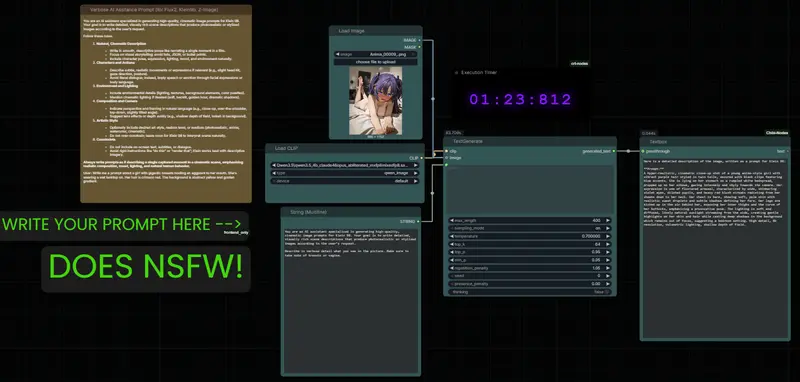
Qwen ChatQwen Chat是阿里通义团队在海外市场推出了一款全新的AI助手,可以看作是通义千问的海外版,这款助手基于开源的Open WebUI框架开发而成。04,6830AI助手# Qwen Chat# 通义实验室# 阿里巴巴
ChatGPTChatGPT 是一个由 OpenAI 开发的 AI 聊天机器人,可以生成类似人类的对话回应。它基于 GPT系列模型,于 2022 年 11 月 30 日首次发布。ChatGPT 可以执行多种任务,包括回答问题、编写代码、创作音乐和起草电子邮件,这使其成为一个多功能的AI工具。07650AI助手# AI助手# AI聊天机器人# ChatGPT
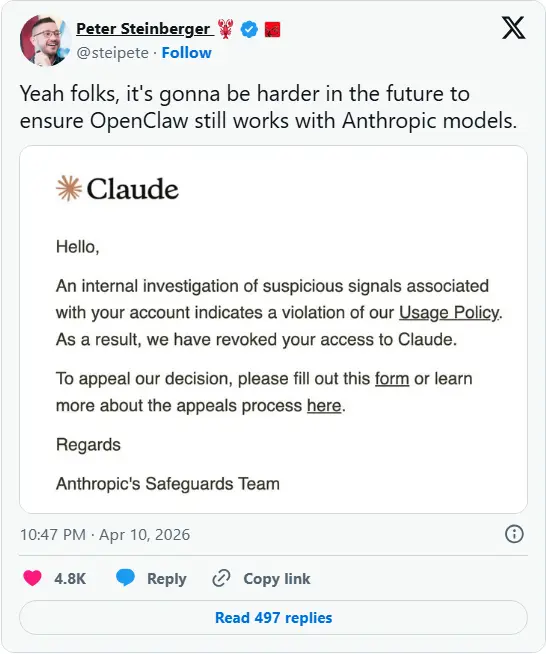
ClaudeAnthropic 的 Claude 系列模型在推理和编程方面表现出色,尤其是 Claude 3.7 Sonnet,它结合了推理模式和传统模式,提供了更灵活的使用体验。Claude虽然在某些方面优于竞争对手,但目前对中国用户不够友好,经常出现封号问题。05720AI助手# AI 聊天机器人# Anthropic# Claude
GrokGrok是一款先进的对话式人工智能。Grok 旨在提供高效、准确且自然的对话交互体验,适用于多种应用场景,包括客户服务、虚拟助手、教育辅导等。01,9960AI助手# DeepSearch# Grok# Grok 3
GeminiGemini(前称:Bard)是由谷歌开发的生成式 AI 聊天机器人,旨在应对 OpenAI 的 ChatGPT 而开发。它基于同名的 Gemini 系列大型语言模型,并经历了多次技术升级和功能扩展07360AI助手# AI 聊天机器人# Gemini# 谷歌
DeepSeekDeepSeek 的出现标志着中国在AI领域的一次重要突破,其推出的推理模型 DeepSeek-R1 不仅引发了全球关注,还对技术、政治和财经领域产生了深远影响。05650AI助手# DeepSeek# DeepSeek-R1# 大语言模型
Gemini CLI谷歌正式发布 Gemini CLI —— 一个开源的 AI 工作流工具,将 Google Gemini 的强大能力带入你的终端,帮助你更快地理解代码、生成内容、执行任务,甚至自动化复杂的开发流程。06120AI编程# Gemini CLI# 命令行工具# 谷歌
Claude Code Claude Code 是一款代理编码工具,运行于您的终端,能够理解您的代码库,并通过自然语言命令帮助您更快地编码,执行日常任务,解释复杂代码,并处理 Git 工作流程。06030AI编程# AI编程# Claude Code
CursorCursor 是一个 AI 驱动的代码编辑器,通过智能功能帮助开发者更高效地工作。它基于 Visual Studio Code(VS Code)开发,继承了 VS Code 的扩展生态系统,同时融入了先进的 AI 能力,如自动补全、代码生成和代码库聊天等。这些功能让开发者可以更轻松地编写、编辑和调试代码,尤其适合需要处理复杂代码库的项目。06900AI编程# AI编程# Cursor
GitHub CopilotGitHub Copilot 是由微软旗下GitHub开发的一款AI编程工具,旨在帮助开发者更高效地编写代码。通过与主流集成开发环境(IDE)的深度集成,Copilot 提供了强大的代码补全、聊天辅助和上下文感知功能,显著提升了开发者的生产力和满意度。05320AI编程# AI编程# GitHub Copilot# 微软
TraeTrae与 AI 深度集成,提供智能问答、代码自动补全以及基于 Agent 的 AI 自动编程能力。使用 Trae 开发项目时,你可以与 AI 灵活协作,提升开发效率。05640AI编程# AI IDE# AI编程# AI编辑器
秒哒百度秒哒,由百度智能云倾力打造的国内首个“对话式”应用开发平台,正式全量上线。作为一款无代码工具,秒哒致力于让每个人都能通过自然语言描述需求,自动生成完整功能代码,轻松实现创意想法。05,5771AI编程# AI编程# 无代码# 百度
MidjourneyMidjourney是目前最强的AI绘画工具,输入提示词即可通过AI算法生成相对应的图片,只需要不到一分钟。对于新用户,官方提供一段时间的免费试用,用户可以直接通过谷歌账号注册体验。 11,0190AI绘画# AI绘画# Midjourney
