浙大 × 通义实验室提出 UI-S1:用“半在线”训练让 MLLM 更懂图形界面在手机上完成一连串操作——比如从微信复制一段文字,粘贴到备忘录,再分享给钉钉好友——对人类来说是日常小事。但对 AI 来说,这是一次复杂的多步决策挑战。 近年来,基于多模态大语言模型(MLLM)的 G...多模态模型# UI-S1# 多模态大语言模型7个月前03380
北卡教堂山分校新研究:GPT-5、Gemini-2.5-Pro等顶级多模态大语言模型,竟难区分图像90°与270°旋转北卡罗来纳大学教堂山分校的研究团队,针对多模态大语言模型(MLLMs)的空间视觉推理能力展开专项测试——聚焦“图像旋转角度识别”任务(判断图像是否旋转0°、90°、180°、270°)。 GitHub...新技术# RotBench# 多模态大语言模型# 空间视觉推理能力7个月前01520
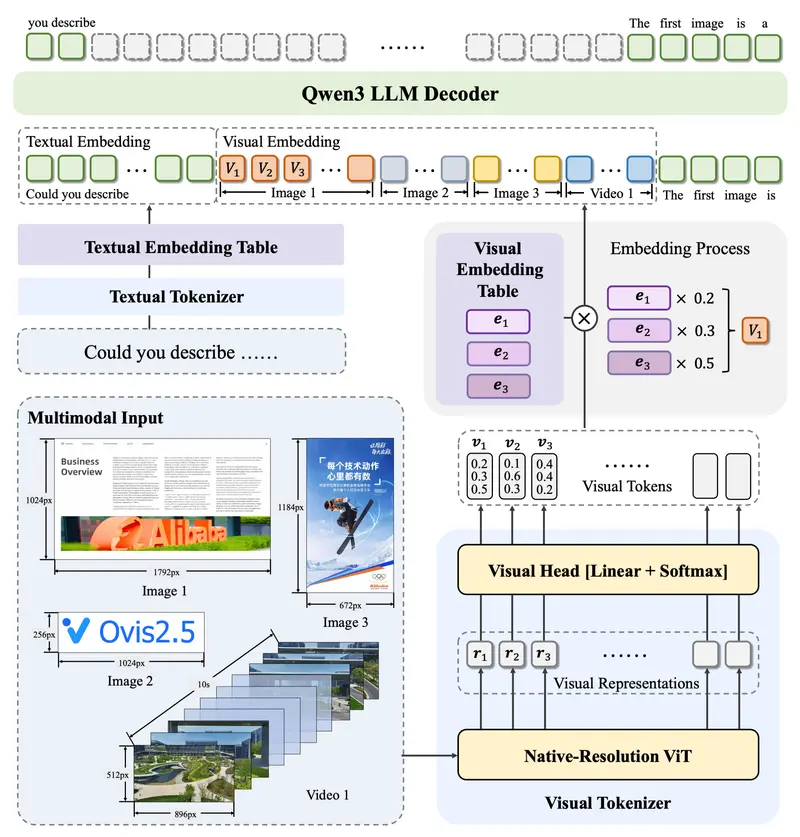
阿里国际发布多模态大语言模型Ovis2.5:原生分辨率视觉感知与深度推理的双重突破阿里国际正式推出 Ovis2.5 —— Ovis2 的继任者,一款在原生分辨率视觉理解和多模态推理能力上实现显著跃升的开源多模态大语言模型(MLLM)。 GitHub:https://github.c...多模态模型# Ovis2.5# 多模态大语言模型# 阿里国际8个月前03230
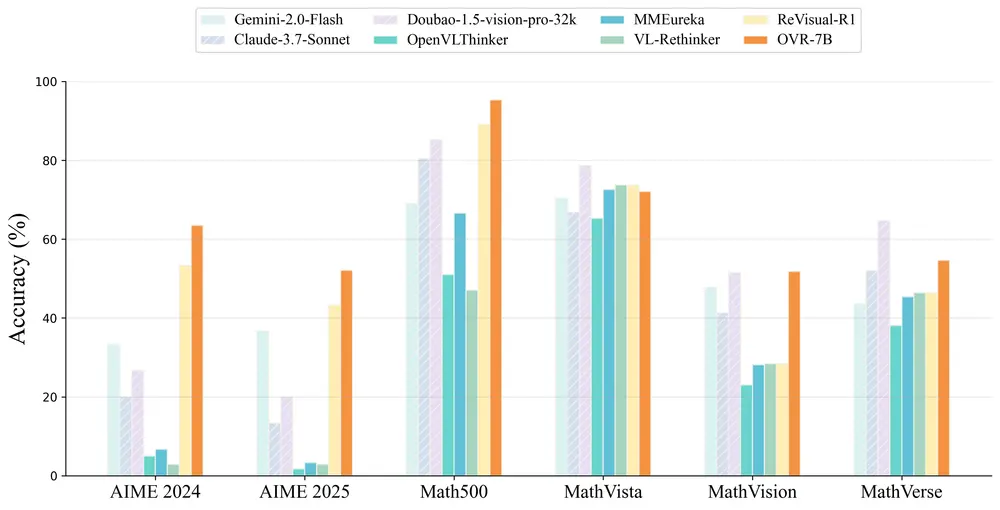
