在处理 20 万 token 甚至更长的上下文时,大型语言模型(LLM)往往面临“又贵又慢”的困境。随着上下文长度增加,计算成本呈平方级飙升,成为阻碍长文档分析、复杂智能体工作流落地的最大瓶颈。
- 论文:https://arxiv.org/abs/2603.12201
- GitHub:https://github.com/THUDM/IndexCache
近日,清华大学与智谱 AI 的研究团队推出了一项突破性优化技术——IndexCache。该技术专为采用 DeepSeek 稀疏注意力架构 (DSA) 的模型(如 DeepSeek-V3.2、GLM-4/5 系列)设计,通过消除冗余计算,在 200K 上下文长度下实现了:
- 🚀 首 Token 生成时间(预填充):加快 1.82 倍(从 19.5 秒降至 10.7 秒)。
- ⚡ 生成吞吐量(解码):提升 1.48 倍(从 58 tokens/s 增至 86 tokens/s)。
- 💰 部署成本:降低约 20%,且零精度损失。
核心痛点:稀疏注意力的“阿喀琉斯之踵”
为了解决传统自注意力机制 $O(N^2)$ 的复杂度问题,DeepSeek 稀疏注意力 (DSA) 引入了一个轻量级的“闪电索引模块”。它像搜索引擎一样,先对所有历史 token 打分,只选出最相关的子集交给主注意力机制处理,从而将计算量从平方级降为线性级。
然而,研究人员发现了一个隐藏瓶颈:
虽然主注意力变快了,但那个负责“挑选 token"的索引器本身,在每一层仍然以平方级复杂度运行!
- 当上下文极长时,模型把大量时间花在了“反复挑选”上。
- 尤其是在处理长提示词的初始阶段(Pre-fill),索引器的开销成为了新的拖油瓶。
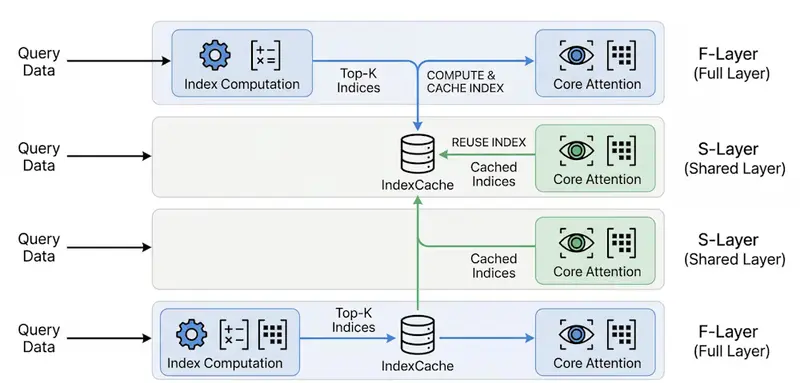
IndexCache 的巧妙解法:跨层复用,拒绝重复劳动
研究团队观察到一个关键现象:在相邻的 Transformer 层中,索引器选出的“重要 Token"高度重合(共享率高达 70%-100%)。这意味着,每一层都重新算一遍索引完全是浪费!
IndexCache 的核心逻辑:
- 分层策略:将模型层分为两类:
- 完整层 (Full Layers):保留索引器,正常计算并缓存选出的 Token 索引。
- 共享层 (Shared Layers):移除索引器,直接复用前一个完整层的缓存索引。
- 动态跳过:推理时,遇到共享层直接跳过昂贵的索引计算步骤,复制缓存数据即可。
形象比喻:以前是每过一道门都要重新检查一遍身份证(每层都算索引);现在只需在入口检查一次(完整层),后面几道门直接放行(共享层复用)。
两种部署模式:开箱即用 vs 深度优化
IndexCache 提供了灵活的落地方案,适应不同需求的团队:
1. 无需训练模式 (Training-Free) —— 推荐大多数开发者
- 原理:利用“贪婪层选择”算法,只需跑一个小规模的校准数据集,自动找出哪些层可以安全地变为“共享层”。
- 效果:可安全移除 75% 的索引器,性能与原版几乎无异。
- 优势:无需重新训练模型,无需修改权重,现有 DSA 模型(如 DeepSeek, GLM)可直接应用。
2. 训练感知模式 (Training-Aware) —— 适合原厂或微调团队
- 原理:在预训练或微调阶段引入“多层蒸馏损失”,强制让保留的索引器学习选出“通用性强”的 Token,以服务于后续多个共享层。
- 效果:理论上能达到更极致的压缩率和性能平衡。
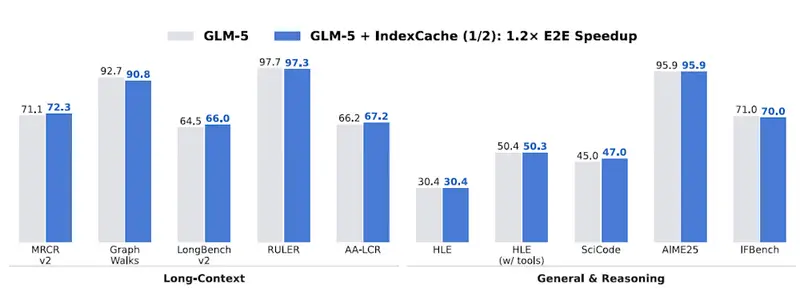
实测表现:速度与质量双赢
在 GLM-4.7 Flash (30B) 和 GLM-5 (744B) 上的测试数据令人振奋:
| 指标 | 基准 (Baseline) | IndexCache (移除 75% 索引器) | 提升幅度 |
|---|---|---|---|
| 200K 预填充延迟 | 19.5 秒 | 10.7 秒 | 🚀 1.82x |
| 解码吞吐量 | 58 tokens/s | 86 tokens/s | ⚡ 1.48x |
| 长上下文基准得分 | 50.2 | 49.9 | ✅ 持平 |
| AIME 2025 数学推理 | 91.0 | 92.6 | 📈 超越原版 |
注:在饱和负载下,服务器总解码吞吐量甚至提升了 51%。
产业意义:长上下文应用的“加速器”
IndexCache 的出现,直接击中了企业级应用的痛点:
- RAG (检索增强生成):处理超长文档库时,响应速度显著提升。
- 智能体工作流:多步推理需要维持极长记忆,IndexCache 让 Agent 不再因上下文过长而“卡顿”。
- 成本节约:对于按 Token 或时长计费的云服务,20% 的成本降低意味着巨大的利润空间。
目前,针对主流推理引擎(如 vLLM, SGLang)的开源补丁已可在 GitHub 获取。开发者只需应用补丁并进行简单的配置校准,即可让现有的 DeepSeek/GLM 系列模型瞬间“提速”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...