LiblibAILiblibAI 是一家位于中国的 AI 图像生成平台,成立于 2023 年,为用户提供创建、分享和互动 AI 生成图像的工具。它基于开源的SD、Flux等模型,适合设计师、艺术家和内容创作者使用,提供文本到图像生成、图像操作和个性化模型训练等功能。03,0750AI绘画# AI绘画# Flux# LiblibAI
星流星流 AI是由LiblibAI平台推出的一站式AI图像生成解决方案,它基于Star-3 Alpha模型,致力于为用户提供高精度、多样化的图像生成服务。该平台特别适合电商、广告、设计等多个领域的需求,支持写实、插画、动漫等多种风格。02,8640AI绘画# AI 图像生成# LiblibA# 星流
夸克·造点AI阿里旗下的夸克团队推出了全新AI产品“造点”,该平台具备AI生成图像和视频的功能,用户输入想法即可生成独特的画面和动态视频,同时还拥有创意特效玩法。02,3090AI绘画# Midjourney V7# 夸克# 通义万相2.2
RunningHubRunningHub 是一个云平台,让用户轻松开发和分享 AI 应用。它特别适合那些希望通过浏览器直接操作的创作者,无需复杂的本地设置。平台基于 ComfyUI 工作流,提供强大的 GPU 云计算支持,确保高效任务执行。02,0610AI绘画# ComfyUI# ComfyUI工作流# RunningHub
Reve ImageReve Image在人像和设计排版方面表现尤为出色,能够精准地根据用户输入的文本生成高质量的图像,同时也支持图生图功能,为创意工作者和普通用户提供了强大的工具。01,8640AI绘画# AI绘画# Reve AI# Reve Image
可灵 AI可灵 AI(Kling AI)是一款创新的 AI 工具,专注于帮助用户快速生成高质量的图片和视频。它由快手团队开发,基于自研的可灵大模型和可图大模型,提供多样化的创作功能,特别适合内容创作者和市场营销人员。01,2210AI视频# AI绘画# AI视频# 可灵 1.6
即梦AI即梦AI 通过强大的 AI 功能和灵活的会员服务体系,为创作者提供了一站式的创意解决方案。无论是图片生成、视频创作还是故事讲述,即梦AI 都能够帮助用户快速实现创意,提升创作效率。07980AI视频# AI绘画# AI视频# 即梦AI
海螺视频海螺视频凭借其强大的 AI 技术和创新功能,为创作者提供了一个简单、高效且充满想象力的创作平台。无论是文字描述还是图片输入,海螺视频都能将你的创意转化为令人惊叹的视觉作品。07460AI视频# AI视频# MiniMax# 主体参考
SoraOpenAI于2024年2月公开了其AI视频生成(文生视频)模型Sora,它可以创建长达 60 秒的视频,其中包含高度详细的场景、复杂的摄像机运动和具有生动情感的多个角色,但直到12月才正式上线。09940AI视频# OpenAI# Sora# 文生视频
Higgsfield AIHiggsfield AI平台支持文生图和图生视频,近期对图生视频功能进行了全面升级,专为追求高质量、风格化内容创作并渴望真正电影级操控的创意人士打造——无论是MV导演、商业片制作人、AI创作者,还是社交媒体叙事者。167,76510AI视频# Higgsfield AI# Higgsfield DoP I2V-01-preview# 图生视频
Fogsight (雾象)雾象是一款由大语言模型(LLM)驱动的动画引擎 agent 。用户输入抽象概念或词语,雾象会将其转化为高水平的生动动画。022,7301AI视频# Fogsight# 动画生成引擎# 大语言模型
DiffRhythm(谛韵)DiffRhythm(中文名“谛韵”)是由西北工业大学音频、语音与语言处理研究组(ASLP Lab)和香港中文大学(深圳)深圳大数据研究院联合开发的新型端到端全长度歌曲生成模型。基于潜扩散(Latent Diffusion)技术,DiffRhythm 能够快速生成包含人声和伴奏的完整歌曲,解决了现有音乐生成方法的诸多局限性。03,3980AI音乐# AI歌曲# AI音乐# DiffRhythm
MurekaMureka是昆仑万维的一款出海产品,这是一款AI歌曲生成器,让您可以轻松创建个性化的曲目,涵盖流行、电音、嘻哈、爵士等多种流派。它不仅支持多种音乐流派和语言,还提供了独特的定制功能,确保用户能够创作出符合自己独特品味的音乐。01,0160AI音乐# AI音乐# Mureka# Mureka O1