Open-Vision-Reasoner(OVR):基于语言认知迁移的多模态视觉推理新范式大语言模型(LLMs)之所以具备强大的推理能力,关键在于其通过可验证奖励机制的强化学习所涌现的认知行为。那么,是否可以将这一原则迁移至多模态大语言模型(MLLMs),从而解锁其高级视觉推理能力? 本研...多模态模型# Open-Vision-Reasoner# 多模态大语言模型9个月前03420
UniVG-R1:通过推理引导的多模态大语言模型实现通用视觉定位传统视觉定位方法主要关注单图像场景,依赖于简单文本引用。然而,在现实世界中,处理隐含和复杂的指令,尤其是在涉及多图像的情况下,是一个重大挑战,主要原因是缺乏跨多模态上下文的高级推理能力。 项目主页:h...新技术# UniVG-R1# 多模态大语言模型# 视觉定位10个月前02470
英伟达推出多模态大语言模型Describe Anything 3B:为图像和视频局部描述量身定制的多模态 AI 模型英伟达、加州大学伯克利分校和加州大学旧金山分校的研究人员推出了 Describe Anything 3B (DAM-3B),这是一个专门用于生成细粒度图像和视频字幕的多模态大语言模型(LLM)。DAM...多模态模型# Describe Anything 3B# 多模态大语言模型# 英伟达11个月前06140
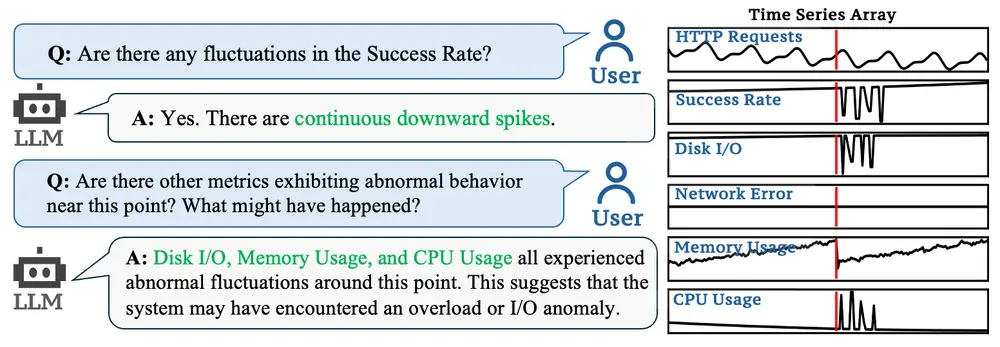
