扩散语言模型(Diffusion Language Models, DLMs)因其支持并行生成文本的能力,被视为自回归模型(AR)之外的一条重要技术路径。然而,其高昂的推理延迟严重制约了实际应用,尤其是在处理长文本(如 64K tokens)时,传统注意力机制带来的二次方计算复杂度(O(N²))成为主要瓶颈。
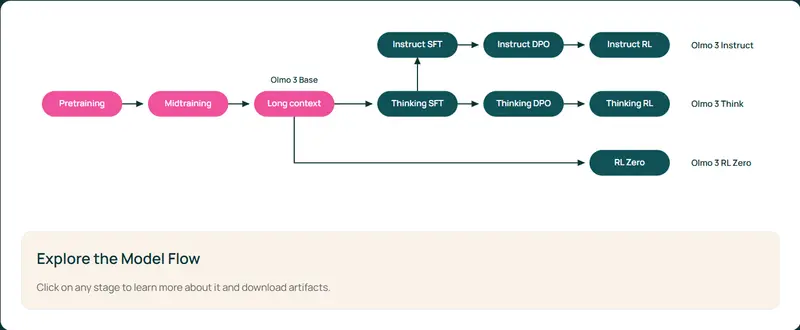
尽管“稀疏注意力”已被广泛用于加速自回归模型,但直接将其迁移到 DLMs 中往往导致生成质量显著下降。这是因为 DLMs 的注意力行为具有独特规律,无法适配 AR 模型中常见的固定稀疏模式。
为此,新加坡国立大学与香港理工大学的研究团队提出 SparseD ——一种专为扩散语言模型设计的新型稀疏注意力方法。它基于对 DLMs 注意力动态的深入观察,通过头特异性预计算 + 早期全注意力保护 + 稀疏模式重用三大策略,在几乎无损质量的前提下,实现高达 1.50 倍的端到端加速(64K 上下文,1024 步去噪),显著优于 FlashAttention。

为什么不能照搬 AR 的稀疏注意力?
在自回归模型(如 Llama、Qwen)中,稀疏注意力通常依赖于固定的局部窗口或全局锚点(如滑动窗口、稀疏因子分解),这些模式基于因果结构预先定义,稳定且易于硬件优化。
但在 DLMs 中,研究人员发现注意力行为呈现三种关键特性:
| 特性 | 含义 | 对稀疏化的启示 |
|---|---|---|
| 头特异性(Head-Specific) | 不同注意力头关注不同 token 关系,模式各异 | 需为每个头定制稀疏结构 |
| 时间一致性(Temporal Consistency) | 同一头在不同去噪步骤中的注意力分布高度相似 | 可跨步长复用稀疏模式 |
| 早期步骤敏感性 | 初始去噪阶段决定整体语义走向,容错率低 | 早期不宜使用稀疏近似 |
这表明:通用、静态的稀疏模式不适用于 DLMs,而每步重新计算稀疏连接又会抵消性能收益。
SparseD 的核心设计思想
SparseD 围绕上述三大发现构建,目标是:在最小化计算的同时,保留最关键的上下文交互。
1. 头特异性稀疏模式预计算
- 在推理开始前,运行一次完整的注意力计算;
- 分析各注意力头的重要性分布,提取出最具影响力的 query-key 对;
- 构建一个按头划分的稀疏连接图,仅保留 top-k 百分比的关键连接。
✅ 这一步确保了稀疏结构能捕捉每个头的独特语义偏好。
2. 早期全注意力 + 后期稀疏切换
- 在前若干个关键去噪步骤(如前 10%)中,使用完整注意力;
- 待语义骨架建立后,切换至预计算的稀疏模式进行后续去噪。
✅ 该策略保护了生成初期的信息完整性,避免因过早剪枝导致语义漂移。
3. 跨步骤稀疏模式重用
- 预计算的稀疏模式在整个去噪序列中重复使用;
- 避免每一步都重新评估哪些连接重要,极大降低控制开销。
✅ 结合时间一致性假设,这一做法既高效又合理。
4. 块级稀疏选择(Block-wise Sparsity)
- 所有稀疏操作以 memory block 为单位进行(如 64×64 token 块);
- 提高 GPU 缓存利用率,便于与 FlashAttention 等高效内核集成。
性能表现:接近无损的加速效果
实验在多个主流 DLM 架构上验证了 SparseD 的有效性,在 64K 上下文长度、1024 去噪步的标准测试条件下取得如下成果:
| 指标 | SparseD 表现 |
|---|---|
| 推理速度提升 | 相比 FlashAttention 最高达 1.50 倍 |
| 生成质量损失 | 平均准确率下降仅 0.04%,可视为无损 |
| 显存占用 | 显著低于全注意力基线,支持更长序列 |
| 工具调用成功率(类比代理任务) | 在 CC-Bench 类任务中失败率增加 <1%,稳定性高 |
尤其值得注意的是,在长文本理解与多跳推理任务中,SparseD 保持了与原始模型几乎一致的功能完成率,而缓存类优化方法(如 dKV-Cache、Fast-dLLM)则在极端长度下出现明显性能衰减。
应用场景:让 DLMs 更具实用性
SparseD 的出现,使 DLMs 在以下高需求场景中更具落地潜力:
✅ 长文档生成
- 自动生成报告、小说章节、法律文书等超长内容;
- 支持整本书级别的连贯创作。
✅ 多轮代码生成与修复
- 在大型项目上下文中进行函数补全或 bug 修复;
- 结合 IDE 插件实现实时辅助。
✅ 推理密集型任务
- 数学证明、逻辑推导、规划类问题求解;
- 保证早期思维链完整性的前提下加速收敛。
✅ 边缘端部署探索
- 通过降低 FLOPs 和显存压力,为移动端或嵌入式设备部署提供可能。
与当前主流评估体系的关联:为何可信?
SparseD 所强调的“生成质量优先”理念,与当前领先的模型评测范式高度一致。例如,智谱发布的 CC-Bench(Hugging Face 数据集)就采用多轮人机协作方式,在隔离环境中评估模型在真实编程任务中的功能完成率、工具调用成功率和 token 效率。
类似地,SparseD 的评估不仅关注 BLEU 或 ROUGE 分数,更注重:
- 是否改变了最终输出的正确性?
- 是否影响了关键决策路径?
- 是否增加了调试成本?
这种以“结果可用性”为核心的评价标准,正逐渐成为衡量 AI 模型实用性的黄金准则。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