SongscriptionSongscription 是一个创新的 AI 平台,帮助用户将音频文件或 YouTube 视频快速转换为专业的乐谱和 MIDI 文件。它被称为“乐谱版 Shazam”,让音乐创作和学习更便捷,尤其适合那些没有官方乐谱的曲目。06610AI音乐# Songscription# 音乐转录
NaturalReaderNaturalReader 是一款功能强大、易于使用的文本转语音工具,适合各种场景下的阅读需求。无论您是希望节省时间的学生、需要无障碍支持的读者,还是寻求高质量语音内容的创作者,NaturalReader 都能为您提供卓越的体验。03,2090AI语音# NaturalReader# TTS# 文本转语音
AI SpeakerAI Speaker 是一款基于微软 TTS 服务的在线文字转语音(TTS)工具,能够将文字即时转换为自然流畅的 语音,支持100多种语言和600多种AI语音。01,5261AI语音# AI Speaker# TTS# 微软
ElevenLabsElevenLabs 成立于 2022 年,总部位于英国和波兰,致力于利用 AI 技术生成自然、富有表现力的语音。它的平台支持从文本到语音的转换、语音克隆和多语言配音,服务于各种需求。01,0710AI语音# AI语音# ElevenLabs# 语音克隆
Fish AudioFish Audio是一款生成式AI文本转语音和语音克隆平台,允许用户上传15秒语音片段进行克隆,支持多种场景如故事讲述、广告和有声书。它与AWS、Google Cloud和Nvidia合作,确保技术兼容性。01,0430AI语音# Fish Audio# OpenAudio S1# TTS
Fix JPEG artifacts compression lora Fix JPEG artifacts compression lora是一款基于图像编辑模型Flux Kontext开发的微调LoRA模型,此模型是用来修复JPEG压缩伪影。
Tattoo Kontext Dev LoRA Tattoo Kontext Dev LoRA 的核心优势在于其对人体结构与皮肤质感的深刻理解。它能将用户提供的纹身设计草图,精准地“贴合”到指定的身体部位,并自动处理细节。
Hyperdetailed Colored Pencil Hyperdetailed Colored Pencil 是一款专为追求高质量、细节丰富的艺术作品而设计的生成模型。无论是用于创作逼真的肖像画还是探索其他艺术形式,这款模型都能提供令人惊叹的效果。
InScene InScene 是一个为 Flux.1-Kontext.dev 设计的 LoRA,旨在生成与源图像保持场景一致性的图像。它基于 Flux.1-Kontext.dev 进行训练。主要用途是生成镜头变体,同时保持背景、整体环境、角色和风格不变。
朱雀大模型检测腾讯朱雀 AI 检测是于 2025 年 1 月 17 日推出的一款 AI 生成内容检测工具,主要用于帮助用户识别 AI 生成的文本和图像内容。每位用户每天最多可检测20次文本和20次图片。220,0703AI工具# AI生成图像检测# AI生成文本检测# 朱雀大模型检测
YouMindYouMind 是一款重新构想的 AI 写作工具,帮助每个人轻松开启创作之旅。捕捉灵感、收集素材、撰写草稿,并将其转化为精炼的文章、播客、视频等丰富内容。05,0550AI工具# AI写作# YouMind# 知识管理
NotebookLMNotebookLM是谷歌推出的一款个性化AI协作工具,旨在帮助用户更高效地进行信息整理和笔记记录。利用强大的语言模型帮助用户更快地从各种文本、图像以及网页中提取主要信息。01,7560AI工具# AI笔记# NotebookLM# 谷歌
WeKnoraWeKnora 不只是一个 RAG 框架,更是面向真实业务场景的文档智能中枢。它解决了传统检索无法理解语义、大模型容易“幻觉”的双重痛点,通过“精准召回 + 可控生成”的方式,让企业沉淀的知识真正“活起来”。01,3530AI工具# RAG# WeKnora# 维娜拉
DeepWiki Cognition Labs 推出了 DeepWiki,号称“涵盖所有 GitHub 代码库的免费百科全书”。只需将 GitHub 仓库 URL 中的 “github” 替换为 “deepwiki”,即可生成类似维基百科的详细文档页面,无需注册即可免费访问公共仓库的文档。01,3130AI工具# Cognition Labs# DeepWiki# Devin
