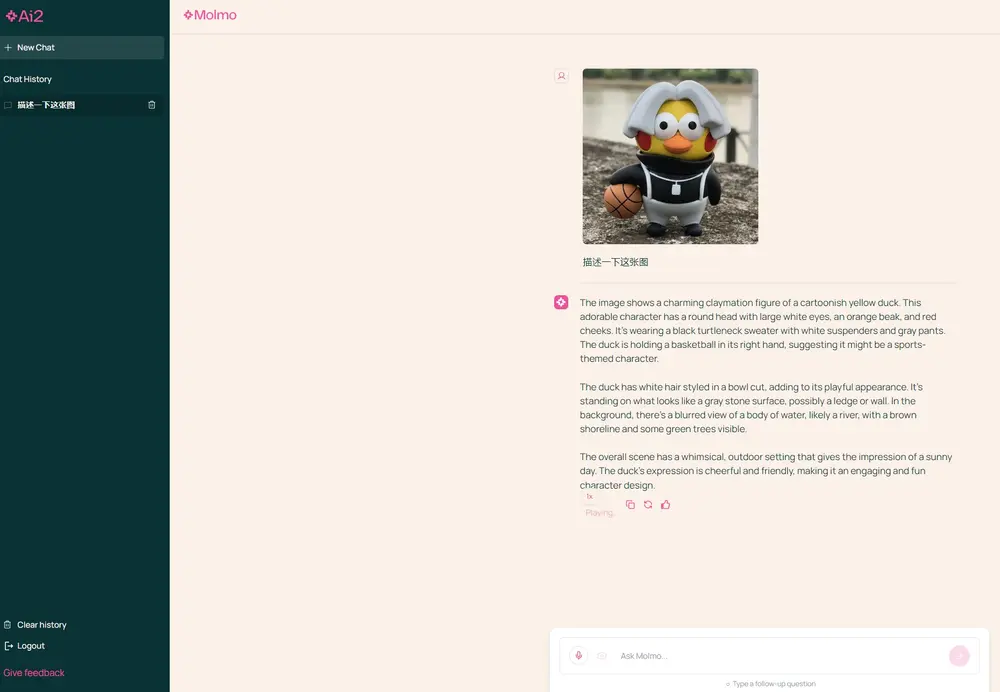
在视觉语言模型(VLM)竞相追逐千亿参数、万亿训练词元的今天,微软反其道而行之,发布了 Phi-4-reasoning-vision-15B。
- 官方介绍:https://www.microsoft.com/en-us/research/blog/phi-4-reasoning-vision-and-the-lessons-of-training-a-multimodal-reasoning-model
- GitHub:https://github.com/microsoft/Phi-4-vision
- 模型:https://huggingface.co/microsoft/Phi-4-reasoning-vision-15B
这是一个 150 亿参数、开放权重 的多模态推理模型。它不追求规模的极致膨胀,而是专注于在科学数学推理、细粒度文档分析以及图形用户界面(GUI)理解这三个关键领域,实现质量、效率与成本的最佳平衡。
架构解密:务实的“中期融合”
Phi-4-reasoning-vision-15B 并非从零开始,而是站在巨人的肩膀上进行的精准整合:
- 语言主干:基于强大的 Phi-4-Reasoning 模型,具备深厚的逻辑推理底蕴。
- 视觉编码器:集成先进的 SigLIP-2,负责将图像转化为高精度的视觉词元。
- 融合策略:采用 中期融合(Mid-fusion)架构。视觉编码器先将图像转换为词元,投影到语言模型的嵌入空间,再由语言模型统一处理。
为何选择中期融合?
