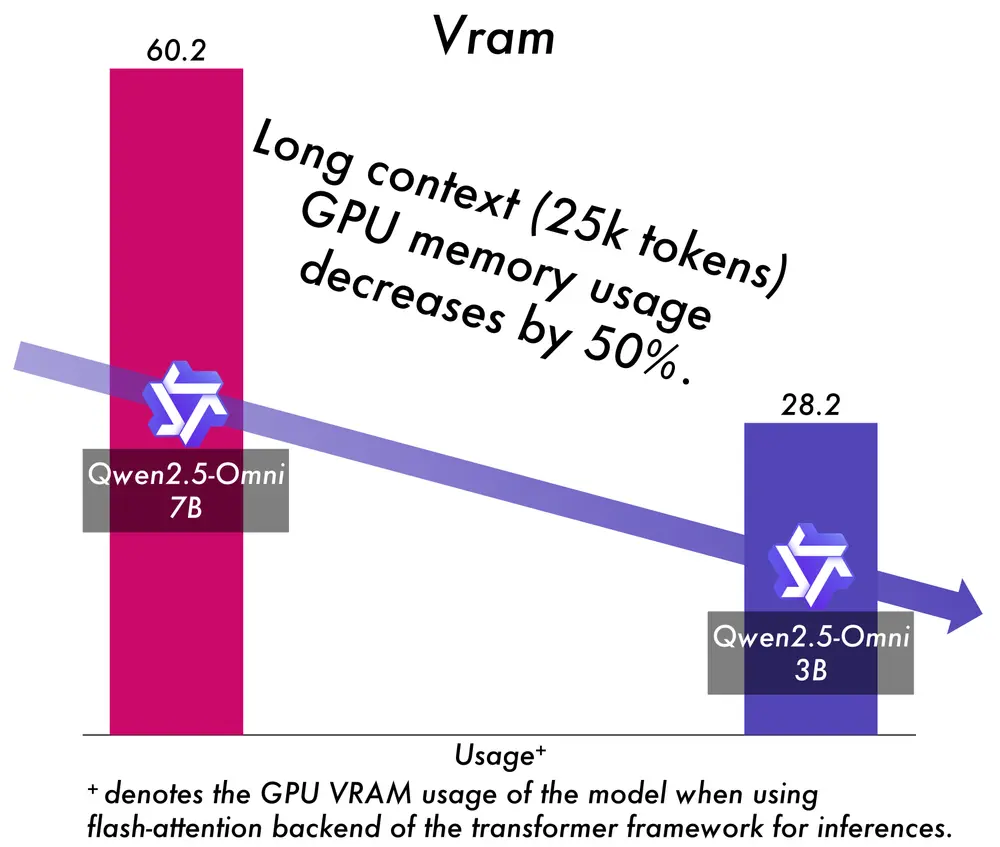
Jina AI正式发布 jina-embeddings-v4 —— 一款全新的38亿参数通用嵌入模型,支持文本与图像输入,适用于多种检索任务。该模型在多个基准测试中表现优异,特别是在处理表格、图表等视觉丰富内容方面展现出强大能力。

模型亮点
- 多模态支持:支持文本与图像联合嵌入
- 多语言能力:覆盖29种以上语言
- 双输出模式:单向量 + 多向量嵌入
- 任务适配器:非对称检索、语义匹配、代码搜索
- 长文档处理:最大支持32768个token输入
- 高分辨率图像支持:高达2000万像素
性能优势
在多个关键任务中,jina-embeddings-v4 表现出优于主流闭源模型的性能:
| 任务 | v4得分 | 对比模型 | 提升幅度 |
|---|---|---|---|
| 多语言检索(MTEB) | 66.49 | text-embedding-3-large | +12% |
| 长文档检索(LongEmbed) | 67.11 | voyage-3 | +28% |
| 代码检索(CoIR) | 71.59 | voyage-3 | +15% |
| 视觉文档检索(Jina-VDR) | 84.11 nDCG@5 | - | 首次支持 |
| 跨模态对齐 | 0.71 | CLIP | +显著提升 |
这些结果表明,v4 不仅在传统文本任务上具备竞争力,在多模态、视觉文档等新兴场景中也具有领先优势。
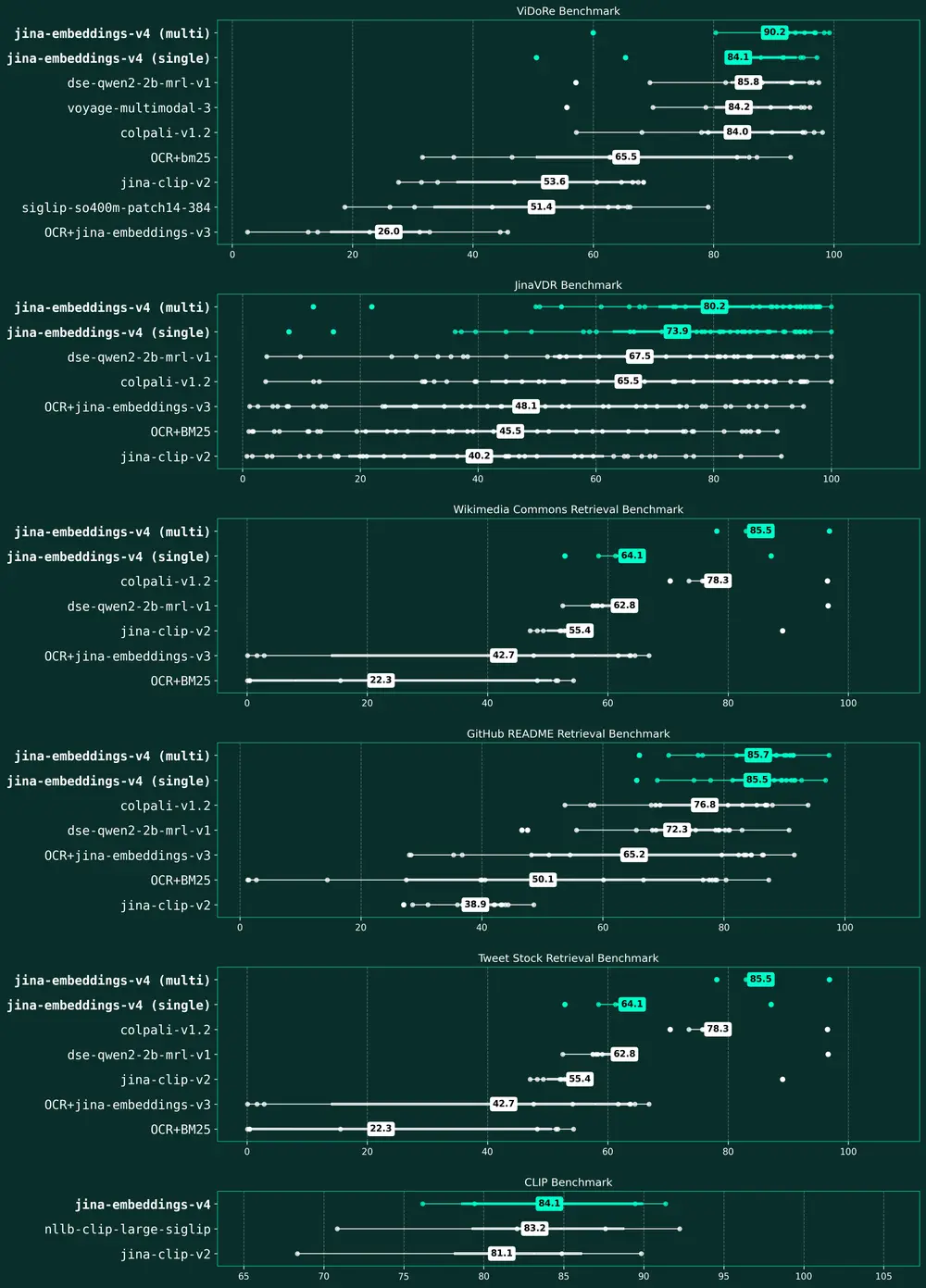
