
在一些对响应速度极为敏感的应用场景中,例如对话式 AI 或人机协同的工作流系统,语言模型的推理延迟不仅影响效率,更直接影响用户体验。
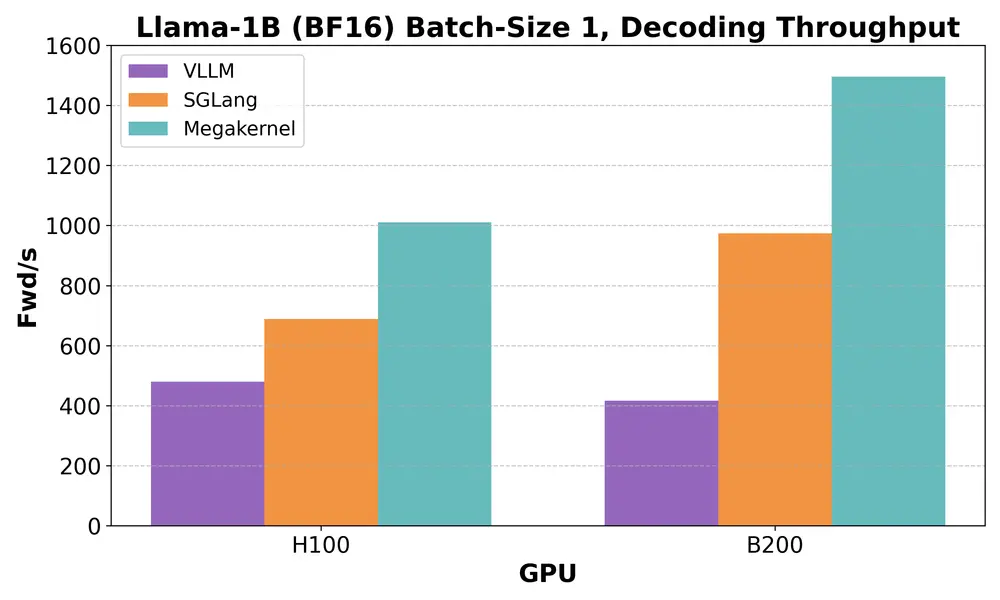
以 Llama-3.2-1B 这类小型开源模型为例,在单序列生成任务中,性能瓶颈并不在于计算能力,而在于内存带宽利用率。即便是在 NVIDIA H100 这样的顶级 GPU 上,主流推理引擎(如 vLLM 和 SGLang)也仅能利用不到 50% 的可用带宽。
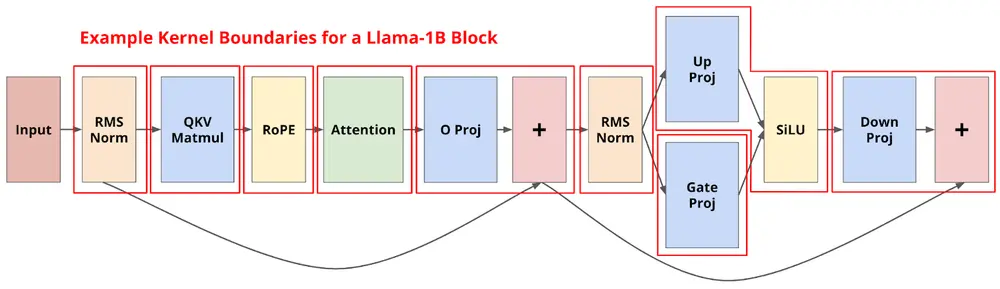
为什么?因为现有系统将前向传播拆分成上百个独立 CUDA kernel,每个 kernel 执行极小的操作(如 RMS Norm、注意力机制、MLP 等),中间存在大量上下文切换与等待时间。GPU 很多时候不是在“干活”,而是在“等着干活”。
关键突破:将整个模型融合为一个“大内核”(Megakernel)
斯坦福 Hazy Research 团队提出了一种全新的优化思路——将整个 Llama-1B 的前向传播整合成一个单一的 Megakernel。通过这种方式,彻底消除传统推理流程中的多个内核边界,从而大幅提高内存带宽利用率。
在 H100 上,该方法实现了惊人的性能提升:
- 内存带宽利用率从 50% 提升至 78%
- 推理速度比现有系统快 1.5 倍以上
- 在 bfloat16 格式下,达到了目前 Llama-1B 中最低延迟的前向传播
技术挑战与解决方案
挑战一:小型内核导致的“内存流水线气泡”
现代 GPU 的执行模型是基于一个个独立内核启动的。然而,在低延迟任务中,这种模式带来了三个主要问题:
- 严格的串行启动机制:前一个内核必须完全执行完毕,下一个才能开始。GPU 的部分硬件资源在此期间处于闲置状态。
- 内核启动与收尾成本高:即使使用 CUDA Graph 等机制,这些开销仍难以完全隐藏。
- 数据加载无法提前准备:虽然 NVIDIA 提供了 PDL(Programmatic Dependent Launch)等同步机制,但其粒度较粗,无法充分利用并发性。
这些问题共同构成了所谓的“内存流水线气泡”,浪费了大量潜在的内存带宽。
解决方案:打造 Megakernel 的三大关键点
1. 融合数百操作:构建统一指令集与解释器
要将整个模型压缩进一个内核中,首先需要解决如何组织和调度其中的上百个操作。
团队采用了一种类似“GPU 内部解释器”的方式,定义了一个通用的指令集,包括:
- RMS 归一化 + QKV + RoPE
- 注意力计算
- Attention Reduce(用于长序列)