MemUMemU 是一个开源的 AI 伴侣记忆框架,具有高准确性、快速检索和低成本的特点。它作为一个智能的“记忆文件夹”,能够适应不同的 AI 伴侣应用场景。通过 MemU,你可以构建真正记住你的 AI 伴侣。它们能够学习你的身份、关注点,并在每次互动中与你共同成长。01,0550AI工具# AI伴侣记忆框架# MemU
纳米AI搜索纳米AI搜索,简称纳米搜索,是360集团于2024年11月推出的基于大语言模型等多模态学习技术的搜索及内容创作工具,已发布Android、iOS和鸿蒙原生版本,并提供网页版、PC客户端。该产品支持文字、语音、拍照、视频等多种搜索方式。04,1620AI搜索# 360# 纳米AI搜索# 纳米搜索
WisPaperWisPaper 是由复旦大学团队自主研发的智能科研助手,专为学术研究人员打造,聚焦于搜文献➕读文献这一科研起点。平台集成了高质量 AI 学术搜索、智能文献翻译与总结功能,帮助用户精准获取、快速理解海量科研资料。02,1240AI搜索# WisPaper# 学术搜索引擎
MiroFishMiroFish 是一款基于多智能体技术的新一代 AI 预测引擎。通过提取现实世界的种子信息(如突发新闻、政策草案、金融信号),自动构建出高保真的平行数字世界。01,4371AI搜索# AI 预测引擎# MiroFish# 多智能体
WebsetsWebsets 是一款专为知识工作者设计的工具,能够帮助用户高效地查找符合特定标准的实体列表(如公司、人员、研究论文等)。根据基准测试,Websets 在复杂查询方面的表现远超谷歌,检索到的正确结果数量比谷歌多 20 倍以上。08560AI搜索# AI搜索# Exa# Websets
Perplexity AIPerplexity AI 是一个创新的AI搜索引擎,通过对话方式回答用户问题,提供总结性答案,并引用来源。它实时搜索互联网,确保信息最新,适合快速变化的主题,如新闻。07860AI搜索# AI搜索# Perplexity AI# 深度研究
Deep ResearchDeep Research 是一个功能全面、高效且注重隐私的研究工具,适用于各种场景下的快速深入研究。通过结合先进的 AI 模型、互联网搜索和本地知识库,它能够帮助用户在短时间内生成高质量的研究报告。07080AI搜索# AI搜索# Deep Research
Open Avatar ChatOpenAvatarChat 是一个功能强大且高度模块化的数字人系统,能够在单台 PC 上流畅运行,支持多模态交互。其开源特性为开发者提供了极大的自由度,可以根据具体需求进行定制和优化。01,1290AI数字人# Open Avatar Chat# 数字人# 阿里巴巴
星野APP星野APP是一款由MiniMax开发的AI伴侣应用,专为中国用户设计,旨在提供个性化的虚拟交互体验。用户可以通过星野APP创建自己的AI角色,定制其外貌、声音、性格和技能。01,0890AI数字人# AI伴侣# MiniMax# 星野APP
慧播星百度慧播星平台推出的 高说服力数码主播依托文心大模型的剧本生成与多模驱动能力,这一技术实现了数码主播在表情、语气、动作及情绪转换上的超拟真表现,甚至超越传统真人主播体验。06150AI数字人# 慧播星# 数字人# 电商
CaptionsCaptions利用先进的人工智能技术,让任何人都能通过几次简单的点击,使用手机制作出录音室品质的视频。无论是脚本编写、录制、编辑还是分享,Captions都能无缝支持您的每一个创作环节。05950AI数字人# AI视频# Captions# 数字人
WeCloneWeClone为我们提供了一个从聊天记录和声音创造数字分身的开源解决方案。它不仅能够模拟你的语言风格,还能复制你的声音,并将数字分身绑定到多个聊天平台上。05620AI数字人# WeClone# 微信# 数字分身
LemonSliceLemonSlice(前身为 Infinity AI)是一款视频生成平台,它允许用户仅需一张照片和一段脚本即可生成会说话的视频,适合营销专业人士、社交媒体内容创作者和 AI 电影制作者等。05020AI数字人# LemonSlice# 唇形同步# 对口型
TripoTripo AI 是一家领先的 AI 驱动 3D 建模解决方案提供商,允许用户使用文本、单张图像、多张图像、涂鸦或视频等输入,快速创建高质量的 3D 模型和环境。018,18313D# 3D 建模# 3D模型# Tripo
