在AI领域,我们常常陷入一种迷思:“模型越复杂、记忆越长,效果就越好。” 尤其是在流式视频理解(Streaming Video Understanding)这一前沿赛道,各大研究团队都在拼命堆砌复杂的记忆模块:建立历史数据库、压缩过往帧信息、设计精密的检索机制……仿佛只有记住视频的每一秒,才能称得上“智能”。
- 项目主页:https://simple-stream.github.io
- GitHub:https://github.com/EvolvingLMMs-Lab/SimpleStream
然而,来自新加坡南洋理工大学 S-Lab 的最新研究却给了这一主流思路一记响亮的耳光。他们提出了一个极简基准方案——SimpleStream,并发现了一个令人震惊的事实:
不用任何复杂记忆,只看最近几帧画面,就能碾压绝大多数精心设计的复杂模型。
背景:被“记忆”绑架的视频 AI
当前的流式视频理解模型(用于实时监控、直播分析、长视频问答等场景)面临一个核心挑战:如何处理无限延长的视频流?
- 主流做法:构建庞大的外部记忆库,存储历史帧的特征;设计复杂的压缩算法,提炼过去的关键信息;开发检索机制,在需要时调取历史片段。
- 默认假设:记得越久、存得越多,理解就越深刻。
- 代价:显存占用爆炸、推理速度变慢、系统架构极其复杂。
SimpleStream 的反叛:
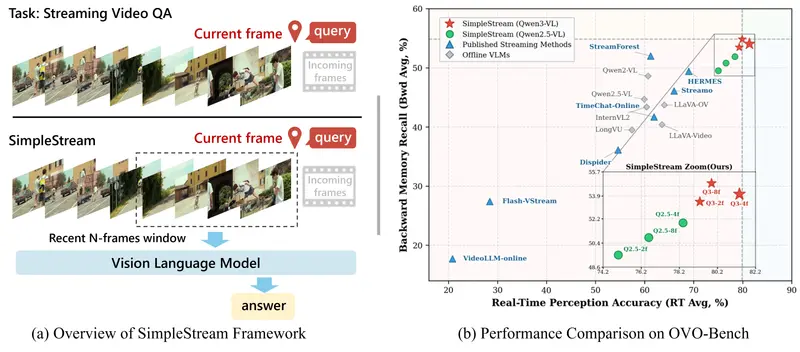
研究团队问了一个简单的问题:如果我们什么都不做,只是把现成的视觉语言模型(VLM)加上一个只保留最近 N 帧的“滑动窗口”,效果会怎样?
结果出乎所有人意料:这个“懒惰”的基线,赢了。
SimpleStream 是什么?
SimpleStream 不是一个全新的模型架构,而是一种极简的处理策略。它的核心逻辑可以用八个字概括:“滑动窗口,只看最近”。
🛠️ 工作原理
- 固定小窗口:
不管视频已经播放了 1 分钟还是 10 小时,AI 的“眼睛”永远只盯着最近的 2 到 8 帧画面。 - 直接喂给模型:
将这几帧最新画面 + 用户的问题,直接输入到一个未经修改的、现成的 VLM(如 LLaVA, Qwen-VL 等)中。 - 无情丢弃历史:
窗口之外的所有画面?全部扔掉。不存储、不压缩、不检索。 - 实时输出:
模型仅凭眼前的视觉证据,瞬间给出回答。
这就好比一个人看视频时,只专注当下眼前发生的剧情,不去刻意回忆几分钟前的细节,反而能最快地反应过来“现在正在发生什么”。
颠覆性的测试结果
研究团队在两个权威基准测试集 OVO-Bench 和 StreamingBench 上,将 SimpleStream 与 13 个 主流的离线及在线视频大模型进行了对比。结果令人咋舌:
| 指标 | SimpleStream (仅 4 帧) | 最强复杂模型 | 结论 |
|---|---|---|---|
| OVO-Bench 准确率 | 67.7% | ~59.2% | 领先 8.5% 🚀 |