- O 投影 + 残差连接
- MLP 相关操作
- 最终输出层处理
每个指令都基于统一的 CUDA 模板实现,并由 Python 层预先调度。这一设计使得同一个 Megakernel 可被复用数百次,极大提升了执行效率。
2. 共享内存管理:分页共享机制减少内存气泡
由于所有权重都需要从全局内存加载到 SM 的共享内存中,如何高效地管理和复用共享内存成为关键。
为此,团队采用了分页共享内存策略:
- 将 H100 上的 213KB 共享内存划分为 13 个 16KiB 页面
- 指令需主动请求并释放页面
- 释出的页面会自动传递给后续指令,以便尽早开始内存加载
这种方法有效减少了因共享内存不足而导致的等待时间,显著提升了内存带宽利用率。
3. 同步机制:自定义计数器系统确保数据一致性
没有了传统内核之间的天然隔离,Megakernel 需要一套新的同步机制来保证指令间的依赖关系。
团队设计了一套基于计数器的同步系统:
- 初始化一组全局计数器数组
- 每个指令完成时递增对应计数器
- 新指令启动前等待所需计数器达到目标值
这一机制特别适用于像 MLP 这样的复杂结构,允许按块处理中间状态,而不是等待全部完成后再开始下一步。
性能表现与分析
在不同硬件平台上,Megakernel 表现出显著优势:
| 平台 | 当前性能(前向传播/秒) | 对比 vLLM | 对比 SGLang |
|---|---|---|---|
| H100 | ~1350 | 快 2.5x | 快 1.5x |
| B200 | ~2000+ | 快 3.5x | 快 1.5x+ |
在 B200 上,每次前向传播耗时已降至 680 微秒以下。尽管尚未达到理论极限(约 3000 次/秒),但已远超现有系统。
进一步分析显示,当前性能受限的主要因素包括:
- 激活值加载与存储延迟(约 250μs)
- 实际计算时间(约 200μs)
- 权重加载(约 30μs)
- 同步与控制开销(约 120μs)
未来仍有优化空间,尤其是在同步机制和激活值处理方面。
Megakernel 的更多可能
本文聚焦于低延迟、单批处理的 LLM 推理优化,但 Megakernel 的潜力远不止于此。它提供了一种全新的 GPU 编程范式,可以更精细地控制执行流程,有望在以下方向带来突破:
- 更高效的训练流水线
- 支持异构计算架构
- 多模态模型推理加速
我们期待看到 Megakernel 架构在未来 AI 工程实践中发挥更大作用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











