在 AI 模型竞相追求更大参数、更强能力的今天,谷歌反其道而行之,推出了 Gemini 3.1 Flash-Lite。这款专为高容量、低延迟、低成本场景打造的新模型,旨在证明:在速度与效率的赛道上,轻量级模型也能爆发惊人能量。

即日起,该模型已通过 Google AI Studio 和 Vertex AI 向开发者和企业开放预览版。
核心突破:极速响应,极致省钱
Gemini 3.1 Flash-Lite 并非简单的“缩水版”,而是在特定维度上的全面进化:
1. 速度飞跃
与前代旗舰 Gemini 2.5 Flash 相比,新版实现了显著的性能跃升:
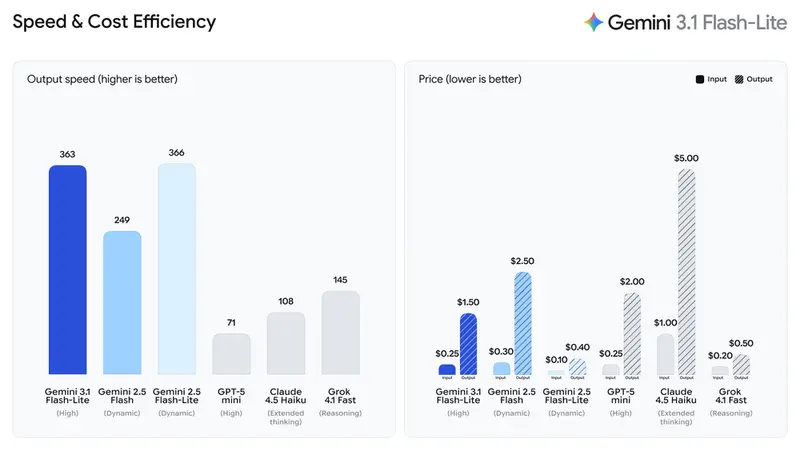
- 首次回答时间 (Time to First Token):快了 2.5 倍。这意味着用户几乎在发送指令的瞬间就能看到回复开始生成,极大提升了实时交互体验。
- 输出速度:提高了 45%。长文本生成、代码补全等任务的完成时间大幅缩短。
2. 颠覆性定价
谷歌将成本压到了新低点,使其成为大规模部署的理想选择:
- 输入价格:$0.25 / 百万 Token
- 输出价格:$1.50 / 百万 Token
这一价格策略使得处理海量数据(如全文翻译、大规模内容审核)的成本变得微乎其微,极具市场竞争力。
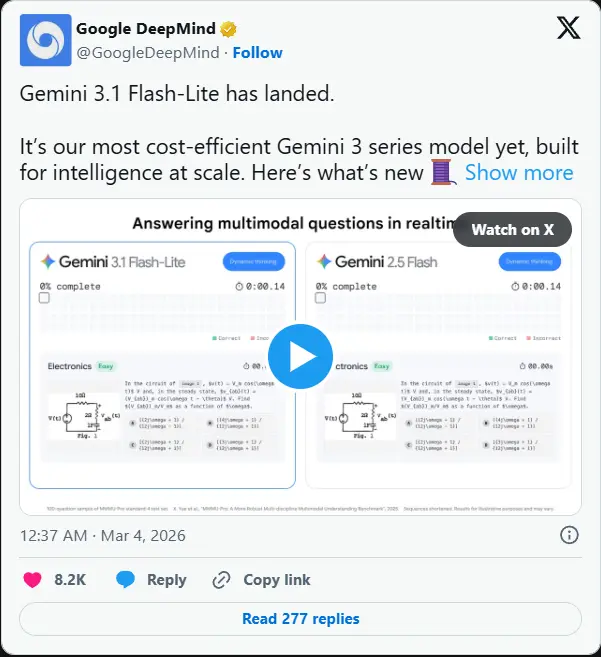
性能表现:小模型,大智慧
尽管定位为“Lite”,Gemini 3.1 Flash-Lite 在多项权威基准测试中却展现了超越前代较大模型的实力:
| 基准测试 | Gemini 3.1 Flash-Lite | 表现评价 |
|---|---|---|
| Arena.ai Elo 评分 | 1432 | 在同层级模型中名列前茅 |
| GPQA Diamond (专业推理) | 86.9% | 展现惊人的高阶推理能力 |
| MMMU Pro (多模态理解) | 76.8% | 视觉与文本结合理解能力卓越 |
关键发现:其在 GPQA Diamond 和 MMMU Pro 上的得分甚至超越了前代较大的 Gemini 2.5 Flash 模型,证明了谷歌在模型压缩与蒸馏技术上的重大突破。
独特功能:可控推理深度
Gemini 3.1 Flash-Lite 引入了一个极具灵活性的功能——思考级别控制 (Thinking Levels):
- 灵活切换:开发者可以根据任务需求,动态调整模型的“思考深度”。
- 场景适配:
- 浅层思考:适用于高频、简单的任务(如即时翻译、基础分类),追求极致速度。
- 深层思考:适用于复杂逻辑推理、代码生成或数据分析,牺牲少量速度换取更高精度。
这种自适应能力让单一模型能同时胜任从“即时通讯”到“复杂分析”的多种角色。
早期应用反馈
来自 Latitude、Cartwheel 和 Whering 等公司的早期测试者表示:
- 精度惊喜:Flash-Lite 在处理复杂输入时,展现出了通常在更高级别(且更昂贵)模型中才能看到的精度。
- 指令遵循:在长上下文和多步指令遵循上表现出色,一致性极高。
- 成本效益:对于需要处理数百万级请求的业务,成本节省达到了数量级。
适用场景
凭借其极速、低价且智能的特性,Gemini 3.1 Flash-Lite 是以下场景的完美选择:
- 实时交互应用:聊天机器人、虚拟助手、实时字幕生成。
- 大规模内容处理:多语言翻译、内容审核、情感分析。
- 复杂数据洞察:财务报表分析、法律文档摘要、科学数据解读。
- 动态内容生成:个性化营销文案、UI 界面代码生成、游戏 NPC 对话。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...