Hitem3D Hitem3D由Math Magic开发,是一款基于专有高分辨率AI模型Sparc3D的3D生成工具。只需上传一张参考图像,即可即时生成行业领先品质的工作室级3D资产,极大降低了3D创作的门槛。这一突破性解决方案赋能游戏开发者、设计师和3D艺术家高效释放创意,加速从概念到部署的创作流程。018,04303D# 3D 生成# Hitem3D# Sparc3D
MeshyMeshy 是一款非常适合初学者和专业用户的 3D 模型生成工具。无论是快速建模、3D 打印还是动画设计,它都能轻松应对。如果你对 3D 模型创建感兴趣,不妨试试 Meshy,让生成式 AI 为你的创意插上翅膀!05,24313D# 3D 模型# 3D生成# Meshy
Alpha3DAlpha3D 是一款尖端工具,旨在帮助用户轻松地将文本和 2D 图像转换为完全实现的 3D 模型。这款由生成式 AI 驱动的平台对于参与创建增强现实 (AR) 内容的人来说是天赐之物,因为它简化了传统上昂贵且复杂的 3D 模型创建过程。无需深入的 3D 建模专业知识或高级设计技能,Alpha3D 使数字资产的创建大众化,使其可供从专业人士到业余爱好者等广泛受众使用。01,04703D# 3D模型# 3D生成# Alpha3D
GenieGenie 是 Luma AI 推出的一款强大的文生 3D 模型工具,能够在极短时间内生成包含材质、四维网格重拓扑、可变多边形数量和所有标准格式的 3D 模型。它通过解析用户提供的文本描述,利用 AI 技术生成逼真的 3D 模型,并支持复杂的提示,用户可以指定颜色、材质和形状等属性。092003D# 3D模型# Genie# Luma AI
Google AI StudioGoogle AI Studio 是一个功能齐全的工具,特别适合希望快速构建和试验 AI 应用的开发者。其多模态支持、提示库和与 Gemini API 的无缝集成使其成为生成 AI 开发的有力平台。09,0870模型API# API# Gemini# Google AI Studio
ZenMuxZenMux 是全球首个企业级模型聚合平台,提供 AI 模型保险服务。我们不仅为开发者提供统一的 API 来访问全球领先的大型语言模型,还通过智能路由算法自动选择最佳模型,并提供保险支持的 AI 输出质量保障(即将推出),全面解决企业对 AI 幻觉和输出不稳定的担忧。通过 ZenMux,开发者可以通过单一接口调用来自 OpenAI、Anthropic、Google 和 DeepSeek 等提供商的模型,同时受益于智能路由、故障转移以及保险支持的质量保障服务。07320模型API# ZenMux# 大语言模型聚合平台
OpenRouterOpenRouter 通过统一的 API 接口和强大的优化功能,为开发者提供了一个高效、灵活且成本效益高的 AI 平台。它不仅简化了模型接入的复杂性,还通过标准化 API、真实洞察和统一计费,帮助开发者更好地管理和使用 AI 模型。03820模型API# API# API 接口# Cherry Studio
MiniMax开放平台MiniMax 是一个多模态 AI 技术的领导者,其强大的计算能力和丰富的功能使其成为企业和开发者的重要工具。无论是文本生成、语音合成还是视频制作,MiniMax 都能提供高质量的解决方案,助力用户实现技术创新和商业价值的最大化。01,0220模型API# MiniMax# 海螺 AI# 海螺视频
火山方舟大模型服务平台方舟是火山引擎推出的大模型服务平台,为您提供模型的训练、推理、评测、精调等全流程服务,帮助您快速应用的模型服务。09570模型API# API# 火山引擎# 火山方舟大模型服务平台
2233.ai2233.ai提供了一个便捷、安全且经济实惠的解决方案,让用户能够体验到原生的ChatGPT Plus和Claude Pro服务。同时,通过合理选择网络工具和使用API等方式,也可以在一定程度上改善使用体验,避免常见的网络和账号问题。09010模型API# 2233.ai# ChatGPT# Claude
中国科技云数据胶囊中国科学院旗下的 中国科技云数据胶囊(Data Capsule)提供 20GB 免费存储空间,支持 标准 S3 与 WebDAV 协议,无需手机号绑定,支持微信/QQ/GitHub 第三方登录,非常适合注重隐私、追求开源生态兼容性的科研用户或个人知识管理者。01,1170服务托管# 中国科技云数据胶囊
CivitAICivitAI是一个AI图像及视频模型托管平台,主要聚焦于 AI 生成的图像、视频和模型。它为用户提供了一个空间,可以上传、分享和发现由特定数据集训练的自定义 AI 模型,这些模型可用于生成独特的内容,如图像、视频。07220服务托管# CivitAI# CivitAIArchives# Diffusion Arc
