
谷歌在 AI 语音交互领域再次迈出关键一步。今日,谷歌正式推出 Gemini 3.1 Flash Live,称其为“迄今为止最高质量的音频和语音模型”。这款新模型不仅大幅降低了延迟,更在语调理解、情绪感知和多语言支持上实现了质的飞跃,旨在为开发者、企业和普通用户打造真正“像人一样”的实时对话体验。
- 官方介绍:https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-live

核心突破:从“听懂字面”到“听懂情绪”
Gemini 3.1 Flash Live 的最大亮点在于其对人类交流细微差别的深刻理解:
1. 情绪感知与动态调整
- 声学细微差别识别:模型能精准捕捉用户语音中的音高、语速、停顿等特征。
- 情绪响应:当检测到用户表现出沮丧、困惑或犹豫时,模型会自动调整回应策略——例如放慢语速、简化解释或主动提供安抚性引导,而非机械地重复标准答案。
- 自然节奏:生成的语音不再是单调的朗读,而是具备自然的呼吸感、重音和情感起伏,极大提升了对话的沉浸感。
2. 极速响应与长程记忆
- 低延迟:专为实时交互优化,响应速度显著快于前代模型(2.5 Flash Native Audio),实现真正的“即问即答”。
- 超长上下文保持:在长时间对话(如头脑风暴、复杂任务规划)中,模型保持对话线索的能力延长了一倍,不再容易“聊着聊着就忘了前面说什么”。
3. 真正的全球通用
- 200+ 语言/地区支持:模型原生支持全球超过 200 种语言和地区变体。
- 无缝切换:用户可使用母语自由交互,无需手动设置语言区域。这也直接推动了谷歌“实时搜索”功能本周的全球大规模上线。
性能基准:刷新行业纪录
在权威测试中,Gemini 3.1 Flash Live 展现了统治级性能:
| 基准测试 | 指标 | 得分 | 表现评价 |
|---|---|---|---|
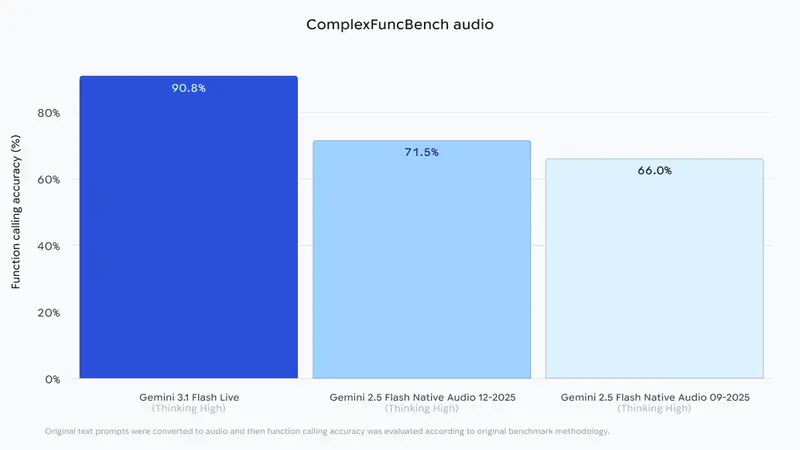
| ComplexFuncBench Audio | 复杂任务执行 | 90.8% | 显著优于前代模型,证明其在处理多步骤语音指令时的可靠性。 |
| Scale AI Audio MultiChallenge | 抗干扰与长推理 | 36.1% (开启"思考"模式) | 在充满中断、犹豫和噪音的真实音频场景中,依然能精准遵循复杂指令并进行长周期推理,位列榜首。 |
企业反馈:Verizon、LiveKit 和 The Home Depot 等早期采用者表示,新模型在客服场景中的表现更加自然,能有效降低用户挫败感,提升问题解决率。
全场景覆盖:从个人助手到企业客服
Gemini 3.1 Flash Live 已全面铺开,服务于不同层级的用户需求:
- 📱 个人用户:
- Google 搜索实时功能:举起手机,用任何语言与世界对话。
- Gemini Live:享受更流畅、更智能的私人 AI 伴侣体验。
- 🏢 企业客户:
- Gemini Enterprise (Customer Experience):构建能感知客户情绪、动态调整策略的超级客服智能体。
- 💻 开发者:
- Gemini Live API (Google AI Studio):调用强大的语音推理能力,构建下一代语音优先应用。
安全与责任:SynthID 水印
为了防止 AI 生成音频被滥用或误导公众,谷歌在所有由 Gemini 3.1 Flash Live 生成的音频中嵌入了 SynthID 水印。
- 隐形标记:水印直接嵌入音频波形中,人耳无法察觉,但可通过专用工具可靠检测。
- 溯源防伪:有助于识别 AI 生成内容,打击深度伪造(Deepfake)和虚假信息传播。
语音优先时代的基石
Gemini 3.1 Flash Live 的发布,标志着谷歌在“语音优先 (Voice-First)” AI 战略上的坚定投入。
- 技术护城河:通过情绪理解和多语言支持,构建了难以复制的体验壁垒。
- 生态整合:将最强语音模型注入搜索、助手、企业云服务,形成闭环。
- 开发者赋能:让中小开发者也能利用顶级语音 AI 构建创新应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...





