
新GitHub Copilot 引入“二号大脑”:实验性橡皮鸭模式让 Claude 性能狂飙 75%
在 AI 编程领域,单模型的“自我反思”正面临瓶颈。GitHub 近期在 Copilot CLI 中上线了一项代号为“橡皮鸭(Rubber Ducking)”的实验性功能。通过引入第二个异构 LLM ...

新Anthropic 扩大与谷歌和博通的合作关系,以获取数吉瓦的下一代计算能力
AI 行业的王座,似乎正在悄然易主。 就在今天,Anthropic 官方确认了一个震撼数字:其年化收入(Run-rate Revenue)已突破 300 亿美元。 这是什么概念?作为对比,OpenAI...

新OpenAI “老人”组团做 VC:Zero Shot 基金完成 1 亿美元募集,专投硬核 AI
在 AI 创投圈,最懂下一个风口在哪里的,往往是那些刚刚离开风暴中心的人。 一支名为 Zero Shot 的新风险投资基金,近日宣布完成了 1 亿美元目标的首轮募集。这支基金的阵容堪称“梦幻”:五位创...
新《纽约客》深扒 OpenAI:内部人士称“问题在于 Sam Altman”,信任危机爆发
就在 OpenAI 发布一份宏大的政策建议,承诺将确保超级智能“造福人类”的同一天,《纽约客》发表了一篇长达数万字的调查报告,却指向了一个令人不安的结论:你可能无法相信那个做出承诺的人——Sam Al...

新OpenClaw推出梦境系统 (Dreaming System):让 AI 拥有“睡眠”与记忆巩固能力
梦境 (Dreaming) 是 OpenClaw memory-core 插件中一项实验性的、可选择加入的记忆整合系统。它模拟人类的睡眠机制,通过 浅睡 (Light Sleep)、深睡 (Deep ...
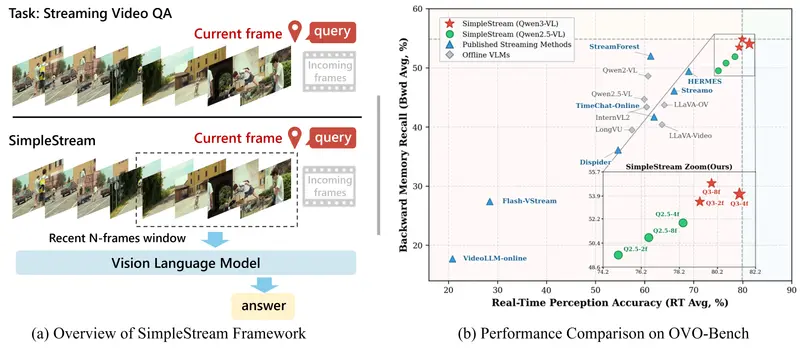
新别卷记忆模块了!南洋理工新发现:只看最近4帧,直接碾压13个SOTA模型
在AI领域,我们常常陷入一种迷思:“模型越复杂、记忆越长,效果就越好。” 尤其是在流式视频理解(Streaming Video Understanding)这一前沿赛道,各大研究团队都在拼命堆砌复杂的...
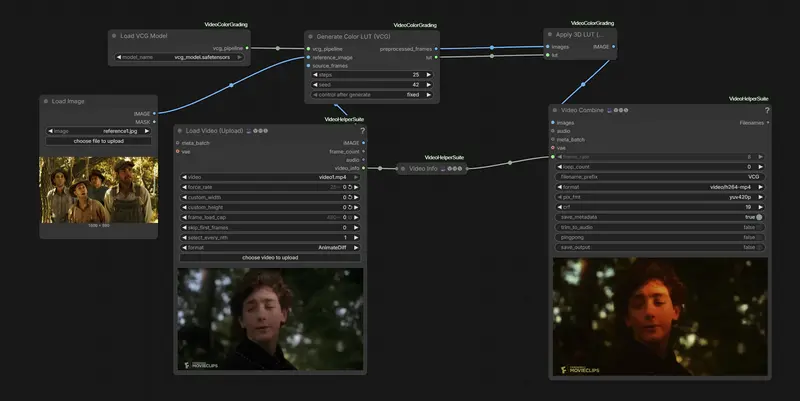
新Kijai 大神新作:ComfyUI-VideoColorGrading,通过自动生成 LUT 来进行视频调色
Kijai 再次发力,为 ComfyUI 社区带来了基于 ICCV 2025 论文《Video Color Grading》的官方实现节点:ComfyUI-VideoColorGrading。 Git...

新Physion Labs推出Galileo-0:迈向可扩展的世界模型评判器
Physion Labs 正式推出了 Galileo-0,这是首个专为世界模型(World Models)设计的自动化评判器。它不再仅仅给生成视频打一个模糊的分数,而是通过结构化的时空推理,精准诊断视...
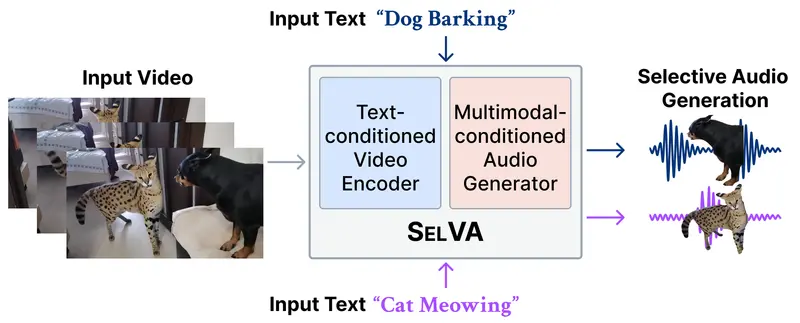
新ComfyUI-SelVA:让视频配音“指哪打哪”的文本控制节点
ComfyUI-SelVA 是将 KAIST 最新研究成果 SelVA 引入 ComfyUI 的自定义节点包。它突破了传统视频转音频模型“有什么画面就配什么声音”的限制,实现了基于文本提示的精准声音选...
新SelVA:基于文本指令的视频选择性配音技术
韩国科学技术院(KAIST)MAC 实验室与梨花女子大学 MMAI 实验室的研究人员共同提出了一项新任务:基于文本条件的选择性视频到音频生成(Text-Conditioned Selective Vi...