字节跳动推出多模态大语言模型ChatTS:专门用于时间序列分析清华大学和字节跳动的研究人员推出多模态大语言模型ChatTS ,专门用于时间序列分析。它通过自然语言命令帮助用户快速理解时间序列数据,执行日常任务,并处理复杂的推理问题。ChatTS 的核心优势在于其...多模态模型# ChatTS# 多模态大语言模型# 字节跳动12个月前02730
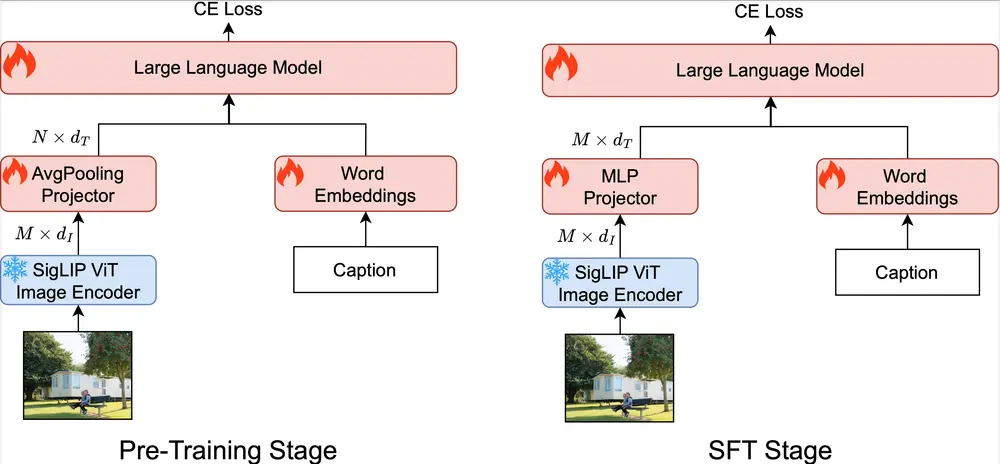
拥有20亿参数的多模态大语言模型Open-Qwen2VL在多模态大语言模型(MLLMs)的研究与应用中,视觉与文本模态的融合正在不断拓展其边界,从图像描述到视觉问答,再到复杂文档的解读,这些模型展现出了强大的能力。然而,这一领域的进一步发展面临着诸多挑战...多模态模型# Open-Qwen2VL# 多模态大语言模型12个月前01920
腾讯推出AnimeGamer:通过多模态大语言模型实现无限动漫生活模拟近年来,图像和视频合成技术的发展为生成游戏带来了新的可能性。特别是将动漫电影中的角色转化为可互动、可玩的实体,让玩家能够以自己喜爱的角色身份沉浸在动态的动漫世界中,通过语言指令进行生活模拟。这种游戏被...多模态模型# AnimeGamer# 多模态大语言模型# 无限动漫生活模拟1年前04700
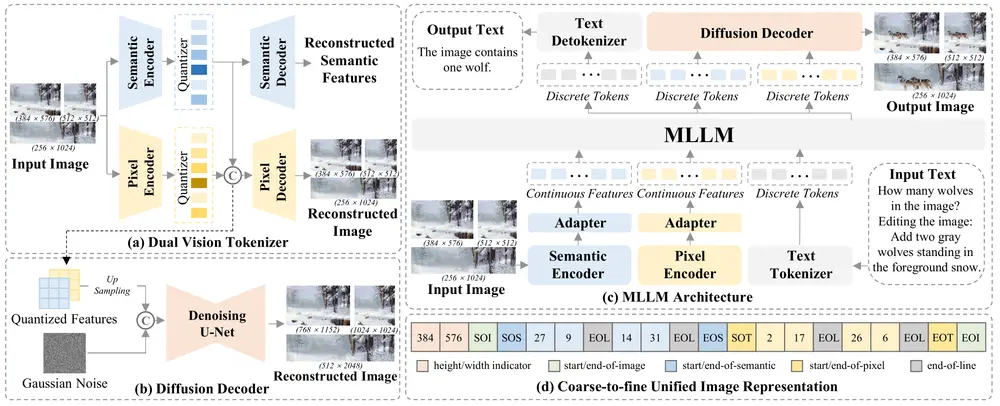
