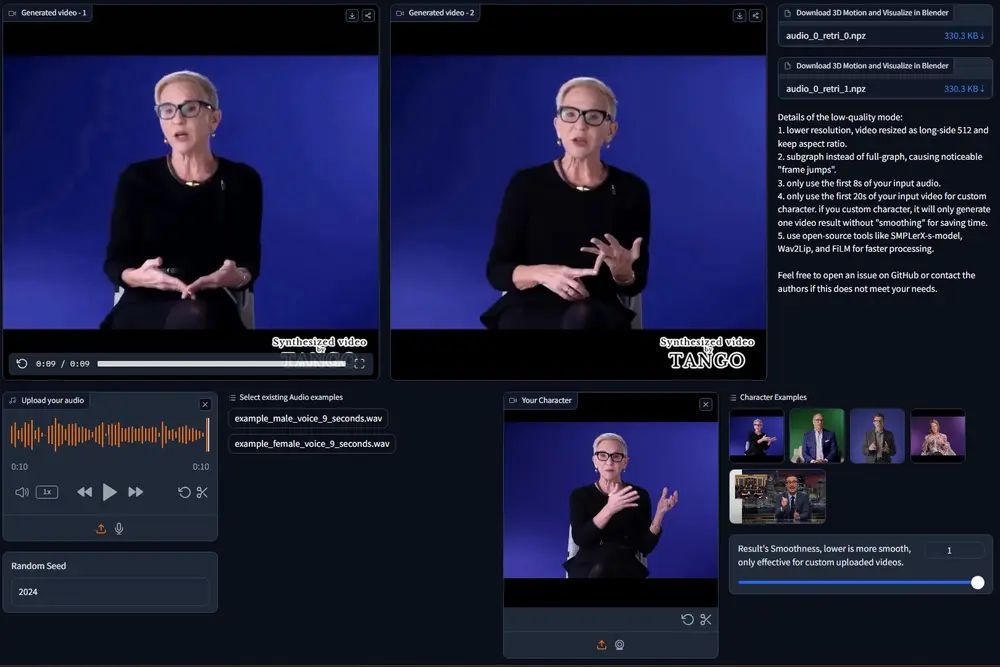
东京大学和CyberAgent 人工智能实验室的研究人员推出了一个用于生成同步语音体态手势视频的框架 TANGO,它可以从一个几分钟长的参考视频(里面有一个说话者的身体动作)和目标语音音频出发,生成高保真的、与语音同步的身体手势视频。简单来说,就是把新的语音和已有的视频动作结合起来,制作出看起来非常自然的视频。
- 项目主页:https://pantomatrix.github.io/TANGO
- GitHub:https://github.com/CyberAgentAILab/TANGO
- Demo:https://huggingface.co/spaces/H-Liu1997/TANGO
TANGO 建立在 Gesture Video Reenactment (GVR) 的基础上,该方法使用有向图结构分割和检索视频片段——将视频帧表示为节点,并将有效过渡表示为边。研究团队解决了 GVR 的两个关键限制:音频-运动错位和 GAN 生成的过渡帧中的视觉伪影。特别是,(i)研究团队提出使用潜在特征距离检索手势以改进跨模态对齐。为了确保潜在特征能够有效建模语音音频和手势运动之间的关系,研究团队实现了一个分层联合嵌入空间(AuMoCLIP);(ii)研究团队引入了基于扩散的模型来生成高质量的过渡帧。研究团队的扩散模型,外观一致插值(ACInterp),建立在 AnimateAnyone 之上,并包括一个参考运动模块和单应背景流,以保持生成视频和参考视频之间的外观一致性。通过将这些组件集成到基于图的检索框架中,TANGO 可靠地生成逼真、音频同步的视频,并优于所有现有的生成和检索方法。
主要功能和特点:
- 高保真视频生成:TANGO能够生成看起来非常真实的视频,视频中的人物动作和语音能够很好地同步。
- 高同步性:它能够确保视频中的身体动作与新的语音音频精确匹配,就像真人在表演一样。
- 改进的过渡帧生成:在视频剪辑的交界处,TANGO能够生成平滑的过渡帧,减少视觉不连贯的现象。
工作原理:
TANGO的工作原理可以分为几个步骤:
- 建立动作图:首先,它将参考视频分割成小块,每一块包含几帧视频和相应的音频。这些小块被看作是动作图中的节点,它们之间的合理过渡则形成动作图的边。
- 语音驱动的手势检索:然后,TANGO会分析目标语音音频,通过一个特殊的嵌入空间(AuMoCLIP)来检索与语音最匹配的手势动作视频块。
- 过渡帧生成:如果动作图的边不足以覆盖整个语音,TANGO会使用一个基于扩散模型的插值网络(ACInterp)来生成中间的过渡帧,确保视频的连贯性。
具体应用场景:
- 新闻广播:可以快速生成新闻主播播报新闻时的自然手势动作,提高制作效率。
- 虚拟YouTube内容创作:为虚拟角色生成与台词同步的手势动作,使得虚拟直播或者视频内容更加生动。
- 电影和电视剧制作:在不需要真人表演的情况下,快速生成对话场景中的手势动作,节省拍摄成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











