
在文生图领域,高分辨率输出(如 4K)正成为标配。然而,随之而来的计算成本和推理延迟问题日益凸显——以当前领先的 FLUX.1-Krea-12B 模型为例,在英伟达H100 GPU 上生成一张 4K 图像需耗时超过 3 分钟,严重限制了其在实时创作等场景的应用。
为解决这一瓶颈,英伟达研究团队提出 DC-Gen(Deeply Compressed Generative model),一种全新的扩散模型加速框架。它通过引入深度压缩的潜在空间,在不重新训练整个模型的前提下,实现高达 53 倍的推理速度提升,同时几乎完全保留原始模型的生成质量。

更重要的是,DC-Gen 不依赖特定架构,可广泛适配各类预训练扩散模型,为大模型高效部署提供了一条通用路径。
核心挑战:高分辨率 = 高延迟?
现有扩散模型通常在“潜变量空间”(latent space)中进行去噪生成,再通过自编码器(VAE)解码为像素图像。这个过程的效率高度依赖于潜空间的压缩比:
- 常规 VAE 多采用 8× 或 16× 压缩(如 Stable Diffusion);
- 要生成 4K(≈ 3072×3072)图像,仍会产生数万个视觉 token,导致注意力计算量激增。
例如:
| 模型 | 分辨率 | Token 数量 | 推理时间(H100) |
|---|---|---|---|
| FLUX.1-Krea | 4K | ~36,864 tokens | >180 秒 |
这使得原生支持 4K 生成极为困难。传统方案要么降低质量,要么从头训练更高效的自编码器——但后者成本极高,动辄数百 GPU 天。

DC-Gen 的目标是打破这一困局。
DC-Gen 是什么?三大关键技术
DC-Gen 并非一个新模型,而是一套面向已有扩散模型的轻量级后训练加速方法。其核心思想是:将原模型迁移到一个更深压缩的潜在空间中运行,从而大幅减少 token 数量和计算负载。
整个流程分为三步:
1. 替换自编码器:进入深度压缩空间
使用新型自编码器(如 DC-AE-f64c128),实现 64× 甚至更高压缩比。这意味着:
- 输入图像从 3072×3072 → 映射为仅 48×48 = 2,304 个 latent token
- 相比原空间减少约 94% 的 token 数量
这种级别的压缩在过去难以应用,因为会破坏语义一致性。DC-Gen 通过后续两步解决了这个问题。
2. 嵌入对齐(Embedding Alignment):知识无损迁移
直接更换自编码器会导致潜在空间分布偏移,模型无法正确理解新空间中的表示。
为此,DC-Gen 引入轻量级嵌入对齐训练阶段:
- 固定扩散模型权重;
- 在新旧两个自编码器之间建立映射关系;
- 训练一个小规模投影模块,使基础模型能“读懂”新空间的语义。
该阶段仅需少量数据和计算资源(<5 H100 GPU天),即可完成知识迁移。

3. LoRA 微调:恢复生成能力
在对齐后的空间中,使用 LoRA(Low-Rank Adaptation) 对扩散模型进行微调,进一步适应新的 latent 表示。
- 仅更新极小部分参数;
- 训练成本低(总后训练约 40 H100 GPU天);
- 可快速恢复甚至超越原始模型的生成质量。
✅ 整个过程无需从头训练扩散模型,显著降低部署门槛。
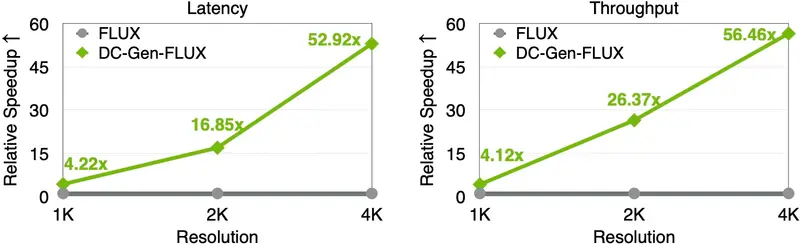
性能表现:快 53 倍,延迟降百倍
以 FLUX.1-Krea-12B 为基础模型,构建出 DC-Gen-FLUX,实测结果如下:
| 指标 | 原始 FLUX.1-Krea | DC-Gen-FLUX | 提升幅度 |
|---|---|---|---|
| 推理时间(4K, H100) | 180+ 秒 | 4.04 秒 | ↓ 53× |
| 吞吐量(images/sec) | 0.005 | 0.247 | ↑ 56× |
| CLIP Score(1K) | 27.93 | 27.94 | ≈ 持平 |
| 训练成本 | N/A | 40 H100 GPU天 | 远低于从头训练 |
更进一步,当结合 英伟达 NVFP4 精度 和 20 步采样 时,DC-Gen-FLUX 在单张 RTX 5090 级 GPU 上生成 4K 图像仅需 3.5 秒,端到端延迟相较原模型降低 138 倍。
这意味着:曾经需要几分钟等待的高质量图像生成,现在已接近“即时响应”。
为何重要?不只是“更快”
DC-Gen 的意义不仅在于速度突破,更在于它提供了一种模型-基础设施协同演进的新范式:
✅ 支持原生高分辨率生成
首次让 FLUX 类模型具备实用化的 4K 生成能力,无需降分辨率或分块拼接。
✅ 实现自编码器灵活替换
过去更换 VAE 必须重训整个扩散模型;DC-Gen 通过嵌入对齐机制,实现了“即插即用”的组件化升级。
✅ 推动边缘与实时场景落地
3.5 秒生成 4K 图像,使得以下应用成为可能:
- 实时 AI 绘画工具(用户拖拽即见效果)
- 游戏资产快速生成
- 影视预可视化与动态构图
- VR/AR 内容按需渲染
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











