澳门大学、清华大学、西北工业大学和山东大学的研究人员推出DeepPerception,在多模态大语言模型(MLLMs)中推进类似R1的认知视觉感知,用于知识密集型视觉定位。这项研究旨在通过结合知识和推理能力,提升多模态大语言模型(MLLMs)在细粒度视觉识别任务中的表现,特别是在需要领域知识和精细视觉分析的场景中。
- 项目主页:https://deepperception-kvg.github.io
- GitHub:https://github.com/thunlp/DeepPerception
- 模型:https://huggingface.co/MaxyLee/DeepPerception
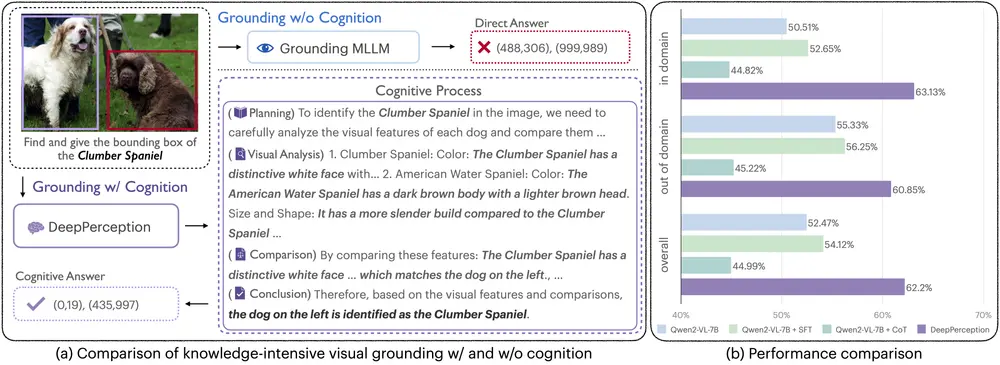
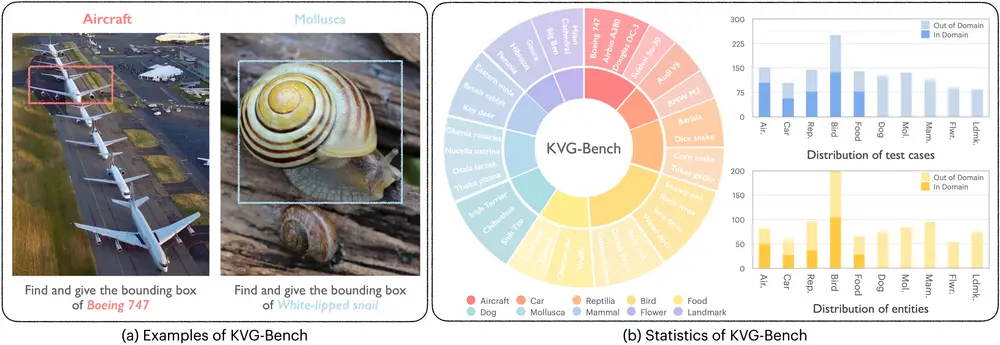
例如,你有一个包含多种飞机的图像,任务是识别出其中的“波音747”。传统的多模态大语言模型可能会直接根据图像中的视觉特征生成答案,但往往缺乏对飞机型号的深入分析。而DeepPerception模型则会利用其内置的知识和推理能力,通过分析飞机的视觉特征(如机翼形状、发动机布局等),并结合领域知识(如波音747的特定设计特征),来准确识别出目标飞机。这种模型不仅能够识别出目标,还能通过推理过程解释其决策依据,类似于人类专家的视觉识别方式。
主要功能
- 知识密集型视觉定位(KVG):DeepPerception能够处理需要领域知识和精细视觉分析的视觉定位任务,例如在复杂图像中识别特定的飞机型号、动物种类或地标。
- 认知增强:模型通过结合知识和推理能力,提升视觉感知的准确性,使其能够像人类专家一样进行细粒度的视觉区分。
- 跨领域泛化:DeepPerception不仅在训练数据覆盖的领域表现出色,还能在未见过的领域中保持良好的泛化能力,显示出其内在的认知机制。
- 自动化数据合成:通过自动化数据合成管道,生成高质量、知识对齐的训练样本,缓解了高质量训练数据稀缺的问题。
- 两阶段训练框架:结合监督式微调(SFT)和强化学习(RL),优化模型的认知能力和视觉感知能力。
主要特点
- 认知视觉感知:DeepPerception通过模拟人类专家的视觉感知过程,将领域知识和推理能力融入视觉分析中,从而实现更准确的视觉定位。
- 知识驱动的推理:模型能够利用其内置的知识库,进行有条理的推理过程,而不仅仅是基于视觉特征的直接匹配。
- 两阶段训练:通过监督式微调(SFT)建立基础的认知能力,然后通过强化学习(RL)进一步优化视觉感知能力,确保模型在训练过程中的稳定性。
- 数据合成:通过自动化数据合成管道,生成高质量的训练样本,提高模型的训练效率和性能。
- 跨领域泛化能力:模型在未见过的领域中表现出色,证明了其内在的认知机制能够适应不同的视觉任务。
工作原理
- 自动化数据合成:
- 从现有的细粒度视觉识别数据集中提取数据,并将其分类到不同的领域。
- 使用预训练的模型(如Qwen2-VL-7B)生成边界框注释,确保注释的准确性。
- 通过合成图像,将多个同类别的实体组合到一个图像中,增加任务的复杂性。
- 监督式微调(SFT):
- 使用生成的链式思考(CoT)数据,对模型进行监督式微调,使其具备基于知识的推理能力。
- 通过输入图像、真实注释和CoT提示,生成详细的推理过程,训练模型进行知识驱动的视觉分析。
- 强化学习(RL):
- 在SFT的基础上,使用强化学习进一步优化模型的视觉感知能力。
- 通过采样多个输出并计算相对优势,优化模型的策略,使其能够生成更精确的边界框。
- 使用规则化的奖励系统,包括IoU奖励和格式奖励,确保模型的输出既准确又符合要求。
应用场景
- 细粒度视觉识别:在需要区分视觉上相似的物体(如不同型号的飞机、不同品种的狗)的场景中,DeepPerception能够提供更准确的识别结果。
- 知识密集型视觉任务:在需要结合领域知识进行视觉分析的任务中,如医学图像分析、文物识别等,DeepPerception能够利用其知识和推理能力,提供更深入的分析。
- 跨领域泛化:在面对未见过的领域时,DeepPerception能够利用其内在的认知机制,保持良好的性能,适用于多领域的视觉任务。
- 自动化标注和数据增强:通过自动化数据合成管道,DeepPerception能够生成高质量的训练数据,提高模型的训练效率和性能。
- 多模态理解:在需要结合视觉和语言信息进行推理的任务中,DeepPerception能够提供更准确的视觉定位和解释,支持更复杂的多模态应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











