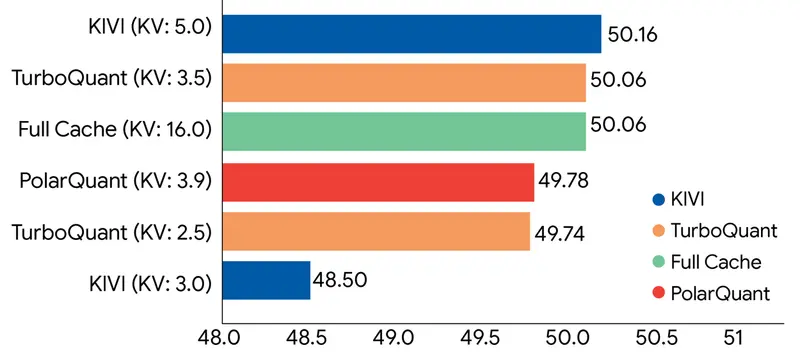
新TurboQuant:谷歌新算法实现零精度损失压缩,KV Cache 内存缩减 6 倍在大型语言模型(LLM)向更长上下文、更复杂任务演进的过程中,显存瓶颈已成为制约效率的关键障碍。尤其是键值缓存(KV Cache),随着序列长度增加呈线性增长,不仅占用大量显存,还限制了推理速度和并发...新技术# KV Cache# TurboQuant# 谷歌1天前0150