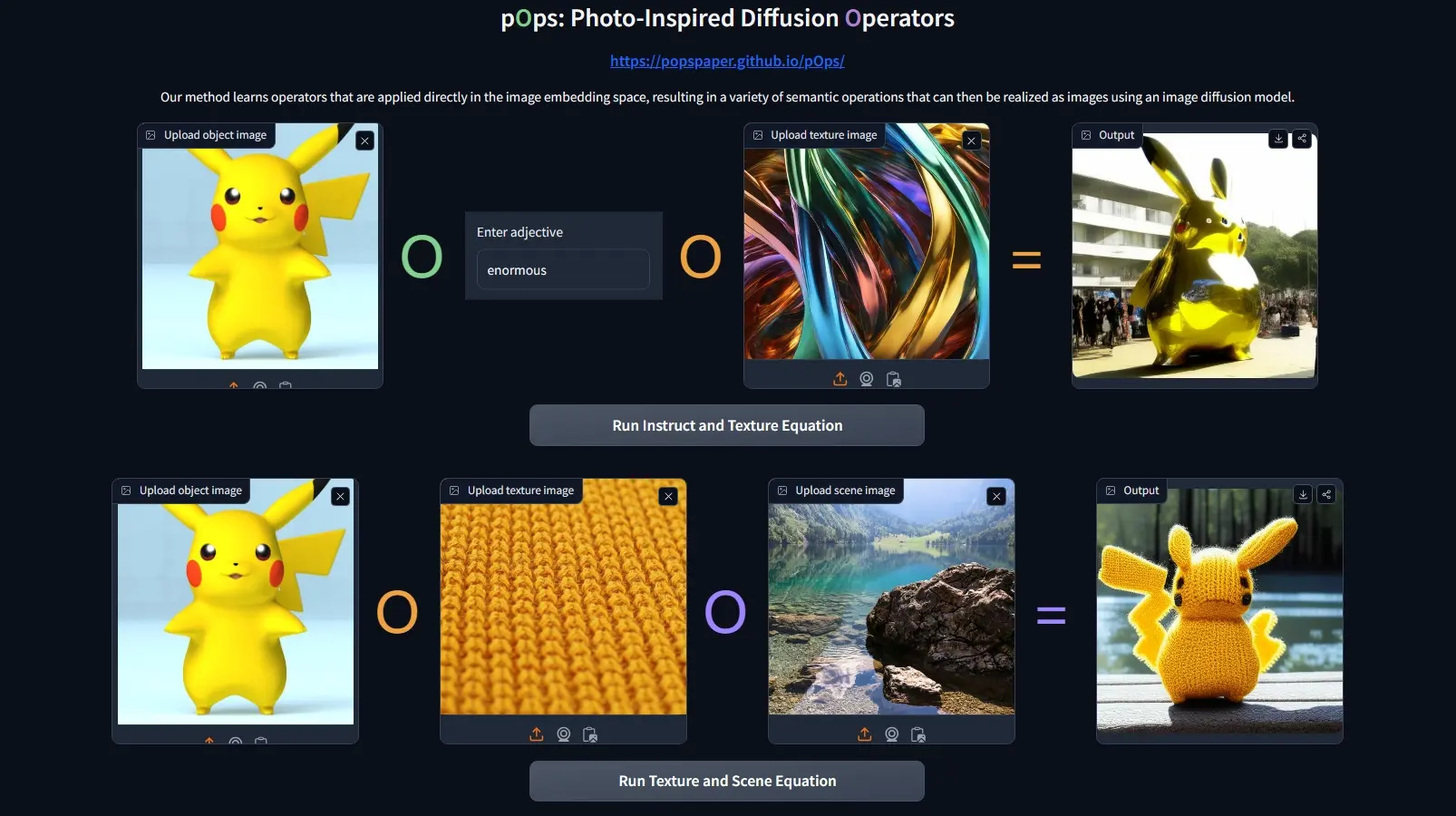
特拉维夫大学和西蒙菲莎大学的研究人员推出图生图新技术pOps(Photo-Inspired Diffusion Operators),它是一种用于生成视觉内容的先进方法。例如,你想要生成一张“在海滩上的小猫”的图片。使用pOps,你可以简单地提供这样的文本描述,然后系统会自动生成一张小猫在海滩上的图片。如果你想要小猫身上有特定的纹理,比如“斑点”,你可以进一步提供这个描述,pOps会相应地在小猫的图像上应用这种纹理。
- 项目主页:https://popspaper.github.io/pOps
- GitHub:https://github.com/pOpsPaper/pOps
- Demo:https://huggingface.co/spaces/pOpsPaper/pOps-space
pOps是一个直接在CLIP图像嵌入上训练特定语义操作符的框架。每个pOps操作符都是基于预训练的扩散先验(Diffusion Prior)模型构建的。尽管扩散先验模型最初是为了映射文本嵌入与图像嵌入而训练的,pOps可以调整以适应新的输入条件,从而形成一个扩散操作符。直接在图像嵌入上工作不仅增强了我们学习语义操作的能力,还允许我们在需要时直接使用文本CLIP损失作为额外的监督。开发人员展示了pOps可以用来学习多种受照片启发的操作符,这些操作符具有不同的语义意义,强调了我们提出的这种方法的语义多样性和潜力。通过这种方式,pOps框架为在视觉内容生成中更精确地捕捉和表达复杂和抽象的文本指令提供了一个强大的工具,进一步推动了跨模态理解和生成的边界。
主题介绍:
pOps技术的核心思想是利用一个已有的图像嵌入空间(CLIP),这个空间能够将图像和文本转换为可以相互理解的格式。通过在这个空间中直接训练特定的“操作符”,我们可以让计算机更好地理解如何根据文本描述生成图像。
主要功能:
- 文本引导的图像生成:用户可以提供文本描述,pOps能够生成与之匹配的图像。
- 语义操作的直接控制:pOps允许对图像嵌入空间中的操作进行更精细的控制,比如合并图像、改变图像的纹理等。
主要特点:
- 直接在图像嵌入空间操作:与传统的文本到图像的生成模型不同,pOps直接在图像的嵌入表示上工作,提高了学习语义操作的能力。
- 多种预训练的操作符:pOps提供了多种预训练的操作符,如合并操作符、纹理操作符、场景操作符等,每种操作符都有独特的语义含义。
工作原理:
- 图像嵌入:首先,将图像通过预训练的CLIP模型转换为嵌入空间中的向量表示。
- 操作符训练:在CLIP的图像嵌入空间上训练特定的操作符,这些操作符能够理解如何根据特定的语义任务改变图像的嵌入表示。
- 图像生成:训练好操作符后,可以将它们应用于图像嵌入,然后使用图像扩散模型将这些嵌入转换回图像。
具体应用场景:
- 艺术创作:艺术家可以提供文本描述,pOps生成与描述相符的艺术作品。
- 游戏设计:设计师可以快速生成游戏场景或角色的概念图。
- 广告和营销:根据广告文案快速生成吸引人的视觉内容。
- 教育和培训:帮助学生通过图像更好地理解抽象概念。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...