在大型语言模型(LLM)向更长上下文、更复杂任务演进的过程中,显存瓶颈已成为制约效率的关键障碍。尤其是键值缓存(KV Cache),随着序列长度增加呈线性增长,不仅占用大量显存,还限制了推理速度和并发能力。
- 官方介绍:https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression
谷歌推出 TurboQuant —— 一套基于坚实数学理论的先进量化算法组合。它通过极致的压缩技术,在零精度损失的前提下,将 KV Cache 内存占用减少至少 6 倍,并在 H100 GPU 上实现高达 8 倍 的注意力计算加速。这不仅是工程上的优化,更是向量量化领域的理论突破。
核心痛点:传统量化的“内存开销”陷阱
向量量化是压缩高维数据的经典手段,能有效减小 KV Cache 规模并加速向量搜索。然而,传统方法往往陷入一个悖论:
- 隐藏成本:大多数量化方案需要为每个数据块存储额外的“量化常数”(如缩放因子、零点),每块增加 1-2 比特。
- 抵消收益:这些额外开销部分抵消了量化带来的压缩收益,尤其在极低比特(如 2-4 bit)场景下尤为明显。
TurboQuant 的出现,正是为了彻底解决这一“内存开销”难题。它由三大核心技术组成:TurboQuant 主算法、QJL (Quantized Johnson-Lindenstrauss) 和 PolarQuant。
技术原理:两步走的极致压缩
TurboQuant 的工作流程精妙而高效,分为两个关键阶段:
1. 高质量压缩:随机旋转 + 分块量化
- 随机旋转:首先对数据向量进行随机旋转。这一数学技巧巧妙地简化了数据的几何结构,使其分布更加均匀。
- 分块量化:旋转后,可以对向量的每个部分独立应用标准的高质量量化器。第一阶段利用大部分压缩预算,精准捕捉原始向量的主要概念和强度信息。
2. 消除隐藏误差:QJL 纠错
- 残差处理:第一阶段量化后留下的微小误差(残差),由 QJL 算法处理。
- 数学纠错:QJL 充当“数学错误检查器”,利用剩余的少量压缩能力消除偏差,确保最终的注意力分数计算准确无误。
两大创新子算法:QJL 与 PolarQuant
🔹 QJL:零开销的 1 比特奇迹
Quantized Johnson-Lindenstrauss (QJL) 是 TurboQuant 的核心亮点之一:
- 降维保距:基于 Johnson-Lindenstrauss 引理,在高维空间中随机投影,保持数据点间的相对距离关系。
- 符号位压缩:将复杂的残差向量压缩为仅 1 个符号位(+1 或 -1)。
- 零内存开销:由于只需存储符号,无需额外的缩放因子,实现了真正的零内存开销。
- 智能估计:配合特殊的估计器,平衡高精度查询与低精度数据,确保注意力机制的准确性。
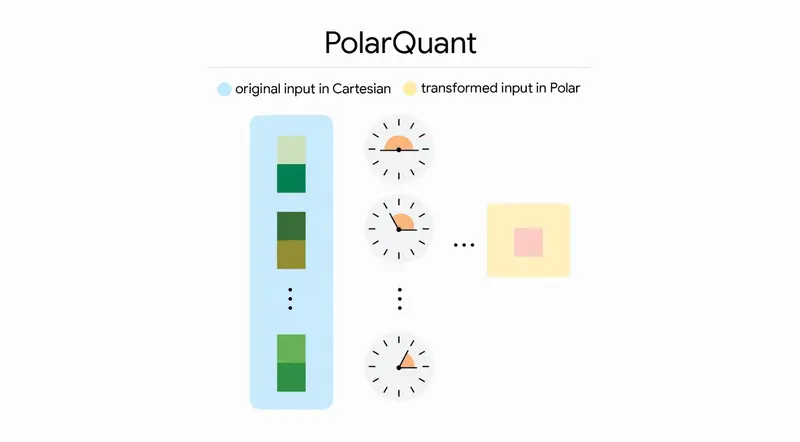
🔹 PolarQuant:极坐标下的新视角
PolarQuant 则提供了另一种颠覆性的思路:
- 坐标转换:摒弃传统的笛卡尔坐标系,将向量转换为极坐标(半径 + 角度)。
- 模式利用:发现角度的分布具有高度集中且已知的模式,因此无需昂贵的归一化步骤。
- 消除开销:直接利用这一特性,省去了传统方法中必须存储的归一化参数,从而消除了内存开销。
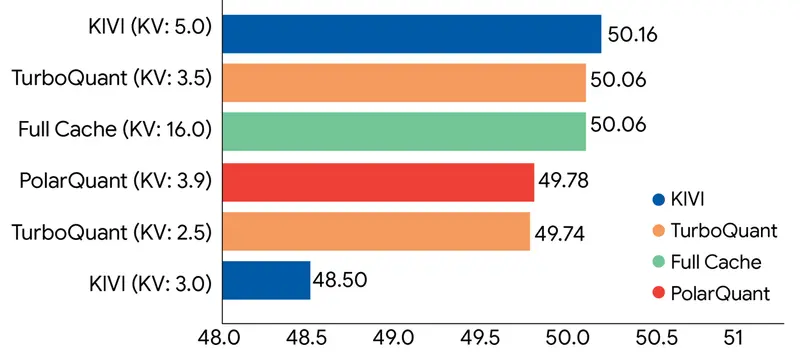
实验结果:性能与效率的双重飞跃
谷歌在标准长上下文基准测试中对 TurboQuant 进行了严格评估,结果令人瞩目:
| 指标 | 表现 | 对比基线 |
|---|---|---|
| 内存压缩率 | ≥ 6 倍 | 相比 32-bit 未量化 KV Cache |
| 量化比特数 | 3-bit | 无需训练或微调 |
| 精度损失 | 零损失 | 在“大海捞针”等长上下文任务中完美复现 |
| 推理加速 | 高达 8 倍 | 在 NVIDIA H100 GPU 上,4-bit TurboQuant vs 32-bit |
| 向量搜索召回率 | 最优 | 优于现有 SOTA 方法 |
- 长上下文能力:在极具挑战性的“大海捞针”(Needle In A Haystack)任务中,TurboQuant 在所有测试长度下均取得完美结果,证明其无损压缩的真实性。
- 向量搜索增强:在高维向量搜索场景中,TurboQuant 不仅加速了索引构建,还实现了更高的召回率,展现了其在语义搜索领域的巨大潜力。
深远影响:从 LLM 到语义搜索
TurboQuant 的意义远超单一的模型优化:
- 打破显存墙:让消费级显卡运行超长上下文模型成为可能,大幅降低部署成本。
- 加速推理:显著减少内存带宽压力,提升吞吐量,使实时 AI 应用更加流畅。
- 重塑搜索:为数十亿级向量数据库提供高效索引方案,推动搜索引擎从“关键词匹配”向“语义理解”全面转型。
- 理论奠基:作为有强数学证明的基础算法,TurboQuant、QJL 和 PolarQuant 为未来的大规模 AI 系统提供了稳健可靠的底层支撑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...