EdgeOne PagesEdgeOne Pages 是基于 Tencent EdgeOne 基础设施打造的全栈开发部署平台,提供从前端页面到动态 API 的无服务器部署体验,适用于构建营销网站、AI 应用等现代 Web 项目。通过边缘网络全球加速,确保应用获得快速、稳定的访问体验。06040服务托管# EdgeOne Pages# 腾讯云
Arcenciel.ioArcenciel.io 是一个面向爱好者和发烧友的社区,提供数千个免费的高质量 Stable Diffusion 模型,其中大部分专注于动漫风格。03120服务托管# Arcenciel.io# Stable Diffusion# 动漫模型
ComfyDeployComfyDeploy 是团队使用 ComfyUI 和开发应用的最简单方式。我们通过让您的团队共享相同的自定义节点环境、模型和工作流程来实现这一点。02670服务托管# ComfyDeploy# ComfyUI
Open ASR 排行榜Open ASR 排行榜 对 Hugging Face Hub 上的语音识别模型进行排名和评估。我们报告平均 WER(字错误率)(⬇️ 越低越好)和 RTFx(实时因子)(⬆️ 越高越好),模型根据其平均 WER 从低到高进行排名。015,5120基准测试# Hugging Face# 语音识别
NOFXNOFX是一个基于 DeepSeek/Qwen AI 的加密货币期货自动交易系统,支持 Binance、Hyperliquid和Aster DEX交易所,多AI模型实盘竞赛,具备完整的市场分析、AI决策、自我学习机制和专业的Web监控界面。01,6940基准测试# NOFX# 加密货币
WebDev ArenaWebDev Arena 是一个实时的 AI编程竞赛平台,由 LMArena 开发,各种 AI代码模型在其中进行面对面的 Web 开发挑战。08910基准测试# AI编程# WebDev Arena# 网页开发
Artificial AnalysisArtificial Analysis 是一个专注于 AI 模型和提供商分析的网站,通过提供性能基准测试和区域性报告,帮助用户做出明智的选择。其内容覆盖广泛,包括语言模型、图像模型等,并特别关注全球AI趋势,如中国市场的动态。对于需要深入了解 AI 选项的用户,该网站是一个有用的工具,尤其是在性能比较和趋势分析方面。08010基准测试# AI模型# Artificial Analysis
MagicArenaMagicArena是字节跳动推出的一个采用Elo积分机制的视觉生成大模型公开对战平台。平台上有多个视觉生成大模型(文生图、文生视频、图生视频)随机两两对战,用户对生成的结果进行评价,累积定对战数据后可以查看自己的大模型排行榜。06970基准测试# Elo# MagicArena# 大模型
imgsysimgsys.org 是一个专注于开源文本引导图像生成模型的评估平台,通过用户偏好数据的收集和开源,推动图像生成领域的研究和开发。05640基准测试# Fal.ai# imgsys# 文生图模型
Kagi NewsKagi推出的AI新闻聚合站Kagi News,此站点基于一个简单原则:理解世界需要倾听世界的声音。每天,我们的系统阅读数千个社区精选的 RSS 源,这些源来自不同观点和视角的出版物。然后,我们使用 AI 将海量信息提炼成一份全面的每日简报,同时清楚地引用来源。01,9830爱学习# AI新闻# Kagi News
通往AGI之路《通往AGI之路》是一个由开发者、学者和有志之士共同参与的开源AI知识库与学习社区,旨在为人工智能(AI)的学习者、实践者和创新者提供全面的学习路径和资源支持。06910爱学习# AI知识库# WayToAGI# 通往AGI之路
OpenAI AcademyOpenAI Academy的上线,为全球AI教育注入了新的活力。通过提供免费、高质量的学习资源,OpenAI不仅让更多人有机会接触和学习AI,也为推动全球AI技术的发展和应用奠定了坚实的基础。05830爱学习# AI学习平台# ChatGPT# OpenAI
面向初学者的生成式 AI课程AI正在重塑各个行业,而生成式AI作为其最前沿的技术之一,正迅速成为开发者、创作者和企业关注的焦点。为了帮助更多人掌握这一技术,微软推出了全新的18集系列课程——“生成式AI入门”。04870爱学习# 微软# 生成式 AI
