
罗切斯特大学和智象未来的研究人员推出新型视频去噪框架Ouroboros-Diffusion,旨在提高无调优(tuning-free)长视频生成中的结构和内容(主体)一致性。该框架通过引入新的潜在采样技术和主体感知跨帧注意力(SACFA)机制,以及自回归引导技术,显著提升了生成视频的主体一致性、运动平滑性和时间一致性。
例如,使用Ouroboros-Diffusion生成一个长视频,其中包含一个宇航员在不同场景中骑行(如骑马、骑龙、骑摩托车)。传统的FIFO-Diffusion方法可能会在视频中产生内容不一致的问题,如宇航员的外观在不同帧中变化显著。而Ouroboros-Diffusion能够生成主体一致、运动平滑且时间连贯的视频,即使在多场景切换时也能保持宇航员的外观和动作的一致性。
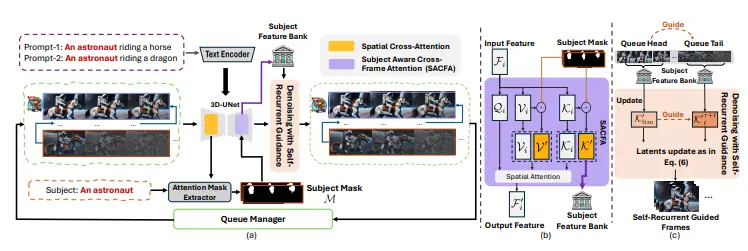
主要功能
- 长视频生成:能够生成任意长度的视频,而不需要大量的训练数据或微调。
- 内容一致性:提高视频中主体和背景的一致性,减少时间上的闪烁和不连贯。
- 运动平滑性:确保视频中的运动更加平滑,减少抖动。
主要特点
- 结构一致性增强:通过在队列尾部引入新的潜在采样技术,确保帧之间的平滑过渡。
- 主体感知跨帧注意力(SACFA):通过跨帧的主体对齐,增强短片段内主体的一致性。
- 自回归引导:利用队列头部的所有先前干净帧的信息来指导队列尾部的噪声帧的去噪,促进丰富的全局信息交互。
- 无需调优:基于预训练的视频扩散模型,无需额外的训练或微调即可生成长视频。
工作原理
- 队列管理:维持一个视频帧的队列,队列中的帧具有逐渐增加的噪声水平。在每个去噪步骤中,从队列头部移除一个完全去噪的帧,并在队列尾部加入一个新的噪声潜在变量。
- 一致的尾部潜在采样:在队列尾部采样新的潜在变量时,利用倒数第二个潜在变量的低频分量作为结构指导,结合随机噪声的高频分量,生成新的尾部潜在变量。这确保了视频的整体结构一致性,同时引入必要的视频动态。
- 主体感知跨帧注意力(SACFA):通过扩展空间自注意力层,引入多个帧的主体上下文,增强帧之间的视觉对齐。SACFA利用分割的主体区域从交叉注意力图中提取每个帧的主体标记,这些标记作为辅助上下文存储在主体特征库中。
- 自回归引导:利用队列头部的长期记忆来指导队列尾部的去噪过程,通过主体感知梯度优化潜在变量,增强长距离主体一致性。
具体应用场景
- 视频内容创作:为视频创作者提供长视频生成工具,能够根据文本提示生成具有高度一致性和平滑运动的视频内容。
- 虚拟现实和增强现实:在VR和AR应用中,根据虚拟环境的描述生成连贯的视频内容,增强用户体验。
- 游戏开发:在游戏开发中,根据游戏场景和角色描述生成连贯的视频动画,提高游戏的视觉效果。
- 教育和培训:生成教育视频,根据教学内容生成连贯的动画,帮助学生更好地理解和记忆知识。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