架构升级概览
从 v3 到 v4 的升级不仅是参数规模的扩展,更是架构和能力上的跃迁。以下是主要变化对比:
| 维度 | jina-embeddings-v3 | jina-embeddings-v4 |
|---|---|---|
| 参数量 | 5.72亿 | 38亿 |
| 支持模态 | 仅文本 | 文本 + 图像 |
| 输入长度 | 8192 tokens | 32768 tokens |
| 图像支持 | 不支持 | 高达2000万像素 |
| 向量类型 | 单向量 | 单向量 + 多向量 |
| LoRA适配器数量 | 5种 | 3种 |
| 骨干模型 | XLM-RoBERTa | Qwen2.5-VL-3B-Instruct |
| 训练阶段 | 三阶段 | 两阶段 |
| 位置编码 | RoPE | M-RoPE(多模态) |
核心架构改进
1. 骨干模型更换
v4 将骨干模型从 XLM-RoBERTa 更换为 Qwen2.5-VL-3B-Instruct,这是实现多模态统一表示的关键一步。新模型能够将图像转换为标记序列,并与文本一同处理,从而消除传统双编码器架构中的模态差距。
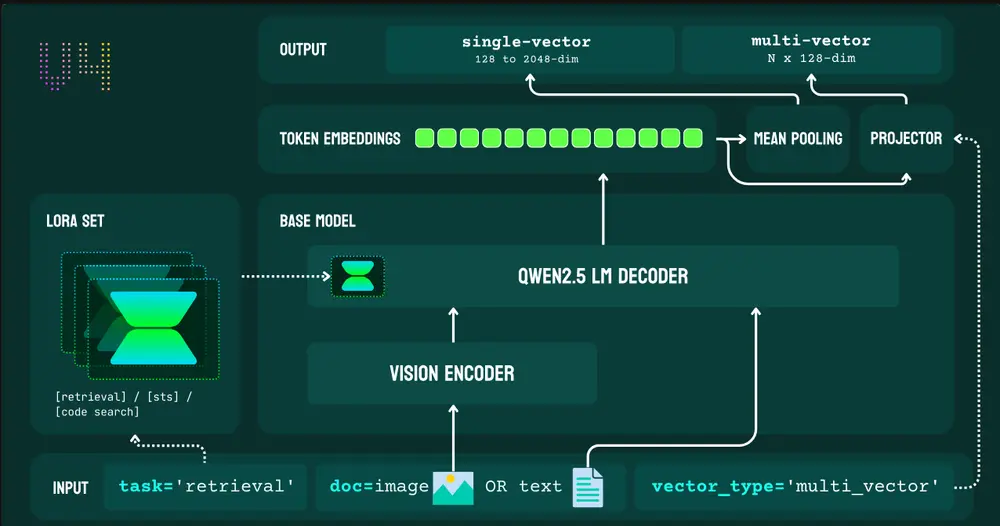
此外,Qwen2.5-VL 在文档理解任务上表现出色,使得 v4 在处理表格、图表、截图等复杂内容时更具优势。
2. LoRA 适配器优化
v4 精简了任务适配器的数量,聚焦于最具实用价值的三个方向:
- 非对称检索:适用于查询-文档检索场景
- 语义相似性:用于句子间相似度计算(STS)
- 代码检索:支持代码片段的高效查找