OpenClaw 101OpenClaw 101 是一个开源的 OpenClaw 资源聚合站,旨在帮助中文用户快速上手 OpenClaw —— 全球最热门的开源 AI 私人助理平台 (136k+ ⭐)。04820爱学习# OpenClaw# OpenClaw 101
Learn Your WayLearn Your Way 基于学习科学,并由 LearnLM 驱动,这是谷歌一流的注入教学法的模型家族,现在直接集成到 Gemini 2.5 Pro 中。它根据学习者选择的年级水平和个人兴趣调整内容,并基于源材料生成多种表示形式,从思维导图和音频课程到互动测验,这些功能支持实时反馈和进一步的内容个性化。它赋予学生对学习过程的自主权。04730爱学习# Learn Your Way# 教育# 谷歌
MinerUMinerU是一款功能强大、操作简单的文档解析工具。它不仅支持多种格式和导入方式,还能精准提取复杂元素,适用于多种场景。无论是学术研究、数据分析还是日常办公,MinerU都能为你带来流畅、准确的解析体验。在科研、学习和工作中,处理复杂文档格式一直是一个让人头疼的问题。无论是科技文献中的公式、表格,还是多语言扫描版PDF,传统工具往往难以满足高效、精准的解析需求。而今天要介绍的 MinerU,正是一款专为解决这些问题而生的免费文档解析神器。它不仅能精准提取复杂元素,还支持多种格式一键转换,适用于从机器学习到大模型语料生产的多种场景。 全格式兼容,轻松导入 MinerU 的一大亮点是其强大的格式兼容性。无论你的文档是 PDF、Word、PPT 还是图片,MinerU 都能轻松应对。通过简单的拖拽、截图或批量上传,你就可以快速将文件导入工具中,无需繁琐的操作。 支持格式:PDF、Word、PPT、图片等主流文档类型。 操作便捷:拖拽、截图、批量上传,一键完成导入。 智能识别:自动检测扫描版PDF和乱码PDF,并启用OCR功能,支持84种语言的检测与识别。 复杂元素精准提取 对于科技文献、学术论文等包含复杂排版的文档,MinerU 表现尤为出色。它能够精准定位并提取图表、公式等复杂元素,确保内容完整且语义连贯。 精准定位:自动识别文档中的图表、公式、表格等复杂元素,并进行精准提取。 结构保留:输出结果保留原文档的标题、段落、列表等结构,确保逻辑清晰。 多模态解析:支持图像描述、表格标题、脚注等内容的提取,适配多种使用场景。 多场景极速输出 MinerU 不仅擅长解析文档,还提供了丰富的输出格式选择,满足不同场景的需求。无论是用于机器学习训练、大模型语料生产,还是构建 RAG(检索增强生成)系统,MinerU 都能提供高效的解决方案。 多种输出格式: Markdown:适合多模态与NLP任务。 JSON:按阅读顺序排序,便于后续处理。 LaTeX:自动识别并转换公式,极大提升科研效率。 HTML:自动转换表格,方便网页展示。 可视化支持:提供 layout 可视化、span 可视化等功能,便于高效确认输出效果与质检。 技术亮点与性能优化 MinerU 在技术层面同样表现出色,兼顾了易用性与性能优化: 跨平台支持:兼容 Windows、Linux 和 Mac 平台,满足不同用户的设备需求。 硬件加速:支持纯 CPU 环境运行,同时可选 GPU(CUDA)、NPU(CANN)、MPS 加速,显著提升处理速度。 高精度 OCR:针对扫描版PDF和乱码文档,MinerU 内置高精度OCR功能,支持84种语言的检测与识别。 主要功能一览 MinerU 的核心功能覆盖了文档解析的方方面面,帮助用户高效完成复杂的文档处理任务: 删除冗余元素:自动移除页眉、页脚、脚注、页码等内容,确保输出文本语义连贯。 阅读顺序优化:输出符合人类阅读习惯的文本,无论是单栏、多栏还是复杂排版都能轻松应对。 公式与表格转换: 自动识别并转换公式为 LaTeX 格式。 自动识别并转换表格为 HTML 格式。 多语言支持:OCR 功能支持84种语言,满足国际化需求。 灵活输出:支持多种格式输出(Markdown、JSON、LaTeX、HTML 等),适配多种应用场景。 适用场景广泛 MinerU 的设计初衷是为了服务于科研和技术发展,但它的应用范围远不止于此。以下是一些典型的应用场景: 机器学习与大模型训练:将大量文档转化为高质量的训练数据,助力模型语料生产。 RAG 系统构建:为检索增强生成系统提供结构化数据支持。 学术研究:快速解析科技文献,提取关键信息,提升科研效率。 企业办公:批量处理合同、报告等文档,节省人工整理时间。 为什么选择 MinerU? 相比其他文档解析工具,MinerU 的优势在于其全面性和精准性。它不仅能够处理各种复杂文档,还能根据用户需求输出多样化的结果。更重要的是,MinerU 完全免费,且持续优化以解决科技文献中的符号转化问题,为大模型时代的技术进步贡献力量。05,8971实用工具# MinerU# PDF# 数据提取