| StreamingBench 准确率 | 78.95% - 80.6% | < 75% | 全面超越 🏆 |
| 显存占用 | 极低 (恒定) | 高 (随时间增长) | 效率完胜 💾 |
| 响应速度 | 极快 | 较慢 (受检索拖累) | 实时性最佳 ⚡ |
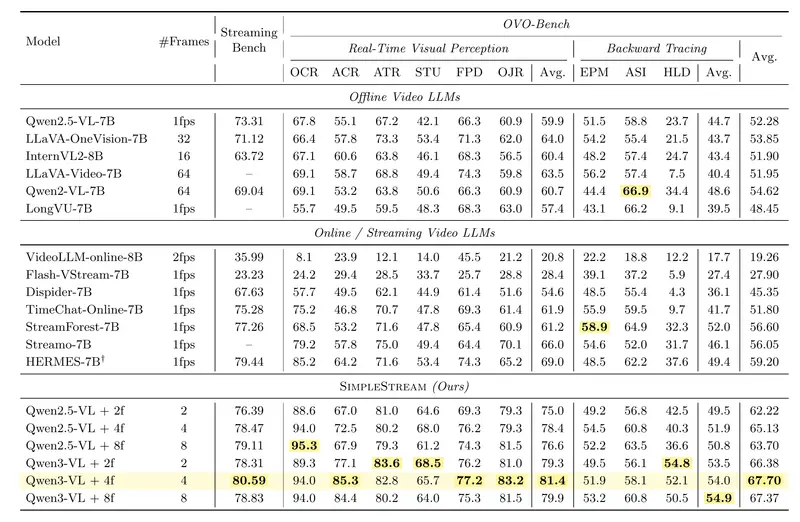
关键发现
- 简单即强大:
仅仅使用最近 4 帧,SimpleStream 就在多项指标上夺魁。这证明对于大多数实时感知任务,近期的视觉证据远比遥远的历史记忆重要。 - 感知 - 记忆权衡 (Perception-Memory Trade-off):
这是一个反直觉的发现:强行增加历史记忆,虽然能提升一点点“回忆能力”(比如问“一分钟前那个人穿了什么”),但会显著削弱“实时感知能力”(比如问“现在那个人在做什么”)。- 原因:过多的历史信息会干扰模型对当前画面的注意力,导致“看不清当下”。
- 更多帧 ≠ 更好:
消融实验显示,准确率随着窗口大小呈现非单调变化。- 2 帧:信息略少。
- 4 帧:最佳甜蜜点 (Sweet Spot),准确率达到峰值 (67.7%)。
- 8 帧及以上:性能持平甚至下降。
- 这直接打脸了“上下文越长越好”的传统假设。
- 基准测试的偏差:
现有的基准测试往往偏向于“感知导向”的任务(即询问当前发生了什么)。在这种设定下,能够清晰保留近期视觉证据的方法(如 SimpleStream)天然占据优势,而复杂记忆模型反而因为噪声干扰而表现不佳。
为什么 SimpleStream 能赢?
- 专注当下:
流式视频的核心需求往往是实时反应(如自动驾驶避障、监控异常检测)。这时候,0.5 秒前的画面比 30 秒前的画面重要一万倍。SimpleStream 完美契合了这一需求。 - 避免噪声干扰:
复杂的记忆模块在存储和检索过程中,难免引入压缩误差或检索错误。这些“噪声”会误导模型。SimpleStream 没有中间商赚差价,原始画面直供模型,纯净度最高。 - 算力恒定:
无论视频多长,SimpleStream 的计算量永远固定在几帧图像上。这意味着它可以在低端设备上流畅运行,且永远不会随着视频时长增加而变卡。
对未来的启示
SimpleStream 的出现,给整个视频 AI 社区敲响了警钟:
- 拒绝为了复杂而复杂:不要盲目堆砌记忆模块。如果一个简单的滑动窗口基线都能打败你的复杂模型,那说明你的创新可能只是增加了开销,而非带来了实质进步。
- 重新定义评估标准:未来的基准测试应该将“近期场景感知”与“长期记忆 recall”分开评估。不能只用一个总分来掩盖模型在实时感知上的短板。
- 实用主义回归:对于工业界应用(如安防、直播互动),SimpleStream 这种低成本、高效率、高性能的方案,才是真正落地的首选。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...