谷歌旗下的DeepMind于周三发布了一份长达145页的研究报告,全面阐述了其对通用人工智能(AGI)安全问题的应对策略。AGI被定义为能够完成人类任何任务的AI系统,这一概念在AI领域引发了广泛争议。一方面,质疑者认为AGI不过是不切实际的幻想;另一方面,像Anthropic这样的主流AI实验室则警告称,若不建立防护措施,AGI可能带来灾难性后果。
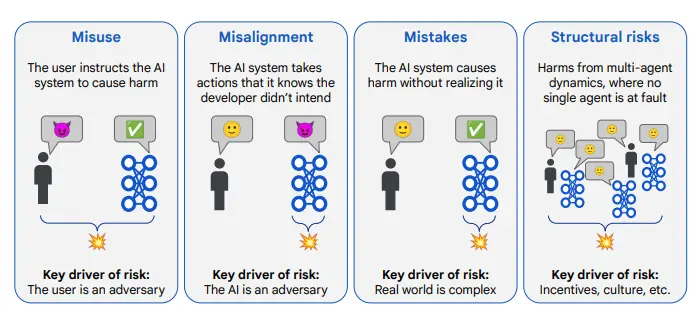
AGI的潜在风险与时间预测
这份由DeepMind联合创始人谢恩·莱格参与撰写的报告预测,AGI可能在2030年前问世,并可能带来“严重危害”。虽然报告未明确定义危害的具体程度,但以“永久毁灭人类”的“生存性风险”作为警示案例。报告指出:“我们预计在本十年末之前将开发出卓越级AGI系统,其能力至少能超越99%熟练成年人在非体力任务(包括学习新技能等元认知任务)上的表现。”
与其他AI实验室的对比
报告开篇将DeepMind的AGI风险应对策略与Anthropic和OpenAI进行了对比。报告指出,Anthropic在“强化训练、监测与安全”方面重视不足,而OpenAI对“自动化”AI安全研究(即对齐研究)过于乐观。DeepMind认为,这两种策略都未能充分考虑AGI的复杂性和潜在风险。
对超级智能AI的谨慎态度
尽管报告承认现有技术可能实现“递归式AI进化”——即AI通过自主研究创造更复杂AI系统的正向循环,但作者对超越人类所有工作的超级智能AI持怀疑态度。报告指出,若无“重大架构创新”,超级智能系统短期内难以出现。然而,这种递归式进化机制可能极其危险,需要高度警惕。
三大安全方向与技术挑战
报告从宏观层面提出了三大应对AGI安全的方向:
- 阻断恶意行为者接触AGI的途径:确保AGI技术不会被恶意利用。
- 增强对AI系统行为的理解:通过研究和监测,更好地理解AI的行为模式。
- “强化”AI行为环境:通过设计更安全的环境来限制AI的行为。
尽管报告承认许多技术尚不成熟且存在“开放性研究问题”,但强调不能忽视潜在的安全挑战。
专家的质疑与现实担忧
然而,这份报告并未能平息所有争议。部分专家对AGI的概念和报告的结论提出了异议。
- AI Now Institute首席科学家海迪·克拉夫认为AGI概念过于模糊,难以“进行严谨科学评估”。
- 阿尔伯塔大学助理教授马修·古兹迪尔质疑递归改进的可行性,认为“这是智能奇点论的理论基础,但从未有任何实证支持”。
- 牛津大学技术与监管研究员桑德拉·瓦赫特指出,更现实的担忧在于AI通过“错误输出”自我强化。她警告说:“随着生成式AI内容充斥网络并逐步取代真实数据,模型正在学习充满谬误的自身输出。当聊天机器人主要被用于搜索和求真时,我们始终面临被极具说服力的谎言误导的风险。”
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...