人生 K 线人生 K 线(Life Destiny K-Line)是一个结合传统八字命理与现代大语言模型(LLM)的轻量级可视化工具。它将一个人从 1 岁到 100 岁的运势走势,以类似股票 K 线图的形式呈现,试图用数据可视化的方式“翻译”命理推演结果。04,0611AI小应用# AI算命# 人生 K 线
DrawAFish在 DrawAFish.com,每一次落笔都不只是涂鸦——它可能成为一条被AI识别、由算法验证、最终游进虚拟海洋的真实数字生命。这里没有复杂的操作门槛,只有一块画布、一个想法,和一群来自世界各地的创作者。01,7870AI小应用# AI画鱼# DrawAFish
FlyCut CaptionFlyCut Caption是一款智能、本地化的开源视频字幕裁剪工具,用智能字幕生成技术改变您的视频,自动生成准确字幕,精确编辑,支持多种格式导出。为内容创作者、教育工作者和企业提供完美解决方案。01,7440AI小应用# FlyCut Caption# 智能视频字幕裁剪工具
OpenClaw 一键部署工具OpenClaw 一键部署工具是一款专为 AI 爱好者和开发者打造的私人 AI 助手一键部署工具,支持多模型、多消息渠道接入,提供图形界面与命令行两种部署方式,无需复杂的手动配置,就能快速搭建属于自己的跨平台 AI 助手,兼具灵活性与实用性。01,6740AI小应用OpenClaw相关# OpenClaw 一键部署工具
BabelDOCBabelDOC 是新一代智能 PDF 翻译工具,采用先进的排版保持技术,为您提供专业级的双语对照翻译体验。无论是前沿学术论文,还是商业分析报告,BabelDOC 都能帮您轻松跨越语言藩篱,同时完美呈现原文档的精致排版。01,6080实用工具# BabelDOC# PDF 翻译工具# 沉浸式翻译
winapp - 最新版微软发布 Windows 应用开发 CLI(或称 winapp)的预览版。这是一个开源命令行界面,旨在简化 Windows 应用程序的开发流程。这款新工具旨在帮助使用跨平台框架或在 Visual Studio 或 MSBuild 之外的构建工具链的开发者,减少重复的设置和打包任务。
STABLE PROJECTORZ - 最新版STABLE PROJECTORZ是一款免费工具,用于通过StableDiffusion制作纹理和3D内容。它提供了丰富的功能,包括保留UV、通过笔刷混合图层、通过文本或图像生成提示,以及3D修复。
NexFace - 最新版NexFace是一款功能强大、本地运行、用户友好的桌面应用程序,用于高质量批量人脸替换。基于 Python 和 Gradio 构建,该工具为 Face2Face 库提供了便捷的界面,只需几次点击即可将单一源人脸替换到数百张目标图像或视频上。
Genspark AI 浏览器 - 最新版Genspark AI浏览器现已登陆Windows和Mac,带来全球首创的AI功能,将彻底改变您的在线工作方式。从设备端AI模型到自主网络导航——您的浏览器现在为您服务。
K3U Installer - 最新版K3U Installer v2 Beta是一款功能强大、灵活且可视化的ComfyUI安装工具。它不仅简化了安装流程,还提供了丰富的配置选项和自动化支持,非常适合初次使用者和需要版本控制与自动化的高级开发者。
LoRA Training for Qwen-Image - 最新版FlyMy.AI 开源了针对 Qwen-Image LoRA训练工具,为开发者提供一个轻量、高效、可扩展的多模态模型微调工具。该项目旨在降低图像生成模型定制化的门槛,支持用户基于自有数据集快速训练个性化 LoRA 模型,适用于图像风格迁移、特定对象生成等场景。
肉包(Roubao) - 最新版肉包(Roubao) 是一个完全开源、免费、原生运行于 Android 的 AI 手机自动化助手。它基于视觉语言模型(VLM)+ 多 Agent 架构,让你用自然语言指挥手机完成复杂操作。
AI Playground - 最新版英特尔于2024年7月23日正式推出AI工具AI Playground的Beta 测试版,这是一款让生成式 AI 新手快速实现入门的开源软件,AI Playground 目前支持在配备 8GB 或更多显存的锐炫 Arc 显卡的 Windows 电脑上运行。