新DiffHDR:用视频扩散模型“复活”丢失的光影,实现可控 LDR 到 HDR 转换大多数数字视频受限于存储格式,以 8 位低动态范围(LDR) 保存。这意味着原始场景中丰富的高光细节(如云层纹理、灯光光晕)和阴影层次(如暗部织物、夜景角落)因饱和与量化而永久丢失。这不仅限制了在 H...新技术# DiffHDR2天前060
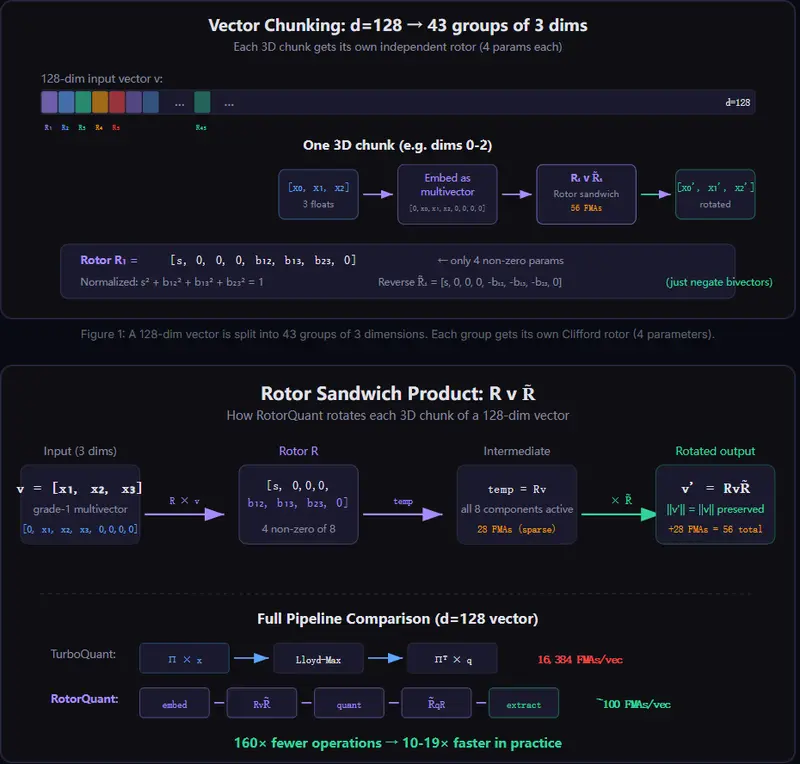
新RotorQuant:LLM KV 缓存压缩的“几何革命”,速度提升 5 倍,参数减少 44 倍RotorQuant 是一项突破性的 KV 缓存量化技术,旨在解决大型语言模型(LLM)在长上下文推理中的显存瓶颈。通过引入块对角旋转(Block-Diagonal Rotation)替代传统的蝴蝶网...新技术# RotorQuant2天前060
Cursor推出MoE推理加速方法Warp Decode:翻转并行轴,MoE 推理提速 1.84 倍的硬件级优化在英伟达 Blackwell GPU 上,针对小批量(Small Batch)自回归解码场景,一种名为 Warp Decode 的新内核设计彻底改变了混合专家(MoE)模型的推理方式。通过翻转并行性轴...新技术# Cursor# Warp Decode# 推理加速4天前0110
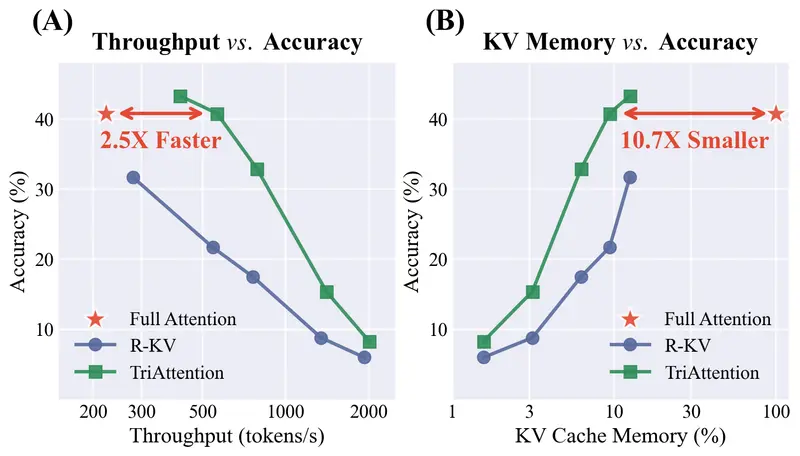
TriAttention:基于三角 KV 压缩的高效长推理,让 32B 模型在 24GB 显存上流畅运行麻省理工学院、英伟达和浙江大学的研究人员联合推出了一项突破性技术——TriAttention。这是一种基于三角级数(Triangular Series)的 KV 缓存压缩方法,解决大型语言模型(LLM...新技术# TriAttention4天前0330
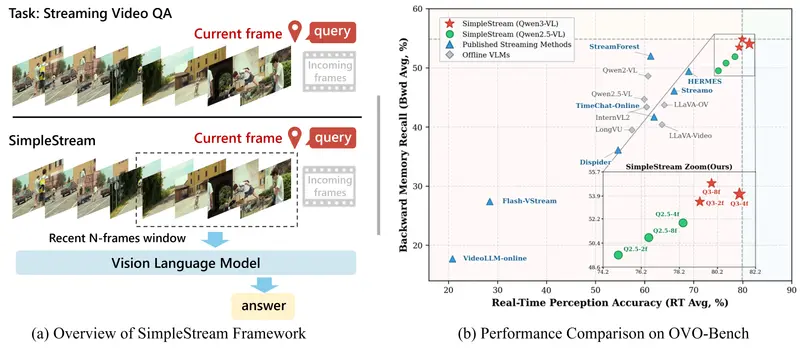
