
来自上海大学、腾讯优图实验室、上海交通大学和复旦大学的研究团队推出首个零样本多模态高保真3D人体纹理生成模型TexDreamer,采用高效的纹理适应微调策略,将大型T2I(文生图)模型与语义UV结构相结合,同时保持其原有的泛化能力。通过引入一种新颖的特征转换模块,训练后的模型能够快速地从文本或图像中生成高保真3D人体纹理。
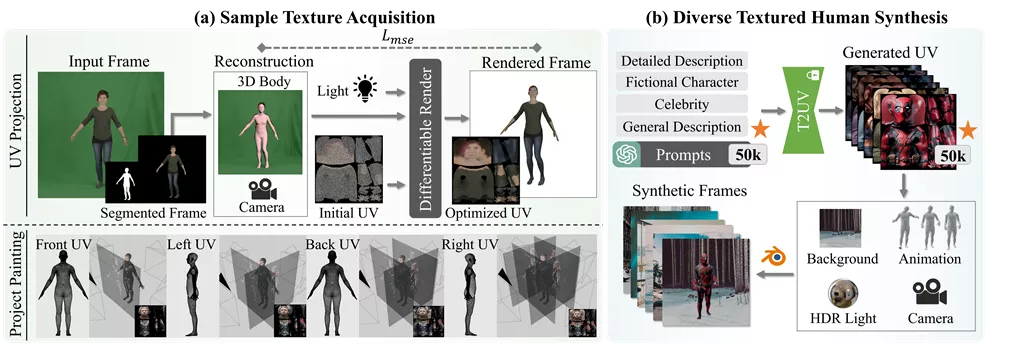
此外,该团队还推出了ArTicuLated humAn textureS (ATLAS),这是目前最大的高分辨率(1024×1024)3D人体纹理数据集,包含5万个附带文本描述的高保真纹理。

想象一下,你是一位游戏设计师或者电影制作人,你需要为你的角色设计各种各样的服装和外观,但是这个过程既费时又费力。TexDreamer能够通过简单的文字描述或者已有的2D图片,快速生成高质量的3D人物纹理,大大简化了这个过程。
主要功能和特点:
- 零样本学习(Zero-Shot): TexDreamer能够在没有任何特定样本的情况下,根据文字描述生成3D人物纹理。这意味着你只需要告诉它你想要的角色是什么样子,它就能创造出相应的纹理。
- 多模态输入: 除了文字,它还能理解2D图片,并根据图片内容生成纹理。
- 高保真度: 生成的纹理质量非常高,细节丰富,能够满足专业领域的要求。
- ATLAS数据集: 为了训练TexDreamer,研究者们创建了一个名为ATLAS的大规模高分辨率3D人物纹理数据集,它包含了50,000个高保真纹理和详细的文字描述。
工作原理:
TexDreamer的核心是一个高效的纹理适应微调策略和一个新颖的特征转换器模块。它首先通过微调大型的文本到图像(T2I)模型,使其能够适应特定的UV(一种3D模型的展开图)结构,同时保留其原始的泛化能力。然后,通过特征转换器模块,训练后的模型能够将图像中的视觉特征转换为文本特征空间,从而生成与输入文本或图像相匹配的3D人物纹理。
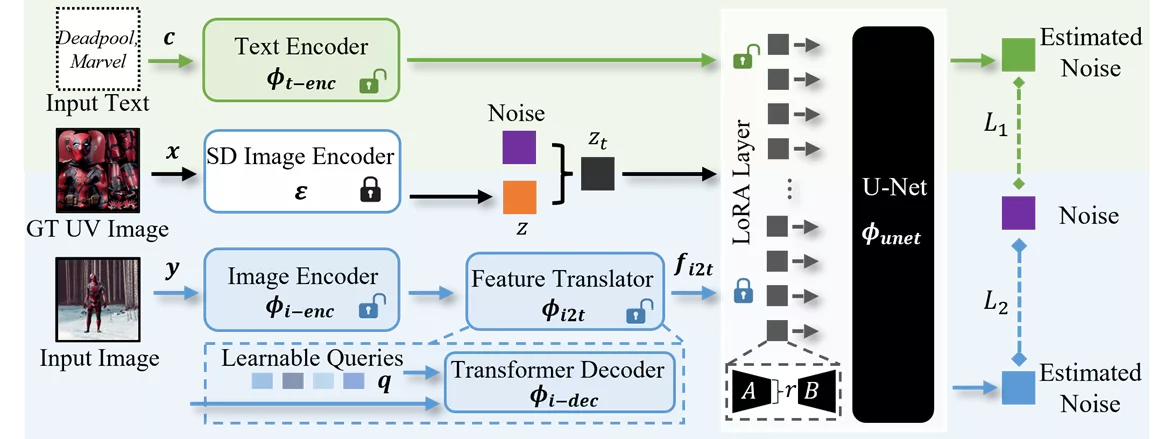
在训练TexDreamer时,将其分为两个阶段:T2UV(绿色)和I2UV(蓝色)。对于T2UV阶段,利用LDM去噪损失L1来优化文本编码器和U-Net。而对于I2UV阶段,构建了一个特征转换器ϕ_i2t,用于将输入图像特征(由ϕ_i−enc编码)转换为T2UV所需的条件特征f_i2t。通过优化ϕ_t−enc和ϕ_i−enc,我们成功训练了I2UV模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











