
近日,英伟达(NVIDIA)联合麻省理工学院(MIT)与香港大学的研究团队,推出了名为 Fast-dLLM 的新型框架,解决当前扩散模型(Diffusion-based LLMs)在推理效率和生成质量方面的瓶颈问题。
该研究成果为扩散模型的实际部署带来了新的可能,使其在语言生成任务中具备了更强的竞争力。
扩散模型 vs 自回归模型:理论优势难落地
扩散模型近年来被视为自回归模型(如 GPT 系列)的有力替代方案。其核心优势在于:
- 使用双向注意力机制(Bidirectional Attention)
- 支持多词元同步生成(Multi-token Generation)
理论上,这些特性应能带来更快的解码速度和更灵活的生成方式。然而,在实际应用中,扩散模型面临两个关键挑战:
- 重复计算注意力状态:每次生成步骤都要重新计算全部上下文的注意力张量,导致计算冗余。
- 词元间依赖易被破坏:多词元并行生成时,语义一致性难以保证,影响最终输出质量。
这些问题限制了扩散模型在实际场景中的广泛应用。
Fast-dLLM:两大创新突破性能瓶颈
为了应对上述挑战,Fast-dLLM 提出了两项关键技术改进:
1. 块状近似 KV 缓存机制(Block-wise Approximate KV Caching)
该机制将输入序列划分为多个“块”(Blocks),并在首次计算时预存每个块的 Key 和 Value 激活值(KV Activations)。后续解码过程中可复用这些缓存数据,大幅减少重复计算。
进一步优化的 DualCache 版本 还引入了对前后缀词元(Prefix & Suffix Tokens)的缓存机制,利用相邻推理步骤之间的高相似性,进一步提升了缓存命中率与推理效率。
2. 置信度感知并行解码策略(Confidence-aware Parallel Decoding)
为了在加速的同时维持生成质量,Fast-dLLM 引入了一种基于置信度的动态解码机制。
具体而言,系统根据设定的置信度阈值(Confidence Threshold),仅对高置信度词元进行并行采样,而对低置信度部分则采用串行处理以确保语义连贯性。这一策略有效缓解了词元间的依赖冲突问题,避免因并行生成而导致的质量下降。
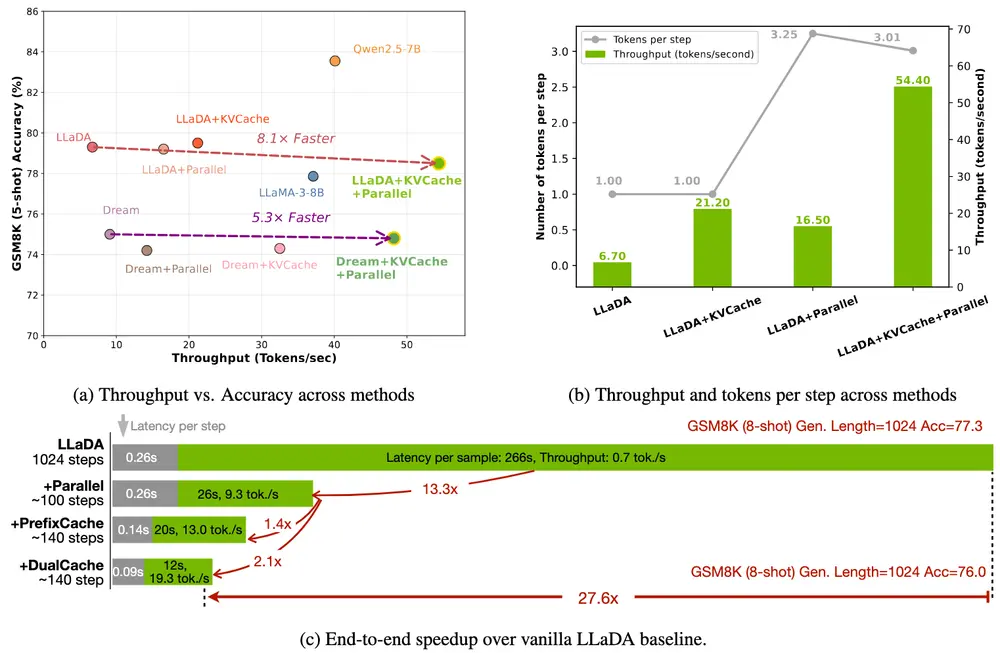
性能测试结果:加速显著,质量损失可控
在多个标准基准测试中,Fast-dLLM 展现出卓越的性能表现:
| 数据集 | 加速倍数 | 准确率(Baseline) | 准确率(Fast-dLLM) |
|---|---|---|---|
| GSM8K | ×27.6 | 75.3% | 76.0% |
| MATH | ×6.5 | 38.8% | 39.3% |
| HumanEval | ×3.2 | 54.3% | 54.3% |
| MBPP | ×7.8 | 基线水平 | 基线水平 |
从测试结果来看,Fast-dLLM 在实现显著加速的同时,准确率仅下降约 1-2 个百分点,表明其在速度与质量之间实现了良好的平衡。
意义与展望:扩散模型迈向实用化的重要一步
Fast-dLLM 的提出标志着扩散模型在语言生成领域迈出了关键一步。它不仅解决了长期存在的推理效率问题,还通过置信度机制保障了生成质量,使得扩散模型在实际应用场景中更具可行性。
未来,这项研究有望推动扩散模型在以下方向的应用拓展:
- 高效问答系统
- 实时文本摘要与翻译
- 多模态生成任务(如图文生成)
- 资源受限设备上的本地部署
随着更多类似工作的推进,扩散模型或将真正成为自回归模型之外的主流选择之一。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