这一调整去除了 v3 中较少使用的分类和分离适配器,提升了整体使用效率。
3. 嵌入输出机制升级
v4 引入双输出机制,满足不同检索需求:
- 单向量模式:2048维向量,适用于快速相似性搜索
- 多向量模式:每个 token 输出128维向量,适用于后期交互式检索
实验证明,在视觉文档检索任务中,多向量模式比单向量模式性能高出7-10%,有效提升复杂内容的语义匹配精度。
4. 训练策略优化
v4 的训练流程简化为两个阶段:
- 联合对训练(Joint Pair Training)
- 任务特定适配器微调
这种策略不仅提升了训练效率,还增强了模型的泛化能力。损失函数采用 InfoNCE + KL 散度组合,确保单/多向量输出的一致性。
参数规模与性能关系
虽然 v4 参数是 v3 的6.7倍,但性能提升主要体现在多模态能力上:
| 基准测试 | v4得分 | v3得分 | 提升幅度 |
|---|---|---|---|
| MMTEB(多语言) | 66.49 | 58.58 | +14% |
| MTEB-EN(英文) | 55.97 | 54.33 | +3% |
| CoIR(代码检索) | 71.59 | 55.07 | +30% |
| LongEmbed(长文档) | 67.11 | 55.66 | +21% |
这说明,新增参数主要用于支持图像处理和跨模态对齐,而非单纯增强文本能力。统一架构的设计也减少了维护多个模型的成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











