
在大语言模型的发展中,尽管在理解和生成类人文本方面取得了显著进展,但在处理复杂推理任务时,尤其是需要多步计算或逻辑分析的任务,这些模型往往表现不佳。传统的思维链(Chain of Thought, CoT)方法虽然通过将问题分解为中间步骤来辅助推理,但它们严重依赖模型的内部推理能力。这种内部依赖性有时会导致错误,尤其是在复杂计算或需要多步推理的情况下。小错误可能会累积,导致结果不如预期精确。因此,开发一种能够验证和调整自身推理的方法显得尤为重要,尤其是在科学分析或竞赛级数学等任务中。
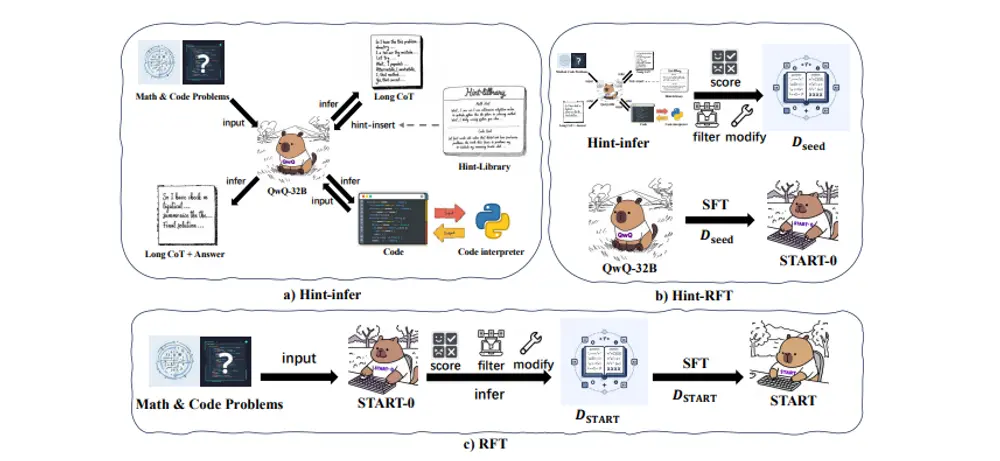
阿里巴巴的研究人员提出了一种名为 START 的新 AI 工具,全称为 Self-Taught Reasoner with Tools(带工具的自学推理器)。与仅依赖内部逻辑不同,START 集成了外部 Python 解释器来辅助推理任务。该模型基于微调版的 QwQ-32B 模型,并采用双重策略来提高其问题解决能力。
START 的核心设计与优势
1. Hint-infer 方法:触发外部工具的使用
START 的核心在于将外部工具集成到推理过程中。通过 Hint-infer 方法,模型被鼓励在推理过程中插入提示,例如“等一下,也许在这里使用 Python 是个好主意”。这些提示通常出现在模型重新考虑其方法时,例如在“或者”或“等一下”等过渡词之后。这使得模型能够通过 Python 代码验证其推理,从而在必要时进行自我纠正。
2. Hint Rejection Sampling Fine-Tuning(Hint-RFT):优化推理能力
在第二阶段,模型通过 Hint-RFT 微调过程进一步优化其推理能力。该过程通过对推理步骤进行评分和过滤,帮助模型更好地决定何时以及如何调用外部工具。优化后的数据集随后用于进一步微调模型,最终形成了现在称为 START 的 QwQ-32B 版本。外部计算的集成有助于最大限度地减少错误,确保模型的推理既连贯又可靠。
实验结果与洞察
研究人员在一系列任务上评估了 START 的性能,包括研究生级科学问题、挑战性数学问题和编程任务。实验结果表明,START 相较于其基础模型表现出显著的改进:
- 在一组博士级科学问题上,模型的准确率达到 63.6%,相较于原始模型有了适度但有意义的提升。
- 在从高中水平到竞赛问题的数学基准测试中,准确率的提升同样令人鼓舞。
- 在编程挑战中,START 的方法使其能够生成和测试代码片段,从而比仅依赖内部推理的模型获得更高的正确率。
这些结果表明,结合外部验证的能力可以带来更好的问题解决效果,尤其是在精度至关重要的任务中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











