
来自北卡罗来纳大学教堂山分校和 Meta AI的研究人员推出视频字幕生成模型Video ReCap,它能够为长达数小时的视频生成多层次的字幕。
这个模型的设计受到了人类行为层次结构的启发,人类行为通常可以分为几个层次:最基本的原子动作(比如拿起一个物体),这些动作组合成更复杂的活动步骤(比如准备食物),而这些步骤又服务于一个更大的目标(比如完成一顿晚餐)。
在Video ReCap模型中,这种层次结构被用来处理视频内容。模型首先识别视频中的原子动作(例如,一个人拿起勺子),然后理解这些动作如何组合成更长时间的活动(例如,一个人在厨房准备食物),最后,模型能够概括整个视频的长期目标或意图(例如,一个人在准备晚餐)。
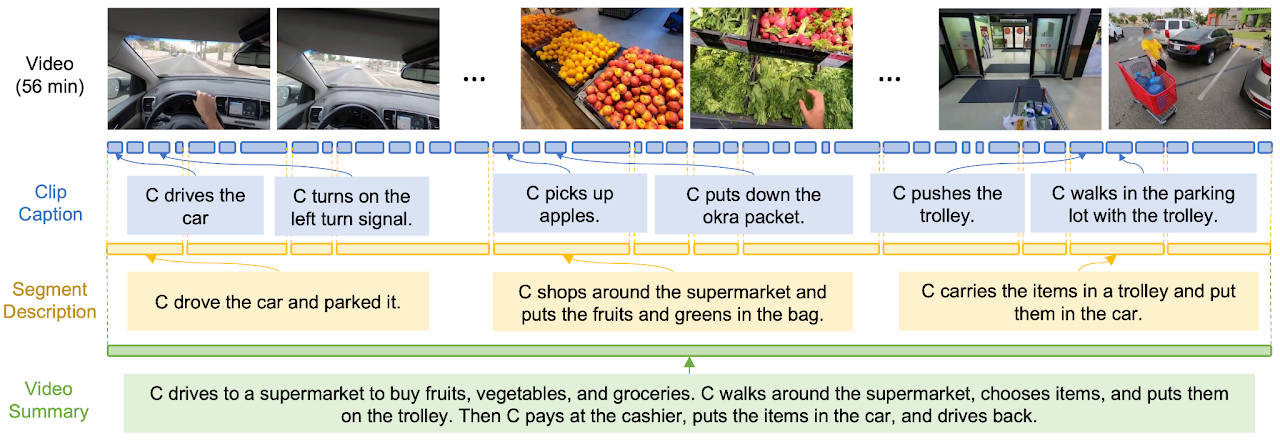
这种多层次的字幕生成能力使得Video ReCap能够处理不同长度的视频,从几秒钟的短视频到长达数小时的长视频。对于短视频,模型可能会生成描述单个动作的字幕;对于长视频,模型则能够提供整个视频的总结性描述。这样的设计使得Video ReCap在理解复杂视频内容方面具有强大的能力,能够为视频提供更丰富、更深入的信息。
主要功能:
- 生成多层次的视频字幕,包括短片段字幕、中等长度的视频片段描述和长视频总结。
- 处理不同长度的视频输入,从几秒到数小时。
- 利用课程学习策略逐步学习视频的层次结构。
主要特点:
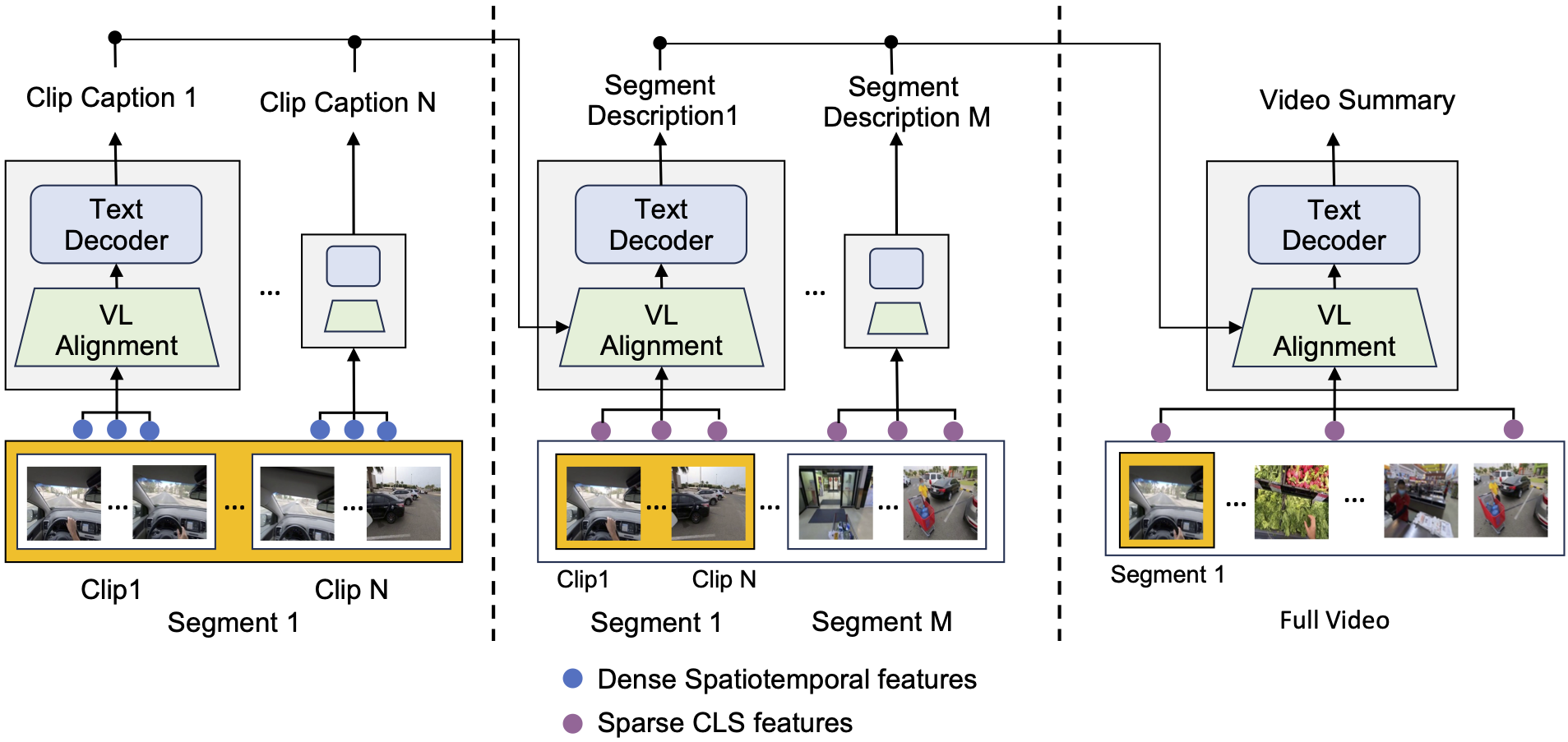
