阿里发布文生图模型Qwen-Image-2512:人像、纹理、文字渲染显著提升2025 年 12 月 31 日,阿里 Qwen 项目组发布了 Qwen-Image-2512 —— Qwen-Image 文生图基础模型的最新版本。这是继今年 8 月首次开源 Qwen-Image ...图像模型# Qwen-Image-2512# 文生图模型3个月前0430
阿里开源Ovis-Image:7B 参数实现高质量文本渲染的文生图模型,海报 / UI 设计秒生成Ovis-Image 是由阿里巴巴国际数字商务团队开发的 70亿参数 文本到图像(Text-to-Image)生成模型,专注于解决文生图系统中长期存在的文本模糊、拼写错误、排版失真等痛点。该模型在保持...图像模型# Ovis-Image# 文生图模型4个月前02690
BRIA 发布 FIBO:用 JSON 精确控制光线、构图与相机参数的文生图模型BRIA 开源发布了其首个文本到图像模型 FIBO —— 一个专为专业图像生成工作流设计的 JSON 原生、结构化提示驱动 的开源模型。与主流强调“想象力”的生成模型不同,FIBO 的核心目标是 可控...图像模型# BRIA# FIBO# 文生图模型5个月前01170
英伟达提出 DC-Gen:用于加速扩散模型的后训练框架,生成速度快 53 倍在文生图领域,高分辨率输出(如 4K)正成为标配。然而,随之而来的计算成本和推理延迟问题日益凸显——以当前领先的 FLUX.1-Krea-12B 模型为例,在英伟达H100 GPU 上生成一张 4K ...图像模型# DC-Gen# 文生图模型# 英伟达6个月前03600
腾讯混元开源 HunyuanImage 2.1:支持 2K 分辨率的高效文生图模型腾讯混元项目组正式开源HunyuanImage 2.1,一款支持 2048×2048 超高分辨率(2K)生成的文生图模型。该模型在语义对齐、细节控制与推理效率方面实现显著提升,具备电影级构图能力,并原...图像模型# HunyuanImage 2.1# 文生图模型7个月前04610
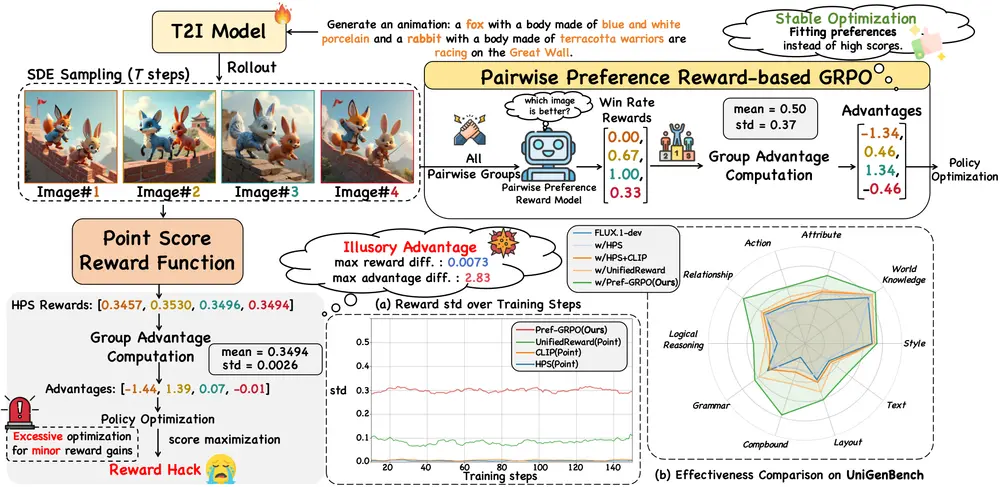
复旦等团队联合突破文生图模型生成瓶颈:Pref-GRPO解决奖励操控,UniGenBench补上评估短板文本到图像(T2I)生成技术的进步,离不开强化学习方法的优化与基准测试的支撑。但当前领域存在两大核心问题:一是传统强化学习依赖“点式奖励模型”打分,易出现“分数涨而质量降”的奖励操控现象;二是现有基准...图像模型# Pref-GRPO# 文生图模型7个月前03370
Flex.2-preview:基于 Flux.1 Schnell 微调而成的开源 80 亿参数文生图模型Flex.2-preview 是一款开源的文本到图像扩散模型,具有 80 亿参数,支持通用控制和图像修复功能。它基于 Flux.1 Schnell 微调而成,旨在为用户提供更灵活、更强大的图像生成能力...图像模型# Flex.2-preview# FLUX.1 [schnell]# 文生图模型11个月前07550
苹果提出了新的文生图模型架构DiT-Air和DiT-Air-Lite:提高模型的参数效率和生成性能苹果提出了新的文生图模型架构DiT-Air和DiT-Air-Lite,旨在提高模型的参数效率和生成性能。其论文主要研究了扩散模型(Diffusion Models)在文本到图像生成任务中的架构设计、文...新技术# DiT-Air# DiT-Air-Lite# 文生图模型1年前07090
如何在保持计算效率的同时,将原始文生图模型的多样性和控制能力转移到高效的蒸馏模型中美国东北大学的研究人员发布论文《Distilling Diversity and Control in Diffusion Models》,探讨了如何在保持计算效率的同时,将原始扩散模型的多样性和控制...新技术# 文生图模型# 蒸馏模型1年前04480
韩国科学技术研究院推出专门针对文生图模型的新型数据投毒攻击方法Silent Branding Attack韩国科学技术研究院和DeepAuto.ai的研究人员推出一种新型数据投毒攻击方法Silent Branding Attack ,专门针对文生图模型。该方法能够在文生图模型中隐秘地嵌入特定品牌标志或符号...新技术# Silent Branding Attack# 文生图模型# 韩国科学技术研究院1年前04790
SANA模型的升级版SANA 1.5:实现高质量的图像生成,同时显著降低了训练和推理成本英伟达、麻省理工学院、清华大学、Playground和北京大学的研究团队推出了SANA模型的升级版SANA 1.5,这是一款高效的DiT架构模型,通过创新的训练和推理策略,实现文本到图像生成任务中的高...图像模型# DiT架构模型# SANA 1.5# 文生图模型1年前03430
智谱开源首个支持汉字生成的开源文生图模型 CogView4作为中国AI厂商中的开源先锋,智谱AI一直致力于推动技术开放与共享。这家清华系初创企业近年来通过与清华大学合作,开源了多个备受关注的AI模型系列,包括大语言模型GLM系列、文生图模型CogView系列...图像模型# CogView4# 文生图模型# 智谱1年前03600