别卷记忆模块了!南洋理工新发现:只看最近4帧,直接碾压13个SOTA模型在AI领域,我们常常陷入一种迷思:“模型越复杂、记忆越长,效果就越好。” 尤其是在流式视频理解(Streaming Video Understanding)这一前沿赛道,各大研究团队都在拼命堆砌复杂的...新技术# SimpleStream5天前0120
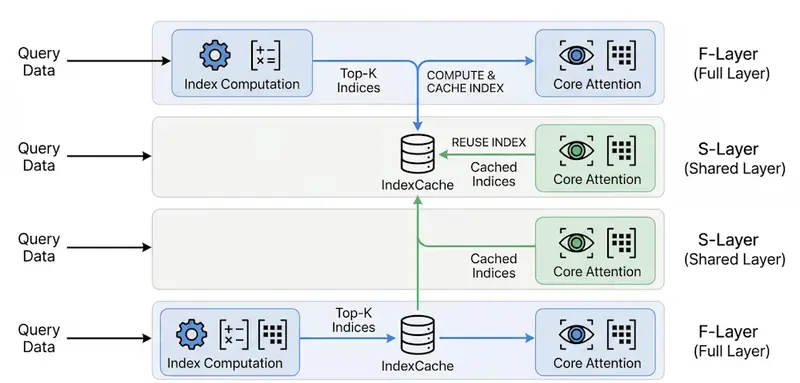
IndexCache:解锁长上下文 AI 的“速度密码”,推理提速高达 1.82 倍在处理 20 万 token 甚至更长的上下文时,大型语言模型(LLM)往往面临“又贵又慢”的困境。随着上下文长度增加,计算成本呈平方级飙升,成为阻碍长文档分析、复杂智能体工作流落地的最大瓶颈。 论文...新技术# IndexCache6天前0130
Hugging Face发布TRL v1.0 :统一大模型后训练工作流,从 SFT 到 DPO/GRPO 一站式解决Hugging Face 正式发布了 TRL (Transformer Reinforcement Learning) v1.0。这标志着该库从一个主要用于学术研究的实验性仓库,正式转型为稳定、生产就...新技术# Hugging Face# TRL v1.01周前0290
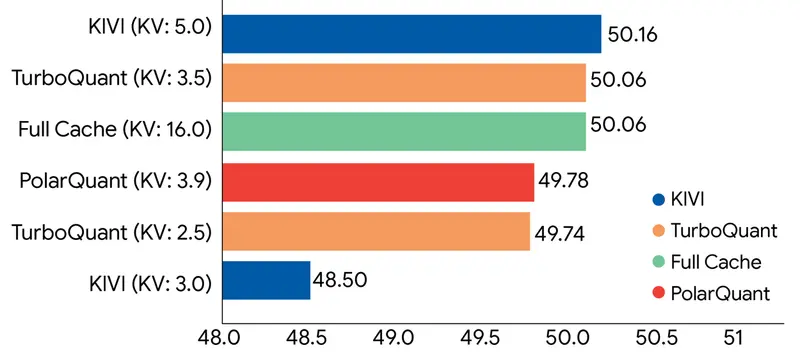
TurboQuant:谷歌新算法实现零精度损失压缩,KV Cache 内存缩减 6 倍在大型语言模型(LLM)向更长上下文、更复杂任务演进的过程中,显存瓶颈已成为制约效率的关键障碍。尤其是键值缓存(KV Cache),随着序列长度增加呈线性增长,不仅占用大量显存,还限制了推理速度和并发...新技术# KV Cache# TurboQuant# 谷歌2周前0580