- 递归视频-语言架构: Video ReCap采用递归设计,能够从低层次的字幕生成到高层次的字幕,有效利用不同视频层次之间的协同效应。
- 课程学习策略: 模型从描述原子动作的片段字幕开始训练,然后逐步过渡到中等长度的视频片段描述,最后生成长视频总结。
- 利用大型语言模型(LLMs)生成伪字幕数据: 为了解决手动标注数据稀缺的问题,模型使用LLMs生成伪字幕数据,作为额外的训练样本。
工作原理:
- 视频编码器: 使用预训练的视频编码器(如TimeSformer)提取视频特征。
- 视频-语言对齐模块: 使用预训练的语言模型(如DistilBERT)将视频特征和文本特征映射到联合特征空间,以便后续的文本解码器处理。
- 递归文本解码器: 使用预训练的语言模型(如GPT2)作为文本解码器,根据视频-语言对齐模块的输出生成字幕。在生成高层次字幕时,会使用之前层次生成的字幕作为输入。
具体应用场景:
- 视频内容分析: Video ReCap可以用于分析和理解长时间视频内容,如监控视频、教育视频或纪录片。
- 视频字幕生成: 自动生成视频字幕,帮助听障人士理解视频内容,或为视频制作提供字幕。
- 视频问答系统: 结合视频字幕,Video ReCap可以用于构建视频问答系统,如EgoSchema数据集上的应用,提高视频问答的准确性。
Video ReCap通过其递归架构和课程学习策略,能够有效地处理和理解长时间视频内容,并在多个层次上生成有意义的字幕,这对于视频内容的分析和理解具有重要意义。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











