
自回归模型在视觉生成领域表现出色,但其逐个预测token的顺序过程导致了推理速度较慢。为了解决这一问题,香港大学、字节跳动和北京大学的研究人员提出了一种简单而有效的并行自回归视觉生成方法——PAR(Parallelized Autoregressive Visual Generation)。该方法显著提高了生成效率,同时保留了自回归建模的优势。PAR通过并行生成视觉标记来加速图像和视频的生成过程,同时确保生成质量。
例如,在使用PAR模型进行图像生成时,给定一个类别标签,如“森林”,模型可以快速生成与该标签相关的高质量图像。在视频生成方面,PAR能够根据文本提示或类别标签,生成一系列连贯的视频帧,例如生成一个描述“小狗在草地上奔跑”的视频。

主要功能
- 图像和视频生成:PAR模型能够根据文本描述或类别标签生成图像和视频。
- 并行生成:通过识别和分组弱依赖的视觉标记,PAR能够在不同空间区域并行生成标记,减少推理步骤,提高生成速度。
关键见解
PAR的核心思想是基于视觉token之间的依赖关系来优化生成过程:
- 弱依赖的远距离token可以并行生成:这些token之间的依赖性较弱,因此可以在同一时间步中并行生成,不会影响整体一致性。
- 强依赖的相邻token保持顺序生成:由于相邻token之间存在较强的依赖关系,如果尝试并行生成,可能会导致不一致的结果,如图像中的模式中断或细节扭曲。
通过这种策略,PAR能够在不影响生成质量的前提下大幅加速生成过程。
方法概述
PAR的并行生成过程分为两个主要阶段:
- 初始token的顺序生成:首先,模型按顺序生成每个区域的初始token(例如[1,2,3,4]),以建立全局结构。
- 并行生成远距离token:接下来,在不同区域的对齐位置(如5a-5d、6a-6d等)进行并行生成。相同的数字表示在同一时间步中生成的token,字母后缀(a,b,c,d)表示不同的区域。
这种方法允许模型在保持局部连贯性的同时,实现高效的并行化生成。
与传统方法的比较
为了更好地理解PAR的优势,我们可以将其与两种常见的生成策略进行对比:
- 我们的方法:在非局部区域并行生成具有弱依赖关系的token,保留了连贯的模式和局部细节。
- 朴素方法:在局部区域同时生成强依赖的token,可能导致生成不一致和模式中断,例如扭曲的老虎脸和破碎的斑马条纹。
通过这种方式,PAR不仅加快了生成速度,还确保了生成结果的质量。
实验结果
研究人员在多个基准数据集上进行了实验,验证了PAR的有效性:
- ImageNet:在图像生成任务中,PAR实现了3.6倍的加速,且生成质量与传统自回归模型相当。在最小质量下降的情况下,PAR甚至可以实现高达9.5倍的加速。
- UCF-101:在视频生成任务中,PAR同样表现优异,能够生成高质量的视频帧序列,分辨率为128×128。
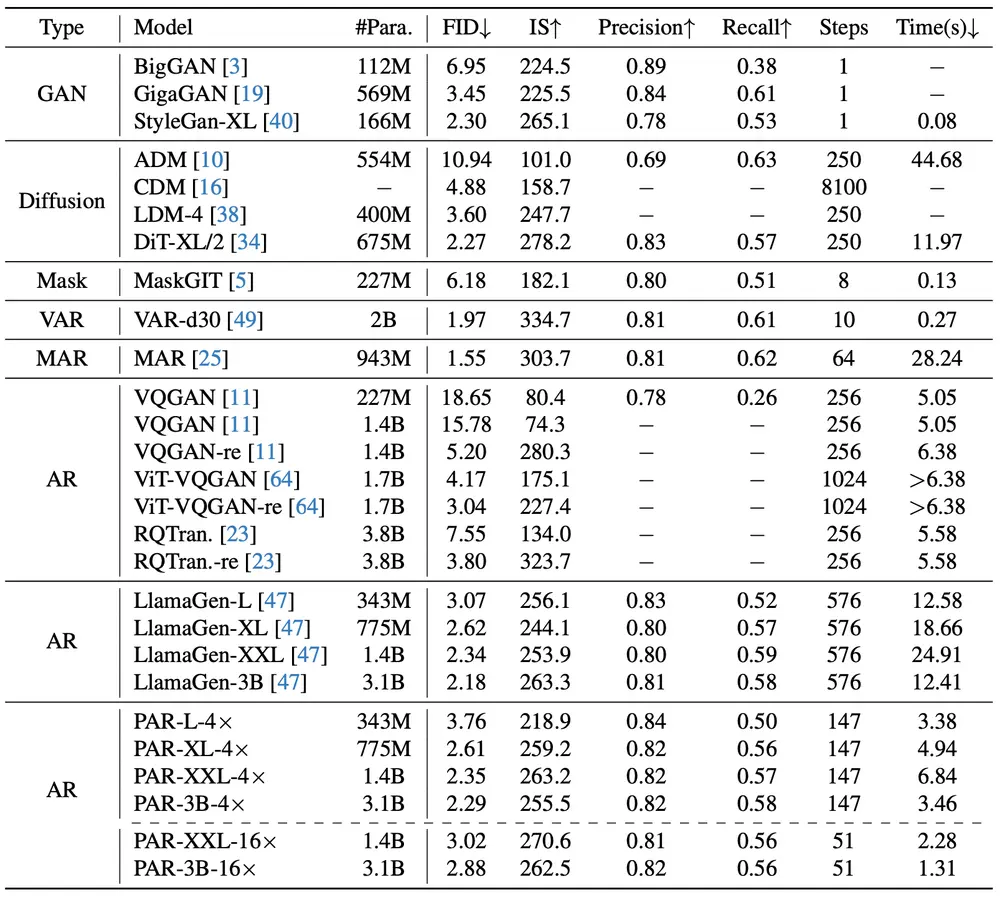
定性和定量分析
- 定性结果:PAR生成的图像和视频在视觉上与传统自回归模型相当,但在生成时间上有了显著的提升。例如,PAR-4×将生成时间从12.41秒减少到3.46秒,而PAR-16×更是缩短至1.31秒(每张图像)。所有测试均在单个A100 GPU上进行,批量大小为1。
- 定量结果:在ImageNet 256×256基准上的类别条件图像生成任务中,PAR-4×和PAR-16×分别展示了出色的性能,证明了其在不同生成速度下的稳定性和高质量。
更多可视化
为了进一步展示PAR的生成能力,研究人员提供了更多的可视化结果,包括:
- PAR-4×:在不同ImageNet类别中的额外图像生成结果,展示了其在多种场景下的适用性。
- PAR-16×:同样在不同ImageNet类别中生成的图像,进一步验证了其在高加速模式下的表现。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