PaCo-RL:西安交大首创“一致性裁判”强化学习框架,让AI生成四张图也能保持角色与风格完美统你是否曾有过这样的经历:想让AI画一组连环画,比如“一只狐狸在森林、舞台、海边、卧室弹吉他”,结果AI生成的四张图里,狐狸变成了四种不同的动物,吉他变了样,画风也从油画突变成了水彩? 这就是AI绘画领...新技术# PaCo-RL3周前0870
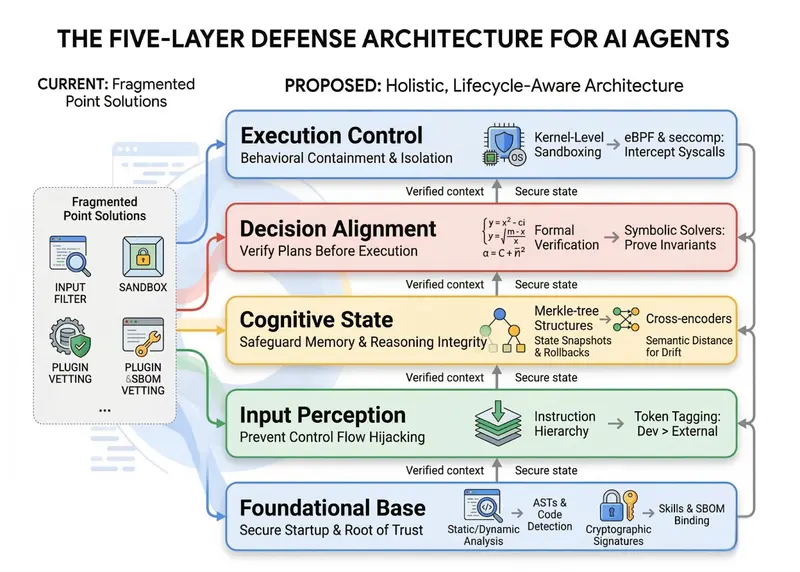
清华与蚂蚁发布 OpenClaw 五层安全框架:揭示技能投毒与内存污染风险,构建全生命周期纵深防御随着 OpenClaw 等自主 LLM 智能体从“被动问答”进化为能执行高权限系统任务的“主动实体”,其面临的安全挑战也发生了质变。 论文地址:https://arxiv.org/pdf/2603.1...新技术# OpenClaw3周前0180
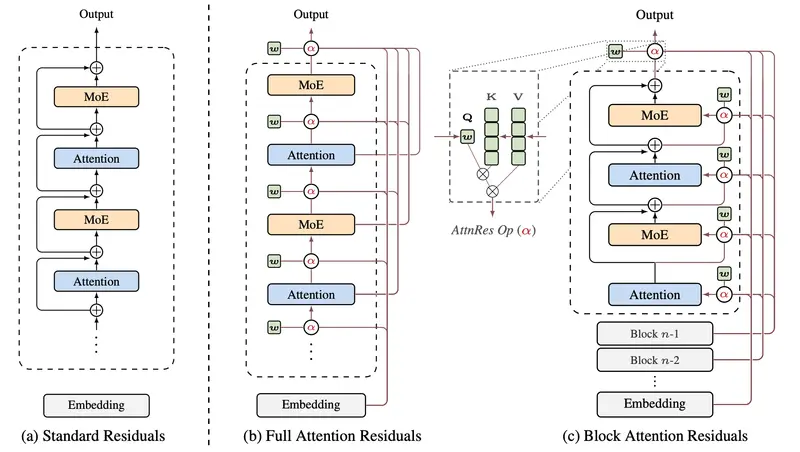
月之暗面发布 Attention Residuals:用深度注意力替代固定残差,Kimi Linear 多项基准性能显著提升在现代 Transformer 架构中,残差连接(Residual Connection)一直是维持深层网络训练稳定的基石。然而,月之暗面(Moonshot AI)的研究人员指出,这种沿用多年的标准机...新技术# Attention Residuals# Kimi# 月之暗面3周前0170
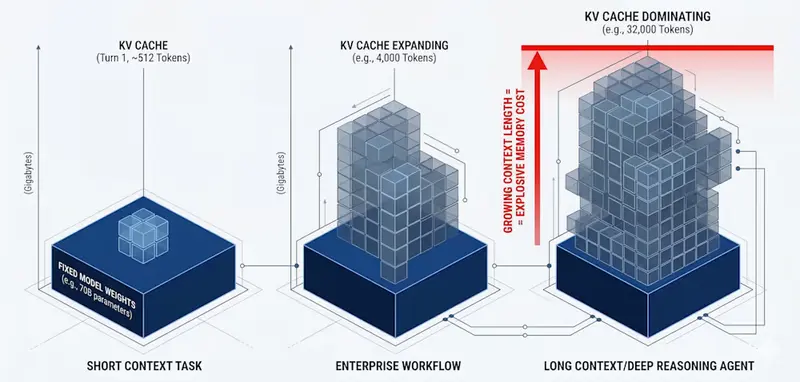
英伟达发布 KVTC 新技术:无需改模型即可将 LLM 内存占用缩小 20 倍,首字延迟降低 8 倍在大语言模型(LLM)的推理过程中,有一个长期存在的痛点:随着对话变长,显存占用呈线性甚至指数级增长。这就是著名的 KV 缓存(Key-Value Cache) 瓶颈。 现在,英伟达(NVIDIA)的...新技术# KVTC# 英伟达3周前0240