
阿里巴巴和北京邮电大学的研究人员推出动态肖像生成框架FantasyTalking,从单张静态肖像图像生成逼真的、可动画化的动态肖像,使其能够根据音频信号进行自然的表情、口型和肢体动作的生成。
- 项目主页:https://fantasy-amap.github.io/fantasy-talking
- GitHub:https://github.com/Fantasy-AMAP/fantasy-talking
例如,给定一张人物的静态照片和一段音频,该技术可以生成一个视频,其中人物在视频中根据音频内容做出自然的表情、口型动作以及轻微的肢体动作,仿佛在真实地讲话一样。生成的视频不仅口型与音频同步,人物的表情和动作也显得自然流畅,背景也会有相应的动态变化,整体效果非常逼真。
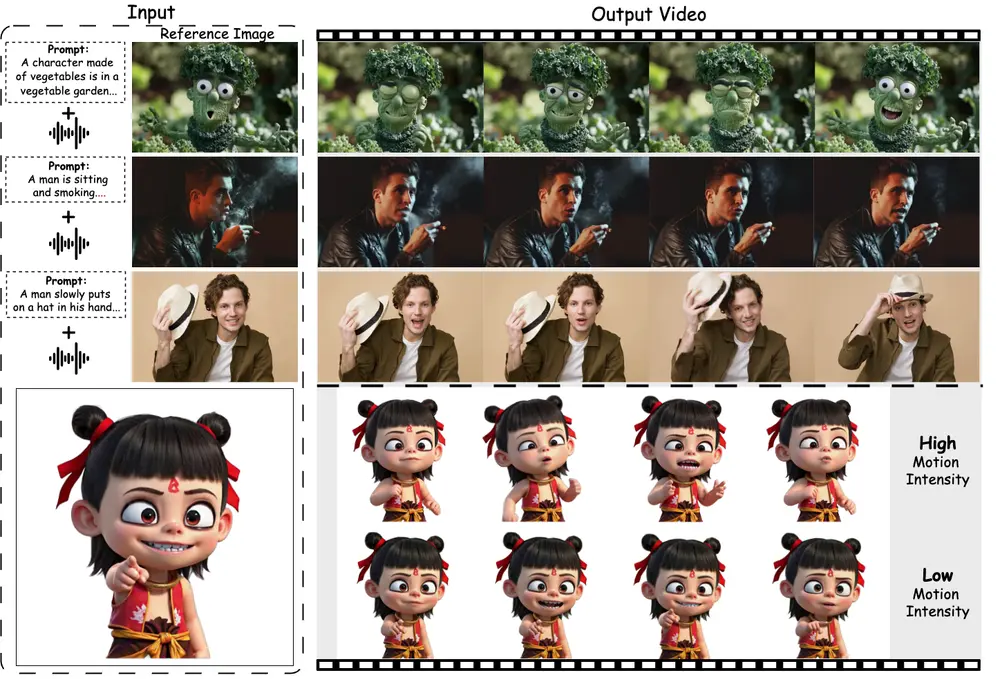
此项目是基于Wan2.1模型,目前ComfyUI-Wan 已支持该项目,官方也已经释出模型。
模型下载
| 模型 | 下载链接 | 备注 |
|---|---|---|
| Wan2.1-I2V-14B-720P | Huggingface | ModelScope | 基础模型 |
| Wav2Vec | Huggingface | ModelScope | 音频编码器 |
| FantasyTalking model | Huggingface | ModelScope | 我们的音频条件权重 |
主要功能
- 逼真的动态肖像生成:从单张静态肖像生成高质量、高保真的动态视频。
- 音频驱动的动画控制:通过音频信号控制肖像的表情、口型和肢体动作,实现自然的动画效果。
- 运动强度调节:用户可以调节人物表情和肢体动作的强度,生成不同风格的动画。
- 身份特征保持:在生成的视频中保持人物的身份特征,避免面部特征的失真。
主要特点
- 双阶段音频-视觉对齐策略:通过剪辑级和帧级的训练,确保全局运动和口型动作的精确对齐。
- 面部聚焦的身份保持模块:专注于面部特征的建模,有效保持人物的身份特征。
- 运动强度调节模块:允许用户控制人物表情和肢体动作的强度,实现多样化的动画效果。
- 连贯的全局运动生成:不仅生成逼真的口型动作,还能生成自然的面部表情和肢体动作,使整个场景更加自然。
工作原理
- 双阶段音频-视觉对齐:
- 剪辑级对齐:通过计算整个剪辑的音频和视频特征之间的3D全注意力相关性,建立全局的音频-视觉依赖关系。
- 帧级对齐:专注于口型动作的精确对齐,通过使用唇部掩码(lip-tracing mask)来确保口型与音频信号的精确同步。
- 身份保持:通过裁剪参考图像中的面部区域,并使用ArcFace提取面部特征,然后通过Q-Former进行对齐,确保生成的视频中人物的身份特征保持一致。
- 运动强度调节:通过提取面部表情和肢体动作的关键点序列的方差,计算出运动强度系数,并通过运动强度调节网络来控制生成视频中人物的表情和肢体动作的强度。
应用场景
- 虚拟现实和增强现实:为虚拟角色赋予逼真的动态表情和动作,提升沉浸感。
- 影视制作:快速生成逼真的角色动画,减少动画制作的时间和成本。
- 游戏开发:创建具有自然表情和动作的虚拟角色,提升游戏的交互性和真实感。
- 在线教育和会议:生成逼真的虚拟教师或演讲者,提供更加生动的教学或会议体验。
- 社交媒体和娱乐:用户可以将自己的照片制作成动态视频,分享到社交媒体上,增加趣味性和吸引力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