这是一种务实的权衡。相比早期融合,它在保持强大跨模态推理能力的同时,显著降低了训练和推理的计算成本,使得 15B 的体量也能爆发惊人的能量。
逆向而行:小数据,大智慧
当 Qwen、Kimi、Gemma 等竞品纷纷使用 超过 1 万亿 多模态词元进行训练时,Phi-4-reasoning-vision-15B 的训练数据量显得尤为“克制”:
- 基础底座:Phi-4(4000 亿独特词元)
- 推理增强:Phi-4-Reasoning(160 亿词元)
- 多模态对齐:仅用了 2000 亿 多模态词元
微软证明了一个重要观点:模型的能力不仅仅取决于数据量的堆砌,更在于数据的质量、架构的设计以及训练策略的精准度。 这种“小而美”的路线,极大地降低了部署门槛,让高性能多模态模型能在更多边缘设备和私有云环境中运行。
核心突破一:高分辨率动态感知
“多模态推理的失败,往往始于感知的失败。”
这是微软团队从实践中得出的深刻洞察。如果模型看不清屏幕上的微小按钮、文档中的细微公式或图表中的关键数据点,再强的推理能力也是无米之炊。
为此,Phi-4-reasoning-vision-15B 引入了 动态分辨率视觉编码器:
- 超高密度:最多可处理 3,600 个视觉词元。
- 动态适配:根据图像内容的复杂程度自动调整分辨率。
- 应用场景:完美胜任 GUI 元素定位(如点击某个特定图标)、密集文档分析(如表格、手写公式)以及 科学图表解读。
准确的感知,成为了高质量推理的坚实先决条件。
核心突破二:混合推理模式(Hybrid Reasoning)
并不是所有任务都需要“深思熟虑”。描述一张图片不需要思维链,但解一道微积分题必须步步为营。
Phi-4-reasoning-vision-15B 创新性地采用了 混合推理训练策略:
- 推理模式 (
<think>...</think>):针对数学、科学、逻辑推导等复杂任务,模型会生成显式的思维链,逐步拆解问题。这类数据约占训练集的 20%。 - 非推理模式 (
<nothink>):针对图像描述、OCR 识别、简单问答等感知型任务,模型直接输出结果,避免不必要的延迟。
灵活控制:
虽然模型能隐式学习切换模式,但微软也赋予了用户完全的控制权。用户可以通过 Prompt 显式指定 <think> 或 <nothink> 标签,强制模型进入相应的状态,以适应不同的延迟和精度需求。
核心应用场景
凭借上述特性,该模型在以下两个领域表现尤为突出:
1. 科学与数学推理
- 手写公式识别与求解:轻松应对潦草的数学笔记。
- 图表数据分析:从复杂的曲线图、柱状图中提取定量信息并进行推理。
- 多学科文档理解:处理包含物理、化学、生物符号的专业文献。
2. 计算机使用智能体 (Computer Use Agents)
- GUI 元素定位:精准识别屏幕截图中的按钮、输入框、菜单项(ScreenSpotv2 得分高达 88.2)。
- 交互指令生成:理解桌面、Web 或移动界面的当前状态,并生成正确的操作指令(点击、输入、滚动)。
- 自动化工作流:作为 AI Agent 的“眼睛”和“大脑”,自主完成软件操作流程。
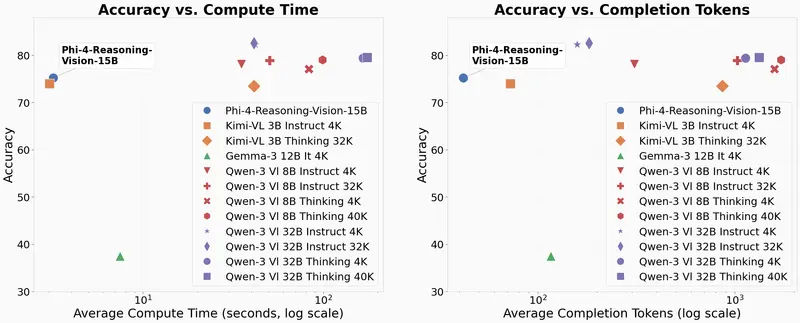
基准测试表现
在固定的评估设置下(使用 Eureka ML Insights 和 VLMEvalKit),Phi-4-reasoning-vision-15B 展现了与其体量不符的强劲实力:
| 基准测试 | 领域 | 得分 | 评价 |
|---|---|---|---|
| ScreenSpotv2 | GUI 定位 | 88.2 | 业界领先,展现极强的界面理解力 |
| AI2DTEST | 科学图表 | 84.8 | 科学推理能力卓越 |
| ChartQATEST | 图表问答 | 83.3 | 数据提取与分析准确 |
| MathVistaMINI | 综合数学 | 75.2 | 复杂数学问题解决能力强 |
| OCRBench | 文字识别 | 76.0 | 细粒度文本感知优秀 |
| MMStar | 综合多模态 | 64.5 | 均衡的综合能力 |
| MathVerseMINI | 深度数学 | 44.9 | 极具挑战性的数学推理仍有提升空间 |
注:微软强调这些数据旨在展示模型在紧凑规模下的竞争力,而非单纯的排行榜刷分。
启示
Phi-4-reasoning-vision-15B 的发布传递了几个重要信号:
- 参数不是唯一真理:15B 的模型通过精心设计的架构和数据策略,完全可以胜任专业的多模态推理任务。
- 感知即推理的基础:高分辨率、动态的视觉编码是解决复杂视觉任务的关键瓶颈。
- 效率与智能并存:混合推理模式让模型既能在需要时“慢思考”,也能在简单任务上“快反应”,实现了用户体验的最优化。
对于开发者而言,这意味着一个开源、轻量、可私有化部署的强大多模态引擎已经就绪。无论是构建教育辅导应用、自动化办公助手,还是科研数据分析工具,Phi-4-reasoning-vision-15B 都是一个值得关注的最佳选择。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











