华盛顿大学和艾伦人工智能研究所的研究人员推出新型多模态模型家族Molmo,这些模型专门设计用于理解和处理图像和文本数据。Molmo的目标是提供一个最先进的、开放的多模态模型,Molmo的关键创新是一个新颖的、高度详细的图像标题数据集,完全由人类注释者使用基于语音的描述收集。为了支持广泛的用户交互,研究团队还引入了一个多样化的数据混合集用于微调,包括野外Q&A和创新性的2D指向数据。此方法的成功依赖于对模型架构细节的精心选择、良好调整的训练流程,以及最关键的是研究团队新收集的数据集的质量,所有这些都将被发布。
- 官方Demo:https://molmo.allenai.org
- 模型:https://huggingface.co/collections/allenai/molmo-66f379e6fe3b8ef090a8ca19
- 官方介绍:https://molmo.allenai.org/blog
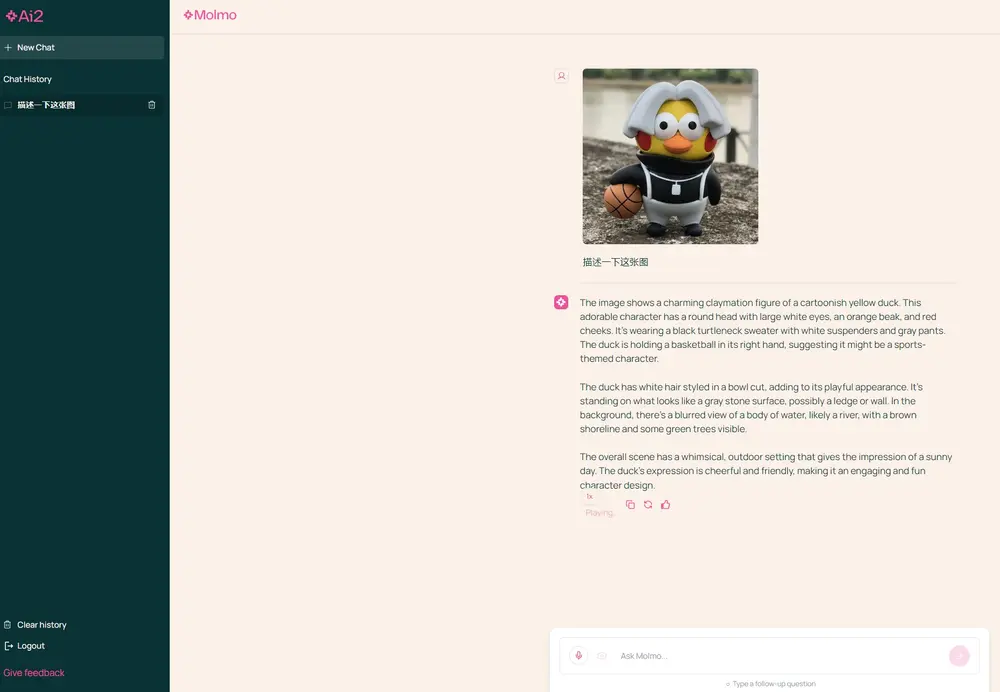
例如,你有一张图片,想要了解图片中的内容,或者有一个与图片相关的问题。Molmo模型能够“看到”图片内容,并结合文本信息给出详细的描述或回答你的问题。比如,你给Molmo一张埃菲尔铁塔的图片,问:“这个塔有多高?”Molmo不仅能识别出图片中的塔,还能告诉你它的高度。
主要功能:
- 图像描述生成:给定一张图片,Molmo能生成详细的描述。
- 视觉问答:Molmo能够回答有关图片内容的问题。
- 指令遵循:Molmo能够理解和执行基于文本的指令。
主要特点:
- 开放性:Molmo是开放的,意味着任何人都可以使用、修改和重新分发它的模型权重和数据。
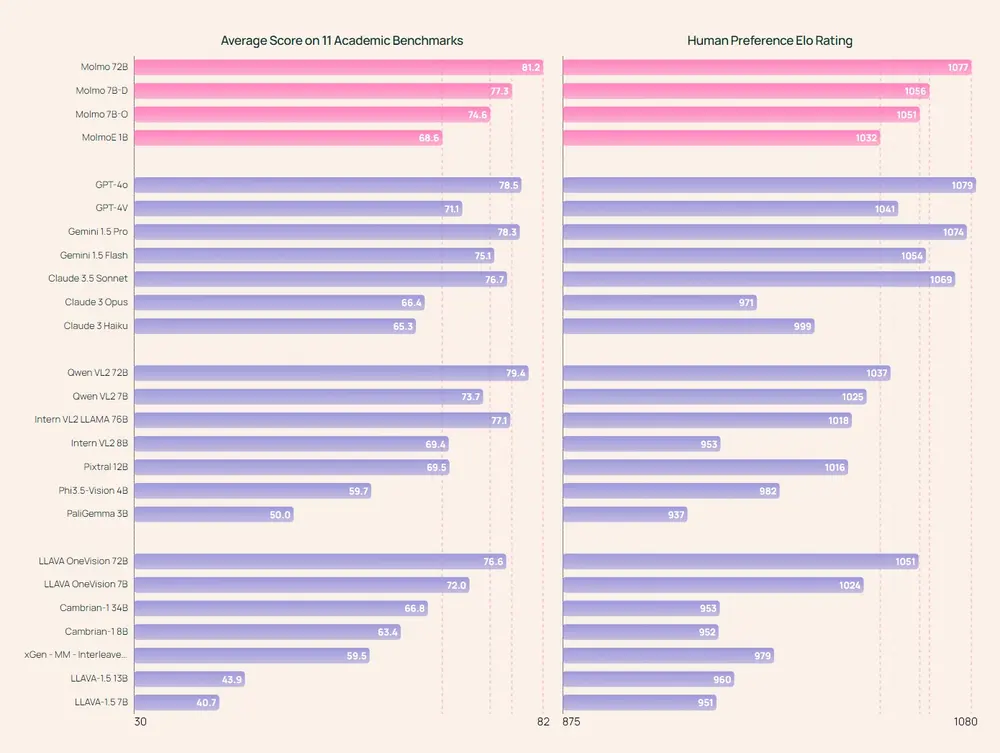
- 高性能:Molmo在多个学术基准测试中表现优异,与一些未公开的模型相比也毫不逊色。
- 创新的数据收集:Molmo使用了一种新颖的、完全由人类注释者使用语音描述图片的数据收集方法。
工作原理:
Molmo由几个关键部分组成:
- 预处理器:将输入的图片转换成多尺度、多裁剪的图片集合。
- 视觉编码器:独立地将这些图片映射成视觉令牌。
- 连接器:将视觉令牌投射到语言模型的输入维度,并减少它们的数量。
- 解码器:一个仅解码器的Transformer语言模型。
Molmo的训练分为两个阶段:
- 多模态预训练:使用新收集的详细、高质量的图片描述数据集进行训练。
- 监督微调:在包括学术数据集和新收集的监督数据集的混合数据上进行微调。
具体应用场景:
- 辅助视觉障碍人士:帮助视觉障碍人士理解周围的环境和对象。
- 教育和学习:在教育领域,Molmo可以为图像提供详细描述,增强学习体验。
- 内容审核:在社交媒体等平台上自动检测和过滤不当内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











