
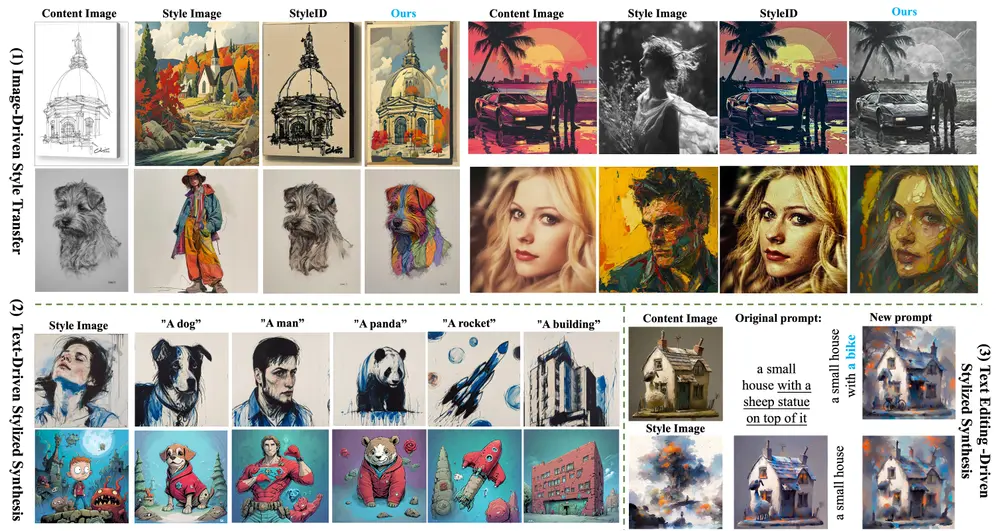
英伟达和延世大学的研究人员推出多模态大语言模型Omni-RGPT,旨在统一图像和视频的区域级理解。Omni-RGPT通过一种新颖的区域表示方法——Token Mark,实现了对图像和视频中特定区域的深入理解。例如,当用户询问图像中某个区域的内容时,Omni-RGPT能够生成详细的描述,如“一只鹿躺在地上,显得很放松”,或者在视频中,能够描述某个区域随时间的变化,如“一个人正向一只考拉靠近,准备进行友好的互动”。

主要功能
- 区域级理解:能够对图像和视频中的特定区域进行详细的描述和问答。
- 多模态融合:整合视觉和文本信息,实现跨模态的理解和生成。
- 视频理解:通过引入辅助任务,支持对视频的稳定区域理解,即使在没有完整跟踪信息的情况下也能准确识别区域。
- 数据集构建:提出了一个大规模的区域级视频指令数据集RegVID300k,包含98k个独特视频和294k个区域级指令样本,用于增强模型的对话能力和区域理解精度。
主要特点
- Token Mark机制:通过预定义的Token Mark集合,将目标区域在视觉特征空间中进行标记,实现了视觉和文本标记之间的直接连接。
- 可扩展性和时间一致性:Token Mark的使用解决了视频序列中区域表示的可扩展性问题,同时确保了跨帧的时间一致性。
- 无需跟踪信息:通过引入辅助任务,Omni-RGPT能够在没有完整跟踪信息的情况下,对视频中的区域进行准确理解。
- 高性能:在图像和视频基准测试中均取得了最先进的结果,特别是在视觉常识推理和区域级理解任务中表现出色。
工作原理
- Token Mark嵌入:给定用户定义的局部区域输入(如框或掩码)和相应的文本提示,Omni-RGPT将Token Mark嵌入到由区域提示定义的空间区域,并将其注入到相应的文本提示中,使模型能够直接推理视觉区域和文本提示之间的对齐关系。
- 辅助任务:为了支持视频理解,引入了一个辅助任务,利用Token Mark的一致性,指导模型在视频中稳定地解释区域,即使在没有跟踪信息的情况下也能保持时间一致性。
- 大规模数据集:通过自动化流程,基于GPT4o生成大规模的区域级视频指令样本,增强了模型的区域描述能力。
具体应用场景
- 图像和视频内容描述:为图像和视频中的特定区域生成详细的描述,帮助用户更好地理解内容。例如,在旅游应用中,为用户描述照片中的景点细节。
- 视频问答:回答用户关于视频中特定区域的问题,如“视频中的人在做什么?”或“这个物体是什么?”。
- 内容审核:在视频监控或社交媒体内容审核中,快速识别和描述视频中的关键区域,提高审核效率。
- 教育和培训:在教育视频中,为学生提供对特定区域的详细解释,增强学习体验。
- 智能助手:集成到智能助手中,使其能够理解和描述用户上传的图像和视频内容,提供更丰富的交互体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

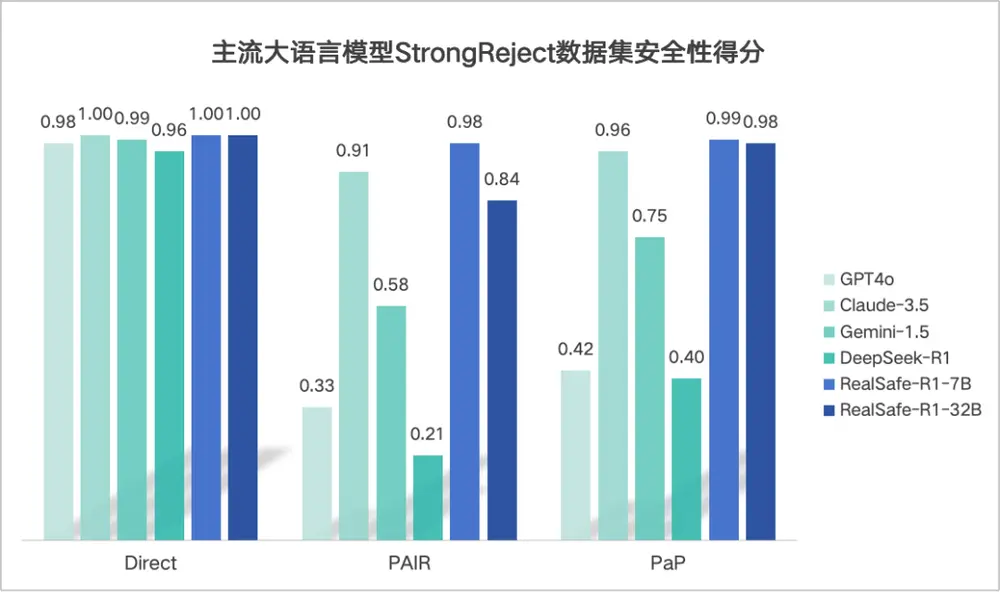

暂无评论...











