OpenAI在公开Sora后,引得网友们一片欢呼,但却迟迟不肯释出Sora让大家体验。但却有其他厂商抢先推出同样是基于DiT架构的视频生成模型,比如快手的可灵大模型、Luma AI 的Dream Machine等,智谱 AI也在昨天宣布正式对旗下视频生成模型CogVideoX进行全新升级,并推出面向C 端用户的产品“清影“,目前免费对用户开放,登录官网后点击申请很快就能收到内测邀请,“清影”支持时长6s的文生视频/图生视频,清晰度为1440x960。跟其他家不同,智谱AI这次直接推出付费版本——付费5元,解锁一天24小时的高速权益,付费199元,解锁一年的付费高速权益。此外,智谱大模型开放平台 bigmodel.cn 也部署了「清影」。企业和开发者可通过 API 调用式,体验并使用「清影」的文本生成视频和图像生成视频功能。

清影的核心技术特点如下:
针对内容连贯性问题,智谱 AI 自主研发了一套高效的三维变分自编码器结构(3D VAE)。该结构能够将原始视频数据压缩至原始大小的 2%,降低了视频扩散生成模型的训练成本和难度。结合 3D RoPE 位置编码模块,该技术提升了在时间维度上对帧间关系的捕捉能力,从而建立了视频中的长期依赖关系。
在可控性方面,智谱 AI 打造了一款端到端的视频理解模型,该模型能够为大量视频数据生成描述。这一创新增强了模型对文本的理解和对指令的遵循能力,确保生成的视频更加符合用户的输入需求,并能够处理超长且复杂的 prompt 指令。
模型采纳了一种将文本、时间、空间三维一体融合的 transformer 架构。该架构摒弃了传统的 cross attention 模块,设计了 Expert Block 以实现文本与视频两种不同模态空间的对齐,并通过 Full Attention 机制优化模态间的交互效果。
「清影」的主要特点如下:
快速生成:仅需 30 秒即可完成 6 秒视频的生成。
高效的指令遵循能力:即使是复杂的 prompt,清影也能准确理解并执行。
内容连贯性:生成的视频能够较好地还原物理世界中的运动过程。
画面调度灵活性:例如,镜头能够流畅地跟随画面中的三只狗狗移动。
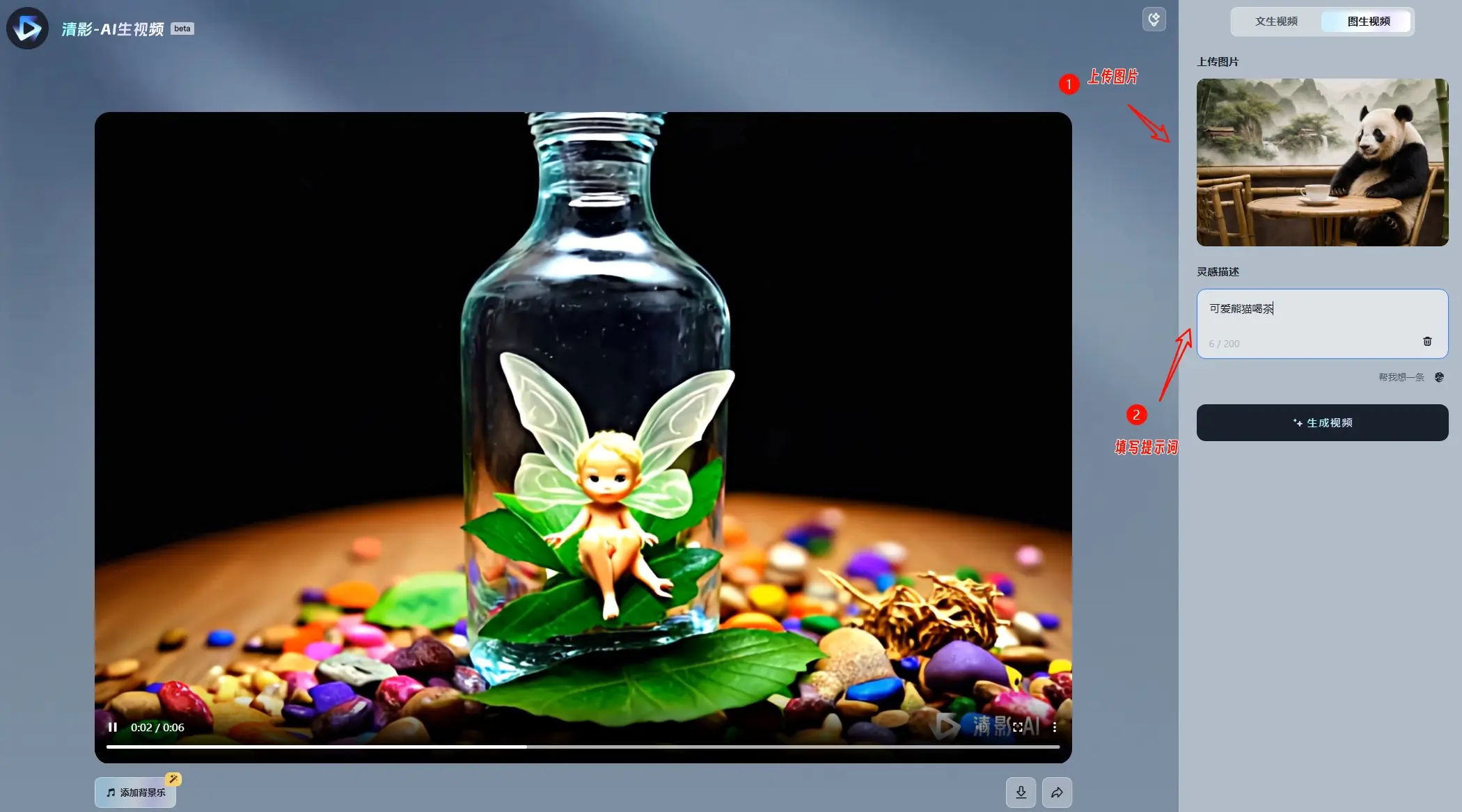
如果想要输出的视频更符合心中所想,还可以按照结构性原则来写prompt(提示词),清影使用手册里给出了两款公式结构:
- 简单公式:[摄像机移动]+[建立场景]+[更多细节]
- 复杂公式:[镜头语言] + [光影] + [主体 (主体描述)] + [主体运动] +[场景 (场景描述)] +[情绪/氛围/风格]
- 清影提示词(文生视频专用):https://chatglm.cn/main/gdetail/669911fe0bef38883947d3c6
- 清影提示词(图生视频专用):https://chatglm.cn/main/gdetail/669fb16ffdf0683c86f7d903

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...