增强版多模态大语言模型ILLUME+ :通过双视觉标记化和扩散解码器来提升深度语义理解和高保真图像生成的能力近年来,多模态大语言模型(MLLMs)在图像理解、生成和编辑任务中取得了显著进展。然而,现有的统一模型在同时处理这三种任务时面临挑战。例如,早期的模型(如 Chameleon 和 EMU3)使用 VQ...多模态模型# ILLUME# 图像生成# 多模态大语言模型1年前05700
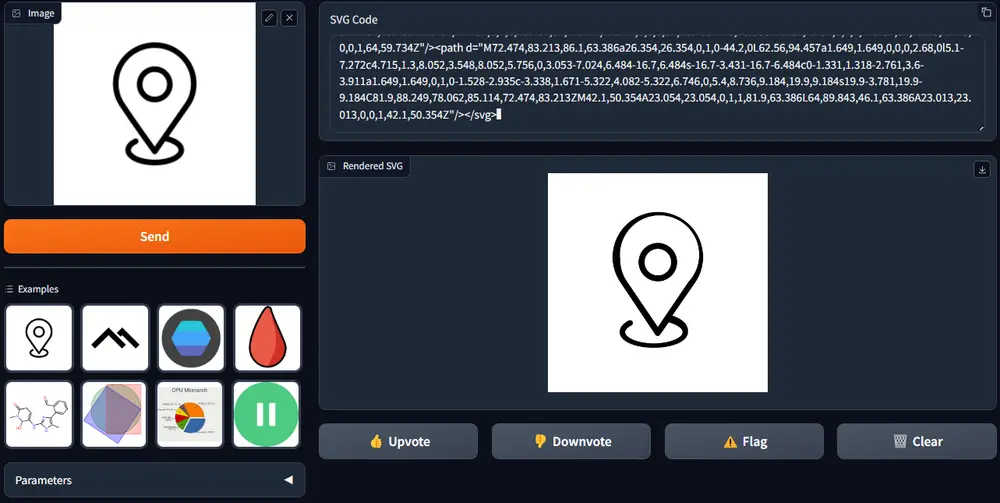
StarVector:利用多模态大语言模型(MLLM)从图像和文本生成SVG代码ServiceNow Research、魁北克人工智能研究所、加拿大 CIFAR 人工智能主席、不列颠哥伦比亚大学、高等工程技术学院和苹果的研究人员推出StarVector,利用多模态大语言模型(ML...图像模型# StarVector# SVG代码# 多模态大语言模型1年前04810
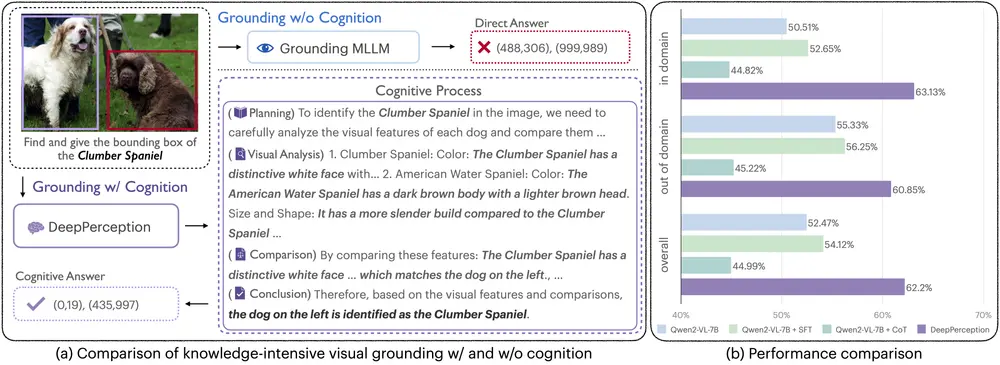
DeepPerception:通过结合知识和推理能力,提升多模态大语言模型在细粒度视觉识别任务中的表现澳门大学、清华大学、西北工业大学和山东大学的研究人员推出DeepPerception,在多模态大语言模型(MLLMs)中推进类似R1的认知视觉感知,用于知识密集型视觉定位。这项研究旨在通过结合知识和推...新技术# DeepPerception# 多模态大语言模